
前言
那天我和同事一起吃完晚飯回公司加班,然後就群裡就有人@我說xxx商戶說收不到推送,一開始覺得沒啥。我第一反應是不是極光沒註冊上,就讓客服通知商戶,重新登錄下試試。這邊打開極光推送的後臺進行檢查。後面反應收不到推送的越來越多,我就知道這事情不簡單。
事故經過
由於大量商戶反應收不到推送,我第一反應是不是推送系統掛了,導致沒有進行推送。於是讓運維老哥檢查推送系統各節點的情況,發現都正常。於是打開RabbitMQ的管控臺看了一下,人都蒙了。已經有幾萬條消息處於ready狀態,還有幾百條unacked的消息。
我以為推送服務和MQ連接斷開了,導致無法推送消息,於是讓運維重啟推送服務,將所有的推送服務重啟完,發現unacked的消息全部變成ready,但是沒過多久又有幾百條unacked的消息了,這個就很明顯了能消費,沒有進行ack呀。
當時我以為是網絡問題,導致mq無法接收到ack,讓運維老哥檢查了一下,發現網絡沒問題。現在看是真的是傻,網絡有問題連接都連不上。由於確定的是無法ack造成的,立馬將ack模式由原來的manual 改成auto緊急發佈。將所有的節點升級好以後,發現推送正常了。
你以為這就結束了其實並沒有,沒過多久發現有一臺MQ服務出現異常,由於生產採用了鏡像隊列,立即將這臺有問題的MQ從集群中移除。直接進行重置,然後加入回集群。這事情算是告一段落了。此時已經接近24:00了。

時間來到第二天上午10:00,運維那邊又出現報警了,說推送系統有臺機器,磁盤快被寫滿了,並且佔用率很高。我的乖乖從昨晚到現在寫了快40G的日誌,一看報錯信息瞬間就明白問題出在哪裡了。麻溜的把bug修了緊急發佈。
吐槽一波公司的ELK,壓根就沒有收集到這個報錯信息,導致我沒有及時發現。
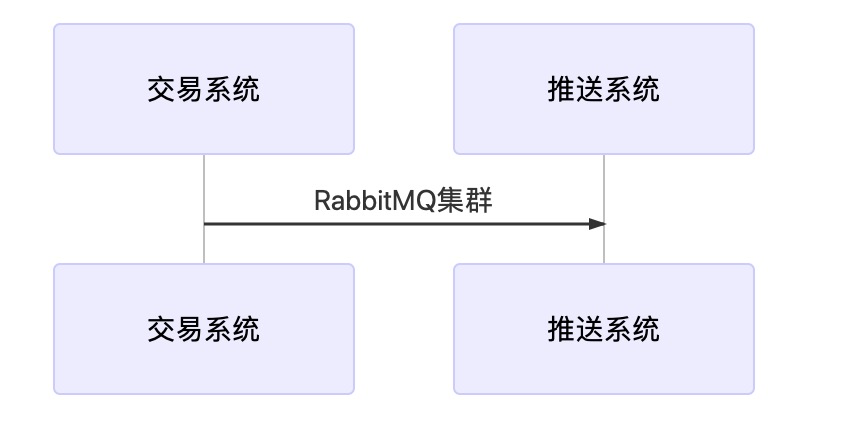
事故重現-隊列阻塞
MQ配置
spring:
# 消息隊列
rabbitmq:
host: 10.0.0.53
username: guest
password: guest
virtual-host: local
port: 5672
# 消息發送確認
publisher-confirm-type: correlated
# 開啟發送失敗退回
publisher-returns: true
listener:
simple:
# 消費端最小併發數
concurrency: 1
# 消費端最大併發數
max-concurrency: 5
# 一次請求中預處理的消息數量
prefetch: 2
# 手動應答
acknowledge-mode: manual問題代碼
@RabbitListener(queues = ORDER_QUEUE)
public void receiveOrder(@Payload String encryptOrderDto,
@Headers Map<String,Object> headers,
Channel channel) throws Exception {
// 解密和解析
String decryptOrderDto = EncryptUtil.decryptByAes(encryptOrderDto);
OrderDto orderDto = JSON.parseObject(decryptOrderDto, OrderDto.class);
try {
// 模擬推送
pushMsg(orderDto);
}catch (Exception e){
log.error("推送失敗-錯誤信息:{},消息內容:{}", e.getLocalizedMessage(), JSON.toJSONString(orderDto));
}finally {
// 消息簽收
channel.basicAck((Long) headers.get(AmqpHeaders.DELIVERY_TAG),false);
}
} 看起來好像沒啥問題。由於和交易系統約定好,訂單數據需要先轉換json串,然後再使用AES進行加密,所以這邊需要,先進行解密然後在進行解析。才能得到訂單數據。
為了防止消息丟失,交易系統做了失敗重發機制,防止消息丟失,不巧的是重發的時候沒有對訂單數據進行加密。這就導致推送系統,在解密的時候出異常,從而無法進行ack。
默默的吐槽一句:人在家中坐,鍋從天上來。
模擬推送
發送3條正常的消息
curl http://localhost:8080/sendMsg/3發送1條錯誤的消息
curl http://localhost:8080/sendErrorMsg/1再發送3條正常的消息
curl http://localhost:8080/sendMsg/3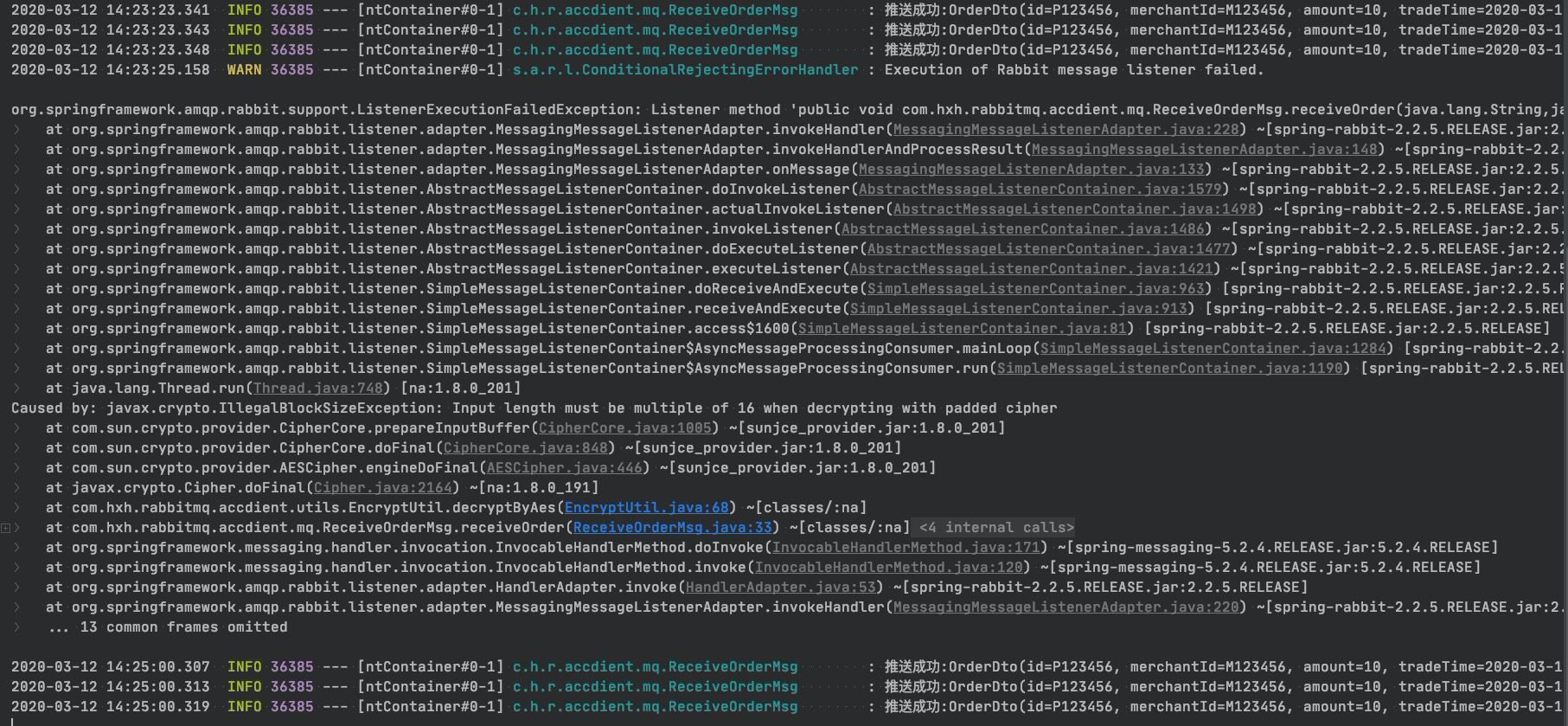
觀察日誌發下,雖然有報錯,但是還能正常進行推送。但是RabbitMQ已經出現了一條unacked的消息。
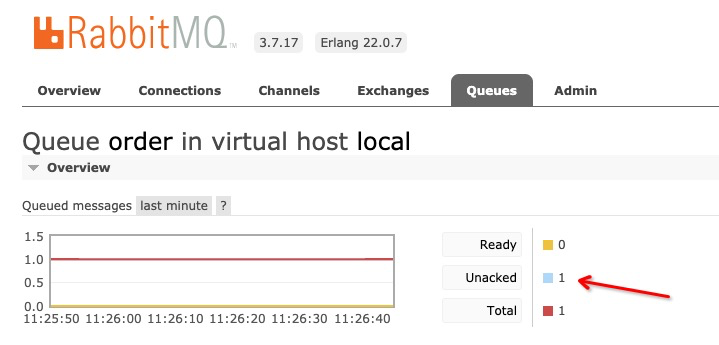
繼續發送1條錯誤的消息
curl http://localhost:8080/sendErrorMsg/1再發送3條正常的消息
curl http://localhost:8080/sendMsg/3這個時候你會發現控制檯報錯,當然錯誤信息是解密失敗,但是正常的消息卻沒有被消費,這個時候其實隊列已經阻塞了。
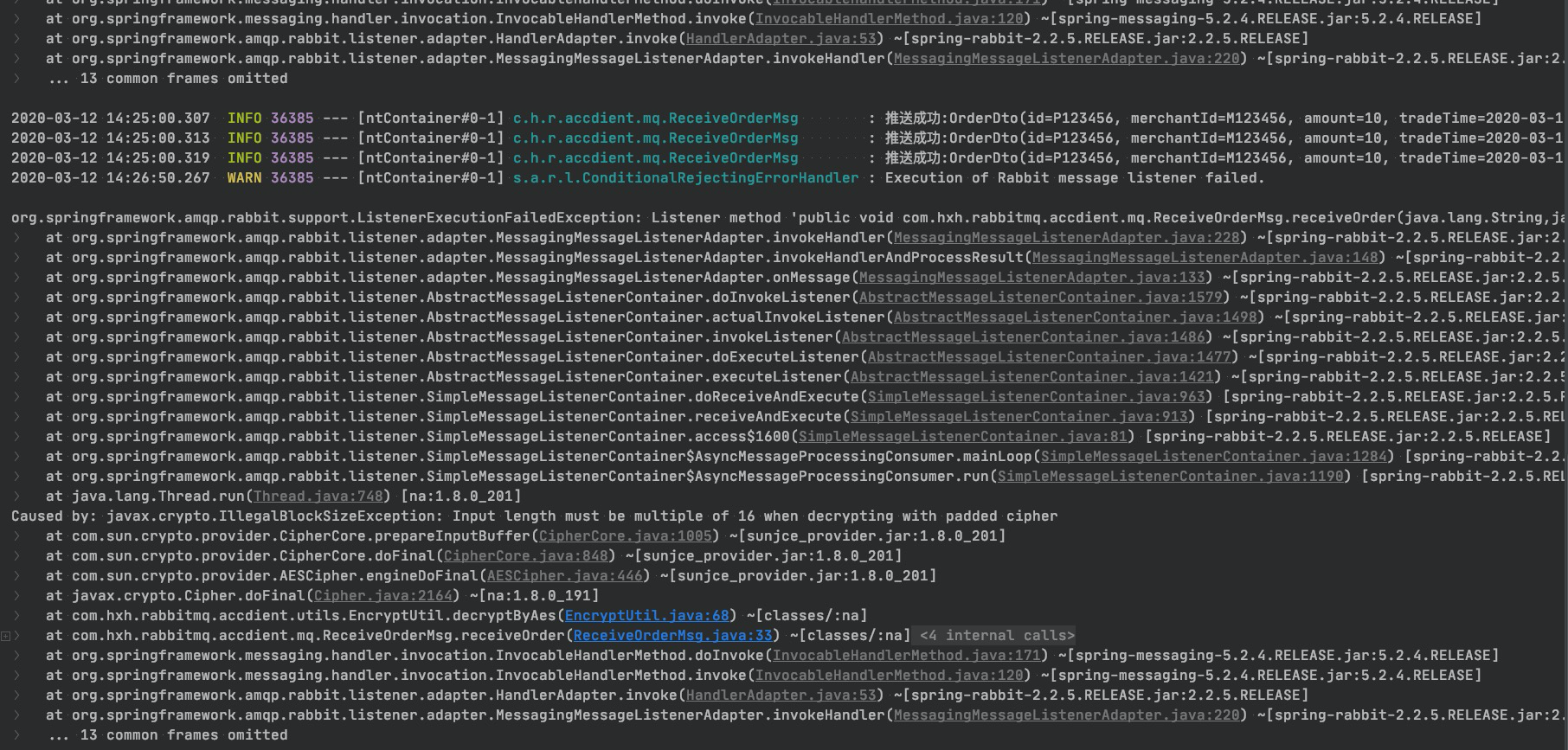
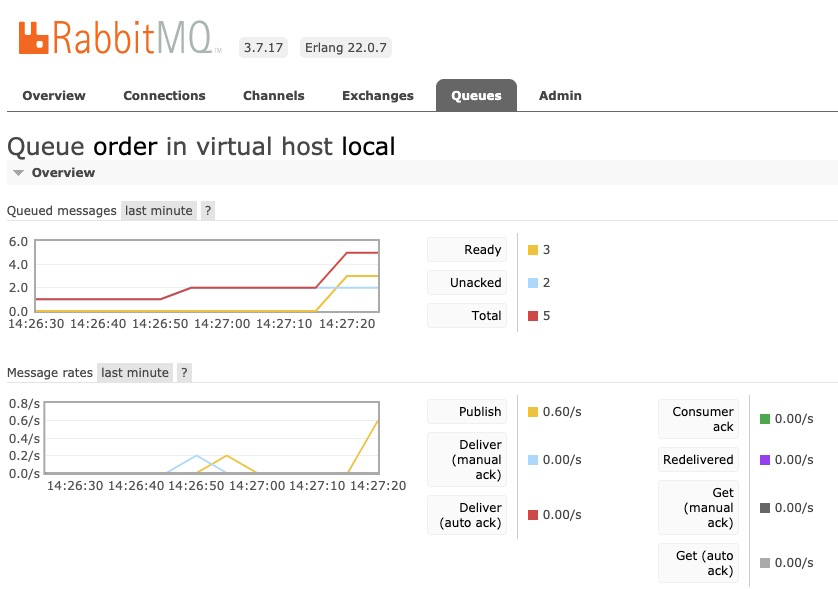
從RabbitMQ管控臺也可以看到,剛剛發送的的3條消息處於ready狀態。這個時候就如果一直有消息進入,都會堆積在隊裡裡面無法被消費。
再發送3條正常的消息
curl http://localhost:8080/sendMsg/3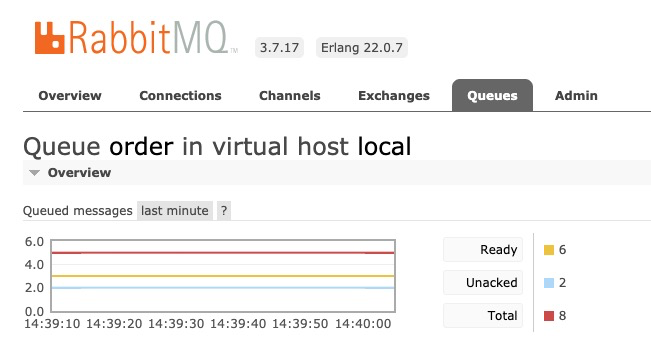
分析原因
上面說了是由於沒有進行ack導致隊裡阻塞。那麼問題來了,這是為什麼呢?其實這是RabbitMQ的一種保護機制。防止當消息激增的時候,海量的消息進入consumer而引發consumer宕機。
RabbitMQ提供了一種QOS(服務質量保證)功能,即在非自動確認的消息的前提下,限制信道上的消費者所能保持的最大未確認的數量。可以通過設置PrefetchCount實現。
舉例說明:可以理解為在consumer前面加了一個緩衝容器,容器能容納最大的消息數量就是PrefetchCount。如果容器沒有滿RabbitMQ就會將消息投遞到容器內,如果滿了就不投遞了。當consumer對消息進行ack以後就會將此消息移除,從而放入新的消息。
listener:
simple:
# 消費端最小併發數
concurrency: 1
# 消費端最大併發數
max-concurrency: 5
# 一次處理的消息數量
prefetch: 2
# 手動應答
acknowledge-mode: manualprefetch參數就是PrefetchCount
通過上面的配置發現prefetch我只配置了2,並且concurrency配置的只有1,所以當我發送了2條錯誤消息以後,由於解密失敗這2條消息一直沒有被ack。將緩衝區沾滿了,這個時候RabbitMQ認為這個consumer已經沒有消費能力了就不繼續給它推送消息了,所以就造成了隊列阻塞。
判斷隊列是否有阻塞的風險。
當ack模式為manual,並且線上出現了unacked消息,這個時候不用慌。由於QOS是限制信道channel上的消費者所能保持的最大未確認的數量。所以允許出現unacked的數量可以通過channelCount * prefetchCount * 節點數量 得出。
channlCount就是由concurrency,max-concurrency決定的。
-
min=concurrency * prefetch * 節點數量 -
max=max-concurrency * prefetch * 節點數量
由此可以的出結論
-
unacked_msg_count<min隊列不會阻塞。但需要及時處理unacked的消息。 -
unacked_msg_count>=min可能會出現堵塞。 -
unacked_msg_count>=max隊列一定阻塞。
這裡需要好好理解一下。
處理方法
其實處理的方法很簡單,將解密和解析的方法放入try catch中就解決了這樣不管解密正常與否,消息都會被簽收。如果出錯將會輸出錯誤日誌,讓開發人員進行處理了。
對於這個就需要有日誌監控系統,來及時告警了。
@RabbitListener(queues = ORDER_QUEUE)
public void receiveOrder(@Payload String encryptOrderDto,
@Headers Map<String,Object> headers,
Channel channel) throws Exception {
try {
// 解密和解析
String decryptOrderDto = EncryptUtil.decryptByAes(encryptOrderDto);
OrderDto orderDto = JSON.parseObject(decryptOrderDto, OrderDto.class);
// 模擬推送
pushMsg(orderDto);
}catch (Exception e){
log.error("推送失敗-錯誤信息:{},消息內容:{}", e.getLocalizedMessage(), encryptOrderDto);
}finally {
// 消息簽收
channel.basicAck((Long) headers.get(AmqpHeaders.DELIVERY_TAG),false);
}
}注意的點
unacked的消息在consumer切斷連接後(重啟),會自動回到隊頭。
事故重現-磁盤佔用飆升
一開始我不知道代碼有問題,就是以為單純的沒有進行ack所以將ack模式改成auto自動,緊急升級了,這樣不管正常與否,消息都會被簽收,所以在當時確實是解決了問題。
其實現在回想起來是非常危險的操作的,將ack模式改成auto自動,這樣會使QOS不生效。會出現大量消息湧入consumer從而造成consumer宕機,可以是因為當時在晚上,交易比較少,並且推送系統有多個節點,才沒出現問題。
問題代碼
@RabbitListener(queues = ORDER_QUEUE)
public void receiveOrder(@Payload String encryptOrderDto,
@Headers Map<String,Object> headers,
Channel channel) throws Exception {
// 解密和解析
String decryptOrderDto = EncryptUtil.decryptByAes(encryptOrderDto);
OrderDto orderDto = JSON.parseObject(decryptOrderDto, OrderDto.class);
try {
// 模擬推送
pushMsg(orderDto);
}catch (Exception e){
log.error("推送失敗-錯誤信息:{},消息內容:{}", e.getLocalizedMessage(), encryptOrderDto);
}finally {
// 消息簽收
channel.basicAck((Long) headers.get(AmqpHeaders.DELIVERY_TAG),false);
}
}配置文件
listener:
simple:
# 消費端最小併發數
concurrency: 1
# 消費端最大併發數
max-concurrency: 5
# 一次處理的消息數量
prefetch: 2
# 手動應答
acknowledge-mode: auto由於當時不知道交易系統的重發機制,重發時沒有對訂單數據加密的bug,所以還是會發出少量有誤的消息。
發送1條錯誤的消息
curl http://localhost:8080/sendErrorMsg/1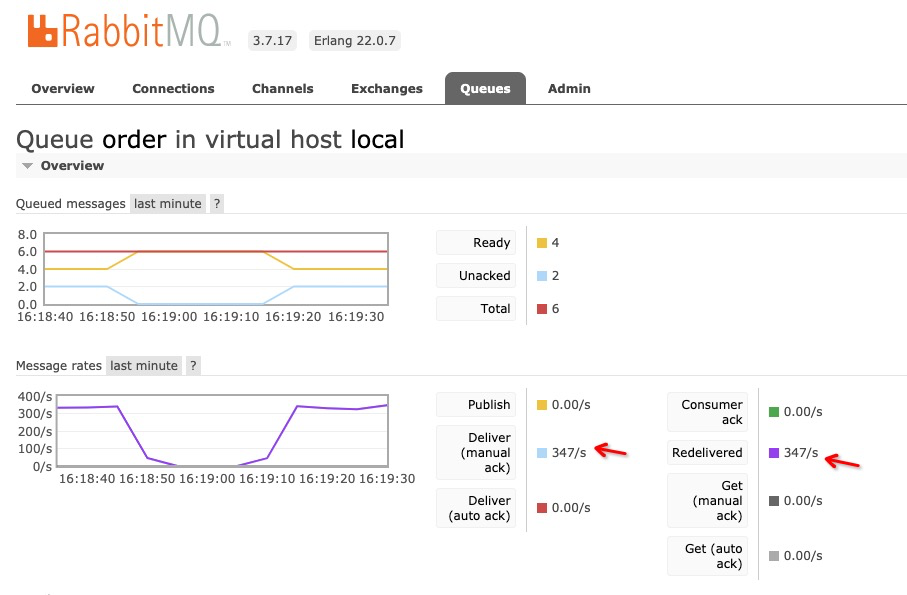
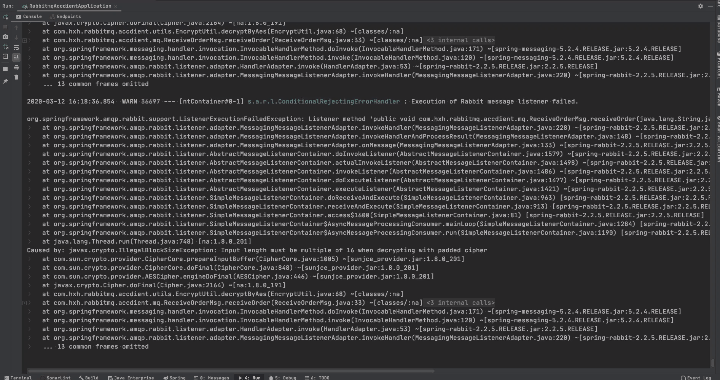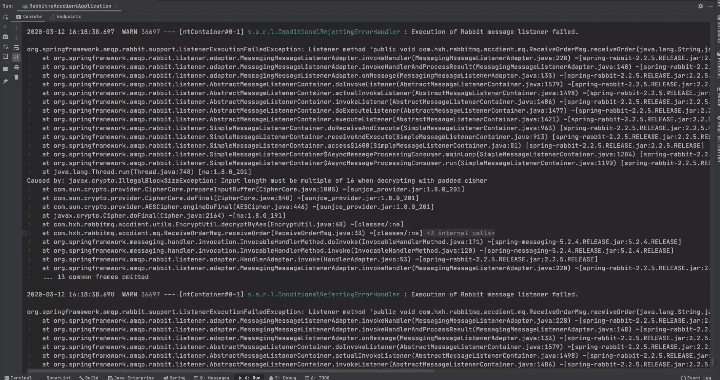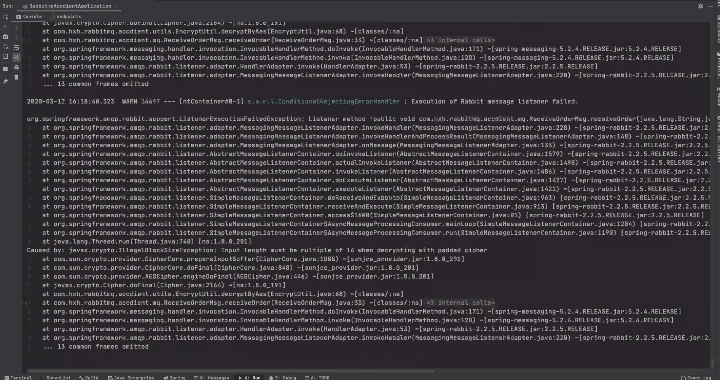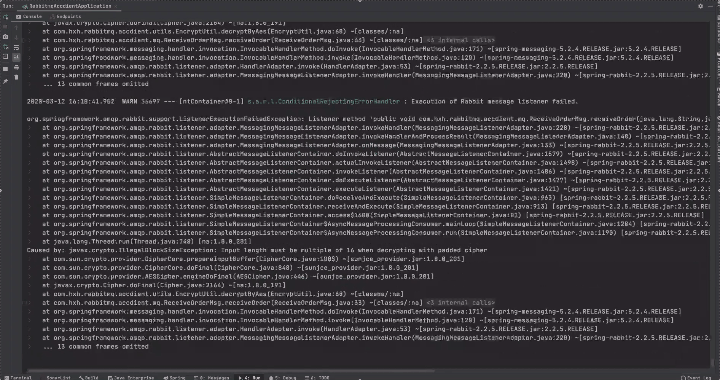
原因
RabbitMQ消息監聽程序異常時,consumer會向rabbitmq server發送Basic.Reject,表示消息拒絕接受,由於Spring默認requeue-rejected配置為true,消息會重新入隊,然後rabbitmq server重新投遞。就相當於死循環了,所以控制檯在瘋狂刷錯誤日誌造成磁盤利用率飆升的原因。
解決方法
將default-requeue-rejected: false即可。
總結
- 個人建議,生產環境不建議使用自動ack,這樣會QOS無法生效。
- 在使用手動ack的時候,需要非常注意消息簽收。
- 其實在將有問題的MQ重置時,是將錯誤的消息給清除才沒有問題了,相當於是消息丟失了。
try {
// 業務邏輯。
}catch (Exception e){
// 輸出錯誤日誌。
}finally {
// 消息簽收。
}參考資料
代碼地址
結尾
如果有人告訴你遇到線上事故不要慌,除非是超級大佬久經沙場。否則就是瞎扯淡,你讓他來試試,看看他會不會大腦一片空白,直冒汗。
如果覺得對你有幫助,可以多多評論,多多點贊哦,也可以到我的主頁看看,說不定有你喜歡的文章,也可以隨手點個關注哦,謝謝。
我是不一樣的科技宅,每天進步一點點,體驗不一樣的生活。我們下期見!