在前兩篇科普系列文章中,我們討論了區塊鏈和智能合約如何作為新一代基礎架構安全可靠地轉移和儲存價值。區塊鏈上的智能合約就像未連接互聯網的計算機一樣,本身就具有其內在價值,智能合約的內在價值就是創建和交易通證。然而,計算機連接了互聯網後,釋放出了巨大的創新力和價值,同樣地,智能合約一旦連接到快速增長的鏈下數據和API經濟,也將變得無比強大。如果智能合約可以連接至鏈下數據提供商、web API、企業系統、雲服務商、物聯網設備、支付系統以及其他區塊鏈等各種龐大的數據庫,那麼它將成為橫跨各個行業的主流數字協議。本文中,我們將在以下幾個方面深度解析數據和API:
- 數據是什麼?它如何驅動數據經濟?
- 數據是如何被生產出來的?
- 如何通過API交換數據?
- 什麼是大數據分析?
本文將全面分析鏈下數據經濟格局,下一篇文章中我們會接著探討如何使用一種叫“預言機”的基礎架構安全可靠地將智能合約連接至這些鏈下數據。o:p
數據與數據經濟
數據
數據是通過觀察得出的結果或信息,比如測量室外溫度、計算汽車的地理位置或記錄用戶與應用的交互情況。原始數據本身既不具有特殊價值也不可靠,而是需要用其他數據對其進行解讀或確認,以確保數據的真實性和有效性。
元數據
元數據是“關於數據的數據”。元數據中主要包含數據的基本信息,目的是大幅降低追蹤和處理信息的難度。舉個例子,某個消息的發送時間、某一溫度數值的地理位置或某次電話溝通的時長,這些全都是元數據。其目的是為數據建立索引並賦予意義。
數據清洗
除此之外,重要的應用需要保障數據可靠性,因此需要對其進行處理和清洗。這個清洗過程包括去除異常值、發現錯誤並剔除不相關的信息。比如,將目前溫度與歷史溫度進行比較,以甄別並剔除異常值。
數據經濟
在數據經濟中,各種類型的數據都會被蒐集、提煉和交換,併產生有價值的洞察。這些洞察會產生最大的社會效益,比如在共享醫療數據庫中儲存臨床研究數據,以便大家更好地瞭解最新醫療趨勢;或私營企業追蹤內部運營流程,以甄別並改善效率低下問題。
隨著數據經濟的不斷髮展,自動化程度也在不斷上升。數據可以直接觸發經濟行為,而無須人為干預。舉個例子,應用的算法規定只要滿足三個條件,就會自動支付貨款,這三個條件分別是:1)貨物送達(GPS數據);2)貨物品相完好(物聯網數據);3)貨物已清關(web API)。
數據生產
數據是某一流程或事件的副產品,數據的產生需要輸入(即行為)、數據的記錄需要提取(即測量)、而為數據賦予意義則需要聚合(即分析)。由於數據的輸入、提取和聚合技術存在一定限制門檻,因此數據並不能做到“人人平等”,數據質量也是參差不齊的。
以下是獲取新數據和原始數據的常見方式:
- 表格(手動輸入的數據):用戶填寫公開和私人表格(比如回答問卷調查、簽署文檔或在社交平臺發言),手動輸入的數據。
- 應用/網站(經過用戶同意的數據):在用戶同意應用或網站的條款和協議後獲取的數據。用戶通常在同意這些條款和協議後,就會授權網站或應用追蹤某些數據,比如APP中的操作、瀏覽習慣或甚至是性別和年齡等個人信息。
- 物聯網(實時監測的數據):安裝了傳感器和執行器的設備捕捉到的數據。並通過智能手機、智能家居、可穿戴式設備、射頻識別裝置等各種互聯網設備傳輸數據。
- 自有流程/個人經驗(由內部或個人擁有的數據):企業由於擁有專利或市場領導地位而掌控了某一業務流程,從而獲取到的數據;抑或是在個人獨特的經驗中產生的數據。
- 研究和分析(聚合並詮釋數據):蒐集來自現有數據集的數據,並對數據進行分析,包括與歷史數據進行交叉對比、對其他數據集進行交叉參考以及採用新的過濾和計算方法等。另外還有數據分銷商,他們從數據聚合商或企業大量收購數據,然後轉賣給終端用戶。數據分銷商雖然以更高的價格將數據轉賣出去,但是他們在轉賣之前會按照用戶的需求將數據處理成適合的結構或格式。
數據交換
如果數據要成為下一代應用的核心支柱,那麼就不能完全依賴內部產生數據,而是必須建立一個數據交易機制,因為買數據的成本比生產數據的成本低多了。舉個例子,開發自動駕駛汽車的算法需要運用大量數據進行目標檢測、目標分類、目標定位以及運動預測。開發者可以在內部產生這些數據,但代價是需要累計幾百萬英里的駕駛里程;而他們也可以通過API購買這些數據。
應用程序編程接口(API)其實是一組命令,控制外部應用如何接入系統內部的數據集和服務。API是目前數據和服務交易的標準方案。主流的打車軟件Uber連接了MapBox的GPS API進行車輛定位、Twilio的短信息API發送即時消息以及Braintree的支付API進行付款。這些功能都是購買的已有技術方案,而非Uber自己從零開發。
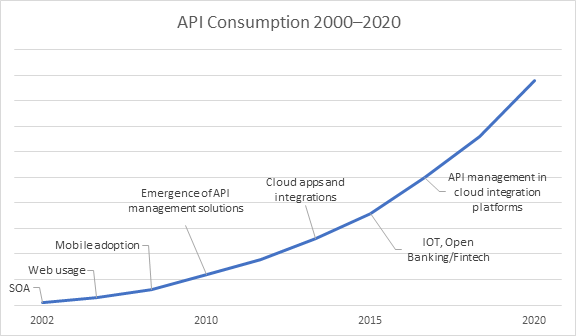
(API經濟自出現以來一直呈穩定上升趨勢,自此期間產生了許多新的API和管理API的新方案。資料來源:Software Development Company Informatica)
API的收費模式通常是訂閱模式,終端用戶可以按使用次數付費,也可以按月付費,還可以按照某種階梯制度付費。因此,數據提供商會得到經濟激勵生產數據,而終端用戶無須自行生產這些數據。API提供方和付費用戶之間還會簽署具有法律效力的合約,以避免數據盜用或未經許可轉賣等各種惡意行為,並約束數據提供商為自己的數據質量負責。
有許多API可免費供所有人使用,其中包括提供天氣數據的Open Weather Map、提供航班信息的Skyscanner Flight Search以及提供全球人類行為和信仰數據的GDELT。除此之外,全世界各國政府也積極推出透明數據的倡議,並不斷加大力度將API開源。然而,開源API的可靠性還是不如付費API,因為缺少經濟激勵和法律協議的約束,沒法控制數據質量和延時風險。大多數優質數據仍然來自付費API,這些API通常擁有頂尖的數據源、全棧基礎架構以及全職的監控團隊,併為了超越競爭對手而不斷努力創新。
大數據基礎架構和分析
編程系統能夠自主學習和自我完善,這個概念一直都受到熱烈追捧。學習的過程包括採取行動、收到結果、與歷史數據比對分析併產生新洞察,改進方法,最終實現目標。因此,目前的大趨勢是開發出一個可以自主學習的基礎架構,吸取大量數據、對數據進行過濾分類,並基於分析結果產生洞察。
美國的Facebook、Google和亞馬遜以及中國的阿里巴巴、騰訊和百度之所以能成為今天的科技巨頭,就是因為它們深耕互聯網應用,併產生了海量的用戶數據。這些數據為世界頂尖的數據分析工具,特別是人工智能和機器學習軟件,奠定了堅實的基礎。這些大數據分析技術能夠針對消費者行為、社會趨勢和市場趨勢產生大量豐富的洞察。與此同時,業務管理軟件也幫助企業更好地瞭解它們的運營情況。SAP、Salesforce和甲骨文等企業開發了企業資源規劃系統(ERP)、客戶關係管理系統(CRM)以及雲端管理軟件,使企業能夠彙總內部業務流程中的所有數據和系統,併產生關鍵洞察。
雲端計算和儲存技術正受到越來越多的關注。有了雲計算,用戶可以共享雲端基礎架構儲存和處理數據,從而無須佔用自己的系統資源。雲技術改善了應用的後端流程,增強了不同系統之間的共享,並降低了人工智能和機器學習軟件的使用成本。舉個例子,Google Cloud用戶可以使用BigQuery,這是一個SaaS軟件,可以批量分析千萬億字節的數據,並內置機器學習功能。
第四次工業革命即將到來
將人工智能/機器學習、業務管理軟件以及雲端基礎架構相結合,能從數據中獲得更加深刻的洞察。另外,邊緣計算、5G通訊網絡以及生物科技等技術的興起也促進了實時數據和生物連接數據環境的發展。在這些新興系統的推動下,經濟體系不斷朝著去人為干預和實時數據驅動決策的方向發展,而數據生成和分享的壁壘幾乎消失,頻率不斷上升,這也進一步推動了大趨勢的發展。許多人將這個大趨勢稱為“第四次工業革命”。
歡迎加入 Chainlink 開發者社區
