對於數據庫的使用者而言,索引是一個非常熟悉的概念。Wikipedia中對數據庫索引的定義:
A database index is a data structure that improves the speed of data retrieval operations on a database table at the cost of additional writes and storage space to maintain the index data structure.
用戶創建索引的期望是能夠避免全量掃描,通過索引來減少IO和CPU開銷從而加速查詢,是典型的空間換時間的優化方式。大部分數據庫會默認創建主鍵/RowKey索引,二級索引等其它類型索引需要用戶根據實際查詢情況自定義地創建。
阿里雲圖數據庫GDB對於用戶點邊的每一個屬性都會自動創建索引信息,減少用戶額外的索引操作。同時,用戶也可以根據訪問場景通過GDB支持的標準圖查詢語言Gremlin動態地創建複合索引、唯一索引和點中心索引等其它類型的索引來加速特定的查詢。
自動索引
LDBC SNB是面向圖數據管理系統的Benchmark,越來越受到圖數據庫廠商的重視,下面以LDBC SNB的數據模型為例來說明圖數據庫GDB的自動索引是如何工作的。
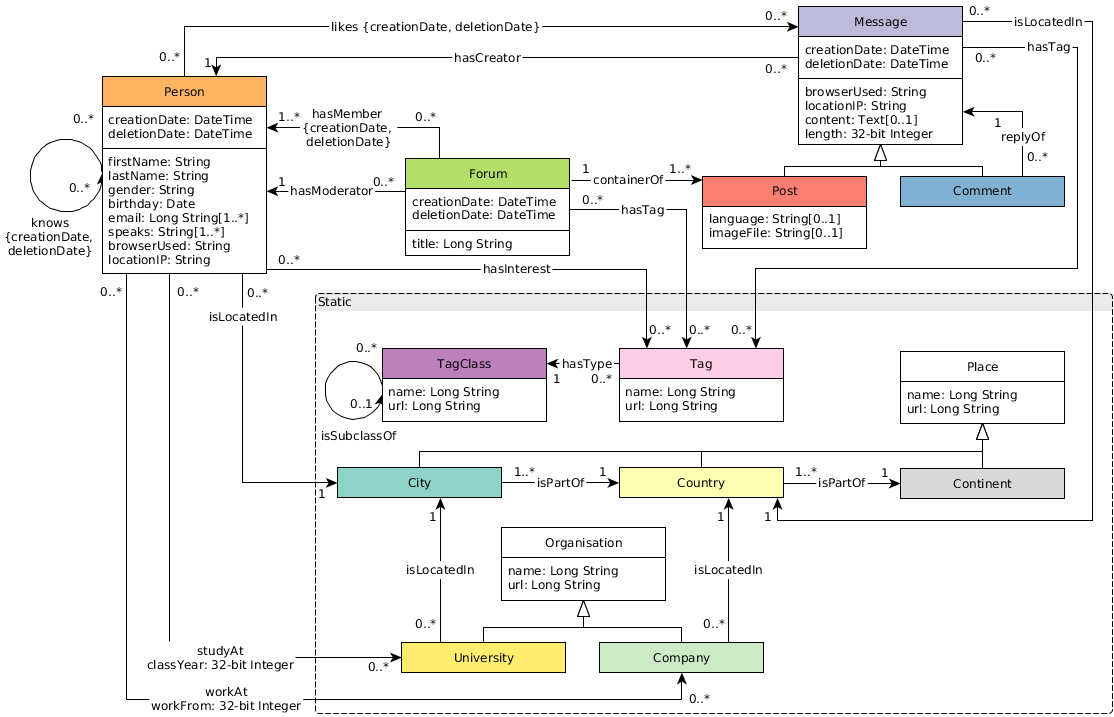
從模型中可以看出,對於Person這種Label的節點,可能會有firstName、lastName、creationDate等多種屬性。當用戶使用Gremlin DSL插入某個節點的數據時:
g.addV('Person').property('firstName', 'Foo').property('lastName', 'Bar').property('creationDate', 20200225)圖數據庫GDB會自動為每一個屬性fistName、lastName、creationDate創建索引數據。這樣查詢firstName為Foo的人時,查詢語句會自動利用對應的索引來獲取結果,避免遍歷操作:
g.V().hasLabel('Person').has('firstName', 'Foo')
# 下面的這些查詢也會利用自動索引
g.V().hasLabel('Person').has('firstName', TextP.startingWith('Fo'))
g.V().hasLabel('Person').has('creationDate', gte(20200101))如果需要根據fistName、lastName來進行查找:
g.V().hasLabel('Person').has('firstName', 'Foo').has('lastName', 'Bar')圖數據庫GDB會根據內部統計信息來決定使用firstName索引還是lastName索引。但是,如果圖數據庫中firstName為Foo以及lastName為Bar的節點數據都非常多時,通過自動索引掃描出來的數據也會非常多,這個時候就需要手動創建複合索引了。
複合索引
上面一節提到了同時對firstName和lastName進行過濾的查詢需要創建複合索引,在阿里雲圖數據庫GDB中,我們可以方便地使用Gremlin DSL來進行添加索引的操作:
gremlin> g.withSideEffect("GDB#createVertexLabelIndex", "{label: 'Person', properties: ['firstName', 'lastName'], unique: false}").inject(1)
==>GraphDbIndex
Index created, id: 1創建之後可以通過Gremlin DSL查詢對應的索引的狀態:
gremlin> g.withSideEffect("GDB#queryIndex", "all").inject(1)
==>GraphDbIndex
Id: 1, Desc: { type: 0, label: Person, property_list: [ firstName, lastName ], unique: false }, Status: Installed當索引狀態從Populating變為Installed之後,對應的索引就能夠被查詢語句利用到了。
點中心索引
點中心索引是針對“一跳場景”過濾非常實用的一種索引類型。下圖是社交網絡場景的例子,Vertex是註冊用戶,Edge是關注關係,Edge上有一個屬性since代表關注時間。

假設一個大V有100w+的粉絲,現在需要找出大V的粉絲中“關注時間在10年以上的”,在沒有索引可以利用的時候,我們需要遍歷100w+的粉絲進行過濾。這時候就會有一個問題:能否針對這個大V的100w+粉絲進行排序,按照since來進行排序 ,這樣這不需要進行全量的掃描了。這個問題的答案就是阿里雲圖數據庫GDB的點中心索引。
下面還是使用LDBC SNB的數據為例來說明點中心索引如何創建和使用,LDBC SNB的數據模型中Person節點會創建到其它Person節點數的邊,類型為knows,邊上有屬性creationDate代表開始時間。現在需要查詢某一個Person節點最近認識的10個人,返回他們之間的邊和對應的creationDate,對應的查詢語句如下:
g.V('p4398046512014').bothE('knows').
order().by('creationDate', desc).
project('relation', 'date').
by(identity()).
by(values('creationDate')).
limit(10)基於這裡的數據看下上面這條Gremlin DSL運行的時間:
gremlin> g.V('p4398046512014').bothE('knows').
......1> order().by('creationDate', desc).
......2> project('relation', 'date').
......3> by(identity()).
......4> by(values('creationDate')).
......5> limit(10).profile()
==>Traversal Metrics
Step Count Traversers Time (ms) % Dur
=============================================================================================================
GraphDbGraphStep(vertex,[p4398046512014]) 1 1 0.263 1.61
VertexStep(BOTH,[knows],edge) 426 426 4.964 30.34
OrderGlobalStep([[value(creationDate), desc]]) 11 11 10.593 64.74
RangeGlobalStep(0,10) 10 10 0.032 0.20
ProjectStep([relation, date],[[IdentityStep, Pr... 10 10 0.509 3.11
IdentityStep 10 10 0.007
PropertiesStep([creationDate],value) 10 10 0.277
>TOTAL - - 16.362 -現在對knows類型的邊加上點中心索引,操作方式和上面添加複合索引的方式類似:
gremlin> g.withSideEffect("GDB#createVertexCentricIndex", "{label: 'knows', properties: ['creationDate'], direction: 'BOTH'}").inject(1)
==>GraphDbIndex
Index created, id: 2同樣的語句再來看一下運行時間:
gremlin> g.V('p4398046512014').bothE('knows').
......1> order().by('creationDate', desc).
......2> project('relation', 'date').
......3> by(identity()).
......4> by(values('creationDate')).
......5> limit(10).profile()
==>Traversal Metrics
Step Count Traversers Time (ms) % Dur
=============================================================================================================
GraphDbVertexCentricStep(edge,[java.lang.Object... 11 11 2.854 78.41
RangeGlobalStep(0,10) 10 10 0.047 1.29
ProjectStep([relation, date],[[IdentityStep, Pr... 10 10 0.739 20.30
IdentityStep 10 10 0.030
PropertiesStep([creationDate],value) 10 10 0.442
>TOTAL - - 3.640 -對於這個測試數據集,同樣查詢語句的延遲從16.3ms縮短到了3.64ms,從Profile的結果可以看到添加了點中心索引,GDB增加了定製過的GraphDbVertexCentricStep。當然,這個測試數據集中對應的點只有426條邊,對於真實業務而言,添加合適的點中心索引可能會帶來數十倍的性能提升。
結束語
阿里雲圖數據庫GDB支持的自動索引,可以滿足大部分業務場景的查詢需求,很大程度上節省了用戶接入的時間,同時用戶可以根據查詢情況定製更多的索引來提升特定場景的性能。圖數據庫的場景中還可以衍生出更多有意思的索引類型,比如子圖匹配場景的索引、針對節點可達性查詢的索引等,讓用戶以更快的速度探索互聯數據的奧祕。