背景
我們知道,如果在Kubernetes中支持GPU設備調度,需要做如下的工作:
-
節點上安裝nvidia驅動
-
節點上安裝nvidia-docker
-
集群部署gpu device plugin,用於為調度到該節點的pod分配GPU設備。
除此之外,如果你需要監控集群GPU資源使用情況,你可能還需要安裝DCCM exporter結合Prometheus輸出GPU資源監控信息。
要安裝和管理這麼多的組件,對於運維人員來說壓力不小。基於此,NVIDIA開源了一款叫NVIDIA GPU Operator的工具,該工具基於Operator Framework實現,用於自動化管理上面我們提到的這些組件。
NVIDIA GPU Operator有以下的組件構成:
-
安裝nvidia driver的組件
-
安裝nvidia container toolkit的組件
-
安裝nvidia devcie plugin的組件
-
安裝nvidia dcgm exporter組件
-
安裝gpu feature discovery組件
本系列文章不打算一上來就開始講NVIDIA GPU Operator,而是先把各個組件的安裝詳細的分析一下,然後手動安裝這些組件,最後再來分析NVIDIA GPU Operator就比較簡單了。
在本篇文章中,我們將詳細介紹NVIDIA GPU Operator安裝NVIDIA驅動的原理——基於容器安裝NVIDIA驅動。
基於容器安裝NVIDIA GPU驅動
大多數時候,運維人員都是直接將NVIDIA驅動直接安裝在GPU節點上,但是這會有如下的一些缺點:
-
驅動程序安裝容易出錯。
-
驅動的安裝方式與操作系統類型相關,不同的操作系統安裝驅動不同。
-
不可移植性。
-
難以大規模部署或在容器平臺上部署(例如:Kubernetes、Openshift等)。
基於此,NVIDIA官方提供了一種基於容器安裝NVIDIA驅動的方式,而且NVIDIA GPU Operator安裝nvidia驅動也是採用的這種方式。基於容器安裝NVIDIA驅動有如下的一些優點:
-
速度快(一般只要幾秒就能安裝完成)。
-
安全性(安全啟動,受信任啟動,內核鎖定)。
-
便攜性(安裝腳本被打包成鏡像,便於分發和移植)。
-
易於使用(安裝/卸載驅動=啟動/停止容器)。
-
重現性(驅動程序受限制,防止sysadmin錯誤操作)。
當NVIDIA驅動基於容器化安裝後,整個架構將演變成圖中描述的樣子。
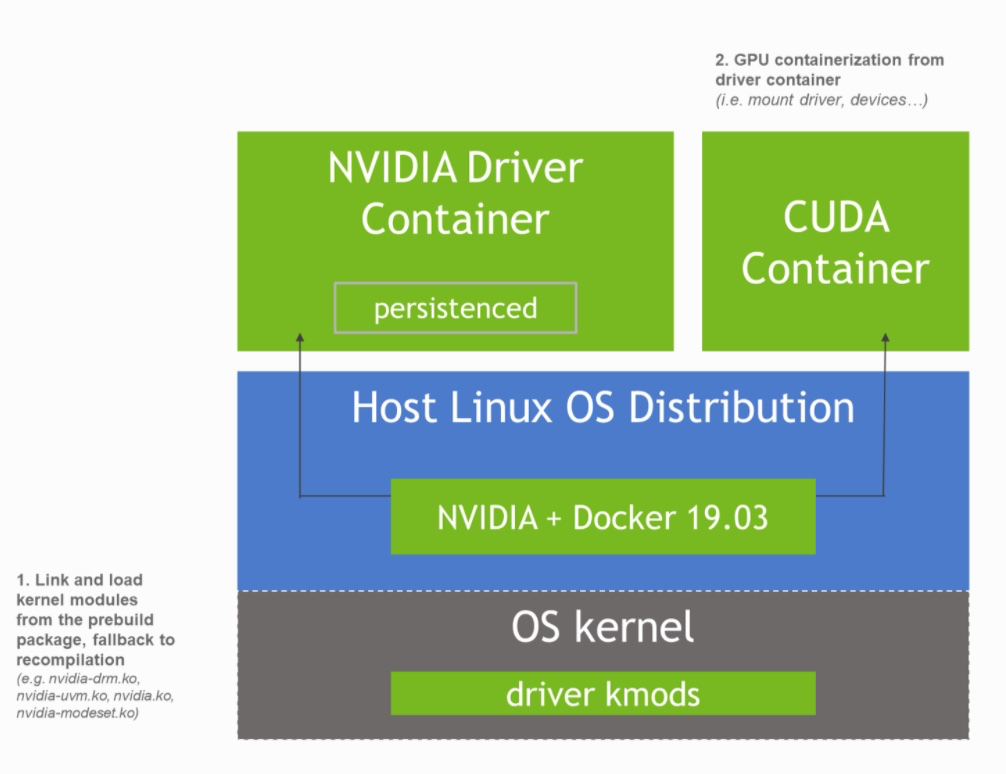
基於容器安裝NVIDIA驅動的整個流程可以分為如下的兩個部分:
-
鏡像構建階段
-
容器啟動階段
鏡像構建階段
要想了解在構建nvidia驅動鏡像過程中都有哪些操作,可以閱讀構建鏡像的Dockerfile,NVIDIA官方將這些Dockerfile存放在Gitlab上,我們以https://gitlab.com/nvidia/container-images/driver/-/blob/master/centos7/Dockerfile為例進行說明。
1.環境準備
首先是準備環境,環境準備的主要是安裝一些工具,比如curl、gcc等。
FROM nvidia/cuda:11.2.1-base-centos7
RUN yum install -y \
ca-certificates \
curl \
gcc \
glibc.i686 \
make \
kmod && \
rm -rf /var/cache/yum/*
RUN curl -fsSL -o /usr/local/bin/donkey https://github.com/3XX0/donkey/releases/download/v1.1.0/donkey && \
curl -fsSL -o /usr/local/bin/extract-vmlinux https://raw.githubusercontent.com/torvalds/linux/master/scripts/extract-vmlinux && \
chmod +x /usr/local/bin/donkey /usr/local/bin/extract-vmlinux2.安裝用戶空間使用的工具
當環境準備好以後,接下來主要做如下幾件事:
-
下載NVIDIA驅動文件(以.run結尾),驅動版本可以在執行docker build時通過--build-arg DRIVER_VERSION=<驅動版本>指定。
-
執行nvidia-installer(由NVIDIA驅動文件提供)安裝用戶空間使用的工具(例如:nvidia-smi、nvidia-uninstall、nvidia-settings等工具)到鏡像的/usr/bin下。
-
將需要編譯內核模塊有關的文件存放在/usr/src/nvidia-$DRIVER_VERSION這個目錄下,後面編譯和安裝內核模塊時需要用到這些文件。
#ARG BASE_URL=http://us.download.nvidia.com/XFree86/Linux-x86_64
ARG BASE_URL=https://us.download.nvidia.com/tesla
ARG DRIVER_VERSION
ENV DRIVER_VERSION=$DRIVER_VERSION
# Install the userspace components and copy the kernel module sources.
RUN cd /tmp && \
curl -fSsl -O $BASE_URL/$DRIVER_VERSION/NVIDIA-Linux-x86_64-$DRIVER_VERSION.run && \
sh NVIDIA-Linux-x86_64-$DRIVER_VERSION.run -x && \
cd NVIDIA-Linux-x86_64-$DRIVER_VERSION* && \
./nvidia-installer --silent \
--no-kernel-module \
--install-compat32-libs \
--no-nouveau-check \
--no-nvidia-modprobe \
--no-rpms \
--no-backup \
--no-check-for-alternate-installs \
--no-libglx-indirect \
--no-install-libglvnd \
--x-prefix=/tmp/null \
--x-module-path=/tmp/null \
--x-library-path=/tmp/null \
--x-sysconfig-path=/tmp/null && \
mkdir -p /usr/src/nvidia-$DRIVER_VERSION && \
mv LICENSE mkprecompiled kernel /usr/src/nvidia-$DRIVER_VERSION && \
sed '9,${/^\(kernel\|LICENSE\)/!d}' .manifest > /usr/src/nvidia-$DRIVER_VERSION/.manifest && \
rm -rf /tmp/*3.編譯驅動內核模塊
這一步主要操作是編譯NVIDIA驅動的內核模塊並且生成一個包,這個包將會在容器啟動時,執行nvidia-installer安裝驅動內核模塊時用到。
在構建鏡像過程中,KERNEL_VERSION可以通過docker build --build-arg KERNEL_VERSION=<kernel版本>,而且可以指定多個內核版本(通過逗號分隔),然後在Dockerfile中通過一個for循環為每個一個內核版本編譯一個NVIDIA驅動內核模塊包,供容器啟動時nvidia-installer使用。
ARG KERNEL_VERSION=latest
# Compile the kernel modules and generate precompiled packages for use by the nvidia-installer.
RUN yum makecache -y && \
for version in $(echo $KERNEL_VERSION | tr ',' ' '); do \
nvidia-driver update -k $version -t builtin ${PRIVATE_KEY:+"-s ${PRIVATE_KEY}"}; \
done && \
rm -rf /var/cache/yum/*
針對每一個內核版本,執行了“nvidia-driver update”這條命令,nvidia-driver這個腳本的內容,可以從https://gitlab.com/nvidia/container-images/driver/-/blob/master/centos7/nvidia-driver查看。
“nvidia-driver update”執行的是update()這個函數,函數內容如下:
update() {
exec 3>&2
if exec 2> /dev/null 4< ${PID_FILE}; then
if ! flock -n 4 && read pid <&4 && kill -0 "${pid}"; then
exec > >(tee -a "/proc/${pid}/fd/1")
exec 2> >(tee -a "/proc/${pid}/fd/2" >&3)
else
exec 2>&3
fi
exec 4>&-
fi
exec 3>&-
echo -e "\n========== NVIDIA Software Updater ==========\n"
echo -e "Starting update of NVIDIA driver version ${DRIVER_VERSION} for Linux kernel version ${KERNEL_VERSION}\n"
trap "echo 'Caught signal'; exit 1" HUP INT QUIT PIPE TERM
# 1.更新yum源的cache,便於使用yum安裝kernel-headers、kernel-devels等包。
_update_package_cache
# 2.用於重置KERNEL_VERSION這個環境變量
_resolve_kernel_version || exit 1
# 3.用於安裝kernel-headers,kernel-devel和kernel三個包
_install_prerequisites
# 4.如果檢測到/usr/src/nvidia-$DRIVER_VERSION/kernel/precompiled目錄下存在對於某個內核版本(由KERNEL_VERSION指定)
# 已經編譯好的包,那麼就不編譯針對該內核版本所需的驅動內核包;如果沒有找到,
# 調用_create_driver_package構建針對該內核版本所需的驅動內核包,
# 並存放在/usr/src/nvidia-$DRIVER_VERSION/kernel/precompiled目錄下。
if _kernel_requires_package; then
_create_driver_package
fi
# 5.移除kernel-headers,kernel-devel包
_remove_prerequisites
# 6.清除yum源緩存
_cleanup_package_cache
echo "Done"
exit 0
}
從_update_package_cache開始,該函數執行的邏輯如下:
-
_update_package_cache用於更新yum源的cache,便於使用yum安裝kernel-headers、kernel-devels等包。
-
_resolve_kernel_version用於重置KERNEL_VERSION這個環境變量。
-
_install_prerequisites主要用於安裝kernel-headers,kernel-devel和kernel三個包。
-
如果檢測到/usr/src/nvidia-$DRIVER_VERSION/kernel/precompiled目錄下存在對於某個內核版本(由KERNEL_VERSION指定)已經編譯好的包,那麼就不編譯針對該內核版本所需的驅動內核包;如果沒有找到,調用_create_driver_package構建針對該內核版本所需的驅動內核包,並存放在/usr/src/nvidia-$DRIVER_VERSION/kernel/precompiled目錄下。
-
_remove_prerequisites用於移除kernel-headers,kernel-devel包
-
_cleanup_package_cache用於清除yum源緩存。
下面將重點分析如下三個函數:
-
_resolve_kernel_version
-
_install_prerequisites
-
_create_driver_package
1. _resolve_kernel_version分析
_resolve_kernel_version作用是重新設置KERNEL_VERSION這個環境變量,KERNEL_VERSION這個環境變量非常重要,它的值的設置邏輯為:
-
默認的值是執行uname -r的結果。
-
如果在執行nvidia-driver update時指定了-k選項,那麼-k選項的值會賦值給KERNEL_VERSION。
-
_resolve_kernel_version函數檢查KERNEL_VERSION是否有效並重新賦值。
_resolve_kernel_version函數內容如下:
# Resolve the kernel version to the form major.minor.patch-revision.
# Detect the kernel version from 'yum list' command and set the env KERNEL_VERSION
_resolve_kernel_version() {
local version=$(yum -q list available --show-duplicates kernel-headers |
awk -v arch=$(uname -m) 'NR>1 {print $2"."arch}' | tac | grep -E -m1 "^${KERNEL_VERSION/latest/.*}")
echo "Resolving Linux kernel version..."
if [ -z "${version}" ]; then
echo "Could not resolve Linux kernel version" >&2
return 1
fi
KERNEL_VERSION="${version}"
echo "Proceeding with Linux kernel version ${KERNEL_VERSION}"
return 0
}上述代碼中比較難以理解的是第一條命令,也就是“local version=...”這條命令,這一條命令做了如下的事:
-
使用yum list獲取可用kernel-headers包版本,像下面這樣:
kernel-headers.x86_64 3.10.0-1160.el7 base
kernel-headers.x86_64 3.10.0-1160.el7 updates
kernel-headers.x86_64 3.10.0-1160.2.1.el7 updates
kernel-headers.x86_64 3.10.0-1160.2.2.el7 updates
kernel-headers.x86_64 3.10.0-1160.6.1.el7 updates
kernel-headers.x86_64 3.10.0-1160.11.1.el7 updates-
獲取中間的kernel一列,並降序排序:
3.10.0-1160.11.1.el7.x86_64
3.10.0-1160.6.1.el7.x86_64
3.10.0-1160.2.2.el7.x86_64
3.10.0-1160.2.1.el7.x86_64
3.10.0-1160.el7.x86_64
3.10.0-1160.el7.x86_64-
使用grep按如下邏輯匹配一個內核版本:
-
如果$KERNEL_VERSION不為空,那麼返回匹配$KERNEL_VERSION的結果(有可能匹配成功,也有可能匹配不成功)。
-
如果上面條件不滿足,那麼匹配帶有latest關鍵字的內核版本,如果匹配成功,那麼返回結果。
-
如果上面條件不滿足,那麼匹配第一條內核版本,即3.10.0-1160.11.1.el7.x86_64。
-
將匹配到的內核版本賦值給version這個變量。
然後檢查$version這個值是否為空,如果為空,那麼直接報錯退出;如果不為空那麼將$version的值賦值給KERNEL_VERSION。
2. _install_prerequisites分析
_install_prerequisites主要是安裝如下兩個包(KERNEL_VERSION為具體的內核版本):
-
kernel-headers-${KERNEL_VERSION}
-
kernel-devel-${KERNEL_VERSION}
-
kernel-${KERNEL_VERSION}
為什麼會對這個函數加以說明,先看看這三個包的安裝方式:
yum -q -y install kernel-headers-${KERNEL_VERSION} kernel-devel-${KERNEL_VERSION} > /dev/null
# link the kernel files which are prebuilded
ln -s /usr/src/kernels/${KERNEL_VERSION} /lib/modules/${KERNEL_VERSION}/build
echo "Installing Linux kernel module files..."
curl -fsSL $(repoquery --location kernel-${KERNEL_VERSION}) | rpm2cpio | cpio -idm --quie可以看到kernel-headers和kernel-devel是用yum安裝的,kernel是直接下載rpm包,然後用rpm2cpio和cpio處理安裝的。如果指定的內核版本的三個包沒有在yum源中出現,安裝就會出錯,此時應該怎麼處理呢?可以先將三個包下載,在製作docker鏡像傳入鏡像中,然後使用"yum localinstall"安裝kernel-devel和kernel-headers,使用
“rpm2cpio <PATH_TO_KERNEL_RPM> | cpio -idm --quie”替換原有的命令。
3._create_driver_package分析
_create_driver_package函數用於編譯運行驅動所需的內核模塊並對這些內核模塊執行簽名操作,最後利用這些內核模塊生成一個名為nvidia-modules-${KERNEL_VERSION}-buildin的文件,在執行nvidia-installer時需要用到該文件。
# Compile the kernel modules, optionally sign them, and generate a precompiled package for use by the nvidia-installer.
_create_driver_package() (
local pkg_name="nvidia-modules-${KERNEL_VERSION%%-*}${PACKAGE_TAG:+-${PACKAGE_TAG}}"
local nvidia_sign_args=""
local nvidia_modeset_sign_args=""
local nvidia_uvm_sign_args=""
trap "make -s -j SYSSRC=/lib/modules/${KERNEL_VERSION}/build clean > /dev/null" EXIT
echo "Compiling NVIDIA driver kernel modules..."
cd /usr/src/nvidia-${DRIVER_VERSION}/kernel
export IGNORE_CC_MISMATCH=1
make -s -j SYSSRC=/lib/modules/${KERNEL_VERSION}/build nv-linux.o nv-modeset-linux.o > /dev/null
echo "Relinking NVIDIA driver kernel modules..."
rm -f nvidia.ko nvidia-modeset.ko
ld -d -r -o nvidia.ko ./nv-linux.o ./nvidia/nv-kernel.o_binary
ld -d -r -o nvidia-modeset.ko ./nv-modeset-linux.o ./nvidia-modeset/nv-modeset-kernel.o_binary
if [ -n "${PRIVATE_KEY}" ]; then
echo "Signing NVIDIA driver kernel modules..."
donkey get ${PRIVATE_KEY} sh -c "PATH=${PATH}:/usr/src/linux-headers-${KERNEL_VERSION}/scripts && \
sign-file sha512 \$DONKEY_FILE pubkey.x509 nvidia.ko nvidia.ko.sign && \
sign-file sha512 \$DONKEY_FILE pubkey.x509 nvidia-modeset.ko nvidia-modeset.ko.sign && \
sign-file sha512 \$DONKEY_FILE pubkey.x509 nvidia-uvm.ko"
nvidia_sign_args="--linked-module nvidia.ko --signed-module nvidia.ko.sign"
nvidia_modeset_sign_args="--linked-module nvidia-modeset.ko --signed-module nvidia-modeset.ko.sign"
nvidia_uvm_sign_args="--signed"
fi
echo "Building NVIDIA driver package ${pkg_name}..."
../mkprecompiled --pack ${pkg_name} --description ${KERNEL_VERSION} \
--proc-mount-point /lib/modules/${KERNEL_VERSION}/proc \
--driver-version ${DRIVER_VERSION} \
--kernel-interface nv-linux.o \
--linked-module-name nvidia.ko \
--core-object-name nvidia/nv-kernel.o_binary \
${nvidia_sign_args} \
--target-directory . \
--kernel-interface nv-modeset-linux.o \
--linked-module-name nvidia-modeset.ko \
--core-object-name nvidia-modeset/nv-modeset-kernel.o_binary \
${nvidia_modeset_sign_args} \
--target-directory . \
--kernel-module nvidia-uvm.ko \
${nvidia_uvm_sign_args} \
--target-directory .
mkdir -p precompiled
mv ${pkg_name} precompiled
)
容器啟動階段
在容器啟動階段,主要運行“nvidia-driver init”命令,該命令會調用nvidia-driver腳本中的init()函數,其內容如下:
init() {
echo -e "\n========== NVIDIA Software Installer ==========\n"
echo -e "Starting installation of NVIDIA driver version ${DRIVER_VERSION} for Linux kernel version ${KERNEL_VERSION}\n"
exec 3> ${PID_FILE}
if ! flock -n 3; then
echo "An instance of the NVIDIA driver is already running, aborting"
exit 1
fi
echo $$ >&3
trap "echo 'Caught signal'; exit 1" HUP INT QUIT PIPE TERM
trap "_shutdown" EXIT
# 1.檢查驅動是否已經掛載,如果已經掛載,那麼需要卸載它
_unload_driver || exit 1
# 2.檢查驅動的rootfs是否已經mount,如果已經mount,那麼需要卸載驅動的rootfs
_unmount_rootfs
# 3.如果當前內核版本所需的驅動內核包不存在,那麼需要編譯該驅動內核包,編譯的步驟與update()函數
# 相同
if _kernel_requires_package; then
_update_package_cache
_resolve_kernel_version || exit 1
_install_prerequisites
_create_driver_package
_remove_prerequisites
_cleanup_package_cache
fi
# 4.安裝驅動
_install_driver
# 5.加載驅動
_load_driver
# 6.掛載驅動rootfs
_mount_rootfs
# 7.生成一個用於升級驅動的鉤子腳本
_write_kernel_update_hook
echo "Done, now waiting for signal"
sleep infinity &
trap "echo 'Caught signal'; _shutdown && { kill $!; exit 0; }" HUP INT QUIT PIPE TERM
trap - EXIT
while true; do wait $! || continue; done
exit 0
}
從 _unload_driver函數開始,函數的執行邏輯如下:
-
_unload_driver:如果節點已經加載了驅動(可能由其他容器加載的),那麼首先應該卸載驅動。
-
_unmount_rootfs:卸載/var/run下驅動的rootfs。
-
檢查/usr/src/nvidia-${DRIVER_VERSION}/kernel/precompiled是否有針對當前KERNEL_VERSION(由uname -r命令提供)已經編譯好的驅動內核模塊包,如果沒有,執行編譯操作,生成適合當前內核版本的驅動內核模塊包。
-
安裝驅動所需的內核模塊,這些內核模塊由之前預先編譯好的內核模塊包提供。
-
加載驅動。
-
掛載驅動的rootfs到/var/run下。
-
生成一個用於升級驅動的鉤子腳本。
-
設置一個陷阱,用戶捕獲當前進程退出時需要做哪些事情(卸載驅動、卸載/var/run下驅動的rootfs)。
_unload_driver函數分析
_unload_driver函數主要用於卸載驅動,每次加載驅動前先執行一個卸載操作。卸載操作的主要執行邏輯如下:
-
如果/var/run/nvidia-persistenced/nvidia-persistenced.pid文件存在,那麼讀取文件中的進程號,然後使用kill命令殺死進程。執行kill操作後,在1秒內檢查10次該進程是否存在,如果不存在,那麼該進程已被殺死,可以執行後續操作;如果1秒後,該進程還存在,那麼返回錯誤。
-
檢查是否有應用程序正在使用驅動,如果有應用程序正在使用驅動,那麼返回錯誤,否則卸載驅動內核模塊。
# Stop persistenced and unload the kernel modules if they are currently loaded.
_unload_driver() {
local rmmod_args=()
local nvidia_deps=0
local nvidia_refs=0
local nvidia_uvm_refs=0
local nvidia_modeset_refs=0
echo "Stopping NVIDIA persistence daemon..."
# 如果/var/run/nvidia-persistenced/nvidia-persistenced.pid存在
if [ -f /var/run/nvidia-persistenced/nvidia-persistenced.pid ]; then
# 讀取文件中進程號
local pid=$(< /var/run/nvidia-persistenced/nvidia-persistenced.pid)
# 殺死進程
kill -SIGTERM "${pid}"
# 檢查10次,每次檢查如果未發現被kill的進程,那麼直接退出for循環,超時時間為1秒
for i in $(seq 1 10); do
kill -0 "${pid}" 2> /dev/null || break
sleep 0.1
done
# 如果1秒後進程仍然存在,那麼返回錯誤
if [ $i -eq 10 ]; then
echo "Could not stop NVIDIA persistence daemon" >&2
return 1
fi
fi
# 卸載驅動內核模塊
# 檢查使用有應用程序正在使用驅動
echo "Unloading NVIDIA driver kernel modules..."
if [ -f /sys/module/nvidia_modeset/refcnt ]; then
nvidia_modeset_refs=$(< /sys/module/nvidia_modeset/refcnt)
rmmod_args+=("nvidia-modeset")
((++nvidia_deps))
fi
if [ -f /sys/module/nvidia_uvm/refcnt ]; then
nvidia_uvm_refs=$(< /sys/module/nvidia_uvm/refcnt)
rmmod_args+=("nvidia-uvm")
((++nvidia_deps))
fi
if [ -f /sys/module/nvidia/refcnt ]; then
nvidia_refs=$(< /sys/module/nvidia/refcnt)
rmmod_args+=("nvidia")
fi
# 如果以下任意一個條件滿足,說明有應用程序正在使用驅動:
# 1.變量nvidia_refs的值大於變量nvidia_deps
# 2.變量nvidia_uvm_refs大於0
# 3.變量nvidia_modeset_refs大於0
if [ ${nvidia_refs} -gt ${nvidia_deps} ] || [ ${nvidia_uvm_refs} -gt 0 ] || [ ${nvidia_modeset_refs} -gt 0 ]; then
echo "Could not unload NVIDIA driver kernel modules, driver is in use" >&2
return 1
fi
#
if [ ${#rmmod_args[@]} -gt 0 ]; then
rmmod ${rmmod_args[@]}
fi
return 0
}_unmount_rootfs函數分析
_unmount_rootfs函數用於卸載驅動的rootfs,函數邏輯比較簡單。
# Unmount the driver rootfs from the run directory.
_unmount_rootfs() {
echo "Unmounting NVIDIA driver rootfs..."
# 驅動的rootfs路徑為/run/nvidia/driver,如果發現驅動的rootfs已經掛載,就卸載/run/nvidia/driver目錄
if findmnt -r -o TARGET | grep "${RUN_DIR}/driver" > /dev/null; then
umount -l -R ${RUN_DIR}/driver
fi
}
_install_driver函數分析
_install_driver主要是使用nvidia-installer安裝nvidia驅動內核模塊,此函數依賴_create_driver_package函數編譯生成的內核驅動包。
_install_driver() {
local install_args=()
echo "Installing NVIDIA driver kernel modules..."
cd /usr/src/nvidia-${DRIVER_VERSION}
rm -rf /lib/modules/${KERNEL_VERSION}/video
if [ "${ACCEPT_LICENSE}" = "yes" ]; then
install_args+=("--accept-license")
fi
nvidia-installer --kernel-module-only --no-drm --ui=none --no-nouveau-check ${install_args[@]+"${install_args[@]}"}
# May need to add no-cc-check for Rhel, otherwise it complains about cc missing in path
# /proc/version and lib/modules/KERNEL_VERSION/proc are different, by default installer looks at /proc/ so, added the proc-mount-point
# TODO: remove the -a flag. its not needed. in the new driver version, license-acceptance is implicit
#nvidia-installer --kernel-module-only --no-drm --ui=none --no-nouveau-check --no-cc-version-check --proc-mount-point /lib/modules/${KERNEL_VERSION}/proc ${install_args[@]+"${install_args[@]}"}
}
_load_driver函數分析
_load_driver用於加載nvidia驅動,主要有兩步:
-
加載驅動所需的內核模塊。
-
以persistence mode啟動驅動。
# Load the kernel modules and start persistenced.
_load_driver() {
echo "Loading IPMI kernel module..."
modprobe ipmi_msghandler
echo "Loading NVIDIA driver kernel modules..."
modprobe -a nvidia nvidia-uvm nvidia-modeset
echo "Starting NVIDIA persistence daemon..."
nvidia-persistenced --persistence-mode
}
_mount_rootfs函數分析
_mount_rootfs用於掛載驅動的rootfs。
# Mount the driver rootfs into the run directory with the exception of sysfs.
_mount_rootfs() {
echo "Mounting NVIDIA driver rootfs..."
# 遞歸地將整個子樹標記為不可綁定
mount --make-runbindable /sys
# 遞歸的將子樹標記為私有
mount --make-private /sys
# 如果目錄/run/nvidia/drvier不存在,那麼創建該目錄
mkdir -p ${RUN_DIR}/driver
# 將容器的根目錄掛載到/run/nvidia/driver目錄下,以實現對/run/nvidia/driver目錄的操作
# 等同於對根目錄操作
mount --rbind / ${RUN_DIR}/driver
}
除此之外宿主機的/run/nvidia目錄也將會掛載到容器的/run/nvidia目錄,並且掛載時會開啟選項“mountPropagation: Bidirectional”,表示容器內操作/run/nvidia目錄後,如果其他容器也掛載了該目錄,它們對該目錄的修改可見(之所以要這麼配置,因為後面介紹的其他組件也會掛載宿主機的/run/nvidia目錄到容器中)。
volumeMounts:
- name: run-nvidia
mountPath: /run/nvidia
mountPropagation: Bidirectional
.....
volumes:
- name: run-nvidia
hostPath:
path: /run/nvidia
在Kubernetes集群中基於容器安裝節點GPU驅動
下面將演示怎樣在k8s集群中為GPU節點安裝驅動。
前提條件
在為集群節點安裝GPU驅動之前,有些條件需要滿足:
-
節點的操作系統類型為Centos7。
-
節點上不能安裝NVIDIA驅動,如果已安裝,需要卸載驅動並重啟機器。
-
k8s版本 >= 1.13(本次演示使用的集群版本為1.16.9)
同時,本次演示所使用的nvidia驅動鏡像沒有采用NVIDIA官方提供的鏡像,而是修改了nvidia-driver腳本的自定義鏡像。
操作步驟
1.下載gpu-operator項目源碼。
$ git clone -b 1.6.2 https://github.com/NVIDIA/gpu-operator.git
$ cd gpu-operator
$ export GPU_OPERATOR=$(pwd)2.修改鏡像名稱。
$ cd $GPU_OPERATOR/assets/state-driver
$ export CUSTOM_IMAGE=registry.cn-beijing.aliyuncs.com/kube-ai/nvidia-driver:450.102.04-centos7
$ sed -i "s@FILLED BY THE OPERATOR@$CUSTOM_IMAGE@g" 0500_daemonset.yaml3.刪除無關的yaml。
$ cd $GPU_OPERATOR/assets/state-driver
$ rm -rf 0410_scc.openshift.yaml4.編輯0300_rolebinding.yaml。
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: nvidia-driver
namespace: gpu-operator-resources
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: nvidia-driver
# 註釋這一行
# namespace: gpu-operator-resources
subjects:
- kind: ServiceAccount
name: nvidia-driver
namespace: gpu-operator-resources
# 註釋這兩行
# userNames:
# - system:serviceaccount:gpu-operator-resources:nvidia-driver5.創建gpu-operator-resources這個namespace。
$ kubectl create ns gpu-operator-resources6.使用kubectl部署。
$ kubectl apply -f $GPU_OPERATOR/assets/state-driver7.給GPU節點打上標籤“nvidia.com/gpu.present=true”(節點只有打上該標籤後,才會在該節點上安裝驅動)。
$ kubectl label nodes <NODE_NAME> nvidia.com/gpu.present=true驗證
1.查看pod是否處於Running狀態。
$ kubectl get po -n gpu-operator-resources
NAME READY STATUS RESTARTS AGE
nvidia-driver-daemonset-mqklz 1/1 Running 5 35m
nvidia-driver-daemonset-w5sf4 1/1 Running 5 35m
nvidia-driver-daemonset-zghxj 1/1 Running 5 35m2.進入pod執行nvdia-smi,觀察該命令能否正常執行。
$ kubectl exec -ti nvidia-driver-daemonset-mqklz -n gpu-operator-resources -- nvidia-smi
Fri Mar 19 12:59:18 2021
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 450.102.04 Driver Version: 450.102.04 CUDA Version: 11.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla V100-SXM2... On | 00000000:00:07.0 Off | 0 |
| N/A 34C P0 24W / 300W | 0MiB / 16160MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+3.登陸到節點上執行nvidia-smi,觀察能否正常執行(如果是採用nvidia官方的鏡像,無法在節點上執行nvidia-smi)。
$ [root@iZ2zeb7ywy6f2gnxrmjid1Z /]# nvidia-smi
Fri Mar 19 21:01:01 2021
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 450.102.04 Driver Version: 450.102.04 CUDA Version: 11.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla V100-SXM2... Off | 00000000:00:07.0 Off | 0 |
| N/A 33C P0 23W / 300W | 0MiB / 16160MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+4.查看節點上/dev下有沒有nvidia設備。
$ ls /dev/nvidia*
/dev/nvidia0 /dev/nvidiactl
/dev/nvidia-caps:
nvidia-cap1 nvidia-cap2可以看到,有一張GPU卡,說明安裝是成功的。
缺點
目前,基於容器安裝NVIDIA驅動還具有如下的一些不足:
-
集群中的節點必須保證是同一類操作系統(比如全是CentOS 或全是Ubuntu ),因為安裝NVIDIA驅動是以daemonset方式部署到集群中,而該daemonset的應用容器只有一個,所以只能選擇一個鏡像。
-
基於容器安裝NVIDIA驅動的穩定性還有待提高,在掛載驅動的rootfs函數(_mount_rootfs函數)中可以看到,是將容器根目錄掛載到/run/nvidia/driver目錄,當容器被kill時,容器檢測到退出信號會自動執行_unmount_rootfs函數進行unmount /run/nvidia/driver目錄操作,如果此時有另一個安裝驅動的容器啟動並執行nvidia init就會造成掛載混亂,簡單例子就是先使用“kubectl delete daemonset”刪除安裝驅動的daemonset,然後立即使用kubectl apply命令再部署該daemonset,這樣就會導致同一個節點上,一個容器在掛載驅動,另一個容器再卸載驅動,掛載驅動的容器就會報錯:驅動正在使用中。碰到這種問題,只能重啟節點解決。
總結
本篇文章花了較多篇幅介紹基於容器安裝NVIDIA GPU驅動的Dockerfile和nvidia-driver腳本,主要是希望讀者閱讀該文章後能夠基於自己的場景需求,定製化鏡像。