從最早的互聯網高速發展、到移動互聯網的爆發式增長,再到今天的產業互聯網、物聯網的快速崛起,各種各樣新應用、新系統產生了眾多訂單類型的需求,比如購物訂單、交流流水,外賣訂單、支付賬單、設備信息等。數據範圍不僅越來越廣,而且數據量越來越大,原有的經典架構方案已經很難滿足當前新的業務場景。在新的需求下,對存儲規模、開發效率、查詢功能、未來擴展性等眾多方面提出了更高的要求,要設計一款可靠穩定且擴展性好的系統不再是一件簡單的事情,而是變得更加複雜,需要考慮的因素也越來越多。
需求分析
首先,我們來分析一下設計一個完整的訂單系統需要考慮的因素有哪些,我們會從不同角度來闡述各種需求的關鍵點和作用。為了闡述的更加清晰,我們將眾多需求分成了三種類型,分別是:基礎需求、隱含需求和高級需求。其中“基礎需求”是指要實現訂單系統必須要考慮到的因素,也是大家最容易想到的點;“隱含需求”是指為了讓架構更加優秀,需要考慮的一些更深層次的因素;“高級需求”是指為了滿足業務未來更多可能性或者架構更加開放等可以考慮的可選因素。
基礎需求
在設計一個優秀的訂單系統時候,基礎需求是需要優先考慮的,主要包括了“規模”、“功能”和“性能”等,如果這些基礎需求無法滿足,那麼業務最簡單的功能可能都無法實現。
規模
規模:是指訂單系統中需要保存的訂單條數。當我們預測規模的時候,不能以當前的訂單規模來預估,而應該以未來一年到三年的規模來預估。
如果規模預估偏少,那麼後面可能很快就會發現當前系統不能承載,這個時候就需要重新選擇數據庫,這裡要特別注意的是,當因為規模選擇了新的數據庫後,可能原有的整個訂單系統都需要推翻重新設計,這個代價是非常大的,所以,“規模”是最最重要的考量因素,具有翻天覆地的能力,一定要慎重選擇,能激進儘量激進,儘量不要保守。
功能
功能:是指在訂單系統中需要存儲系統或數據庫需要具備的能力。這些能力主要分為兩部分,一部分是“寫入能力”,另一部分是“查詢能力”。“寫入能力”最主要的就是單行原子性,而“查詢能力”的要求會更加豐富,比如:
- 通過訂單號查詢特定訂單。
- 通過用戶名和時間範圍查詢一批訂單。
- 通過商品信息查詢訂單。
- 通過商品類目、買家地域統計訂單數。
- 通過部分商品名查詢相關商品的訂單。
- 通過買家或賣家或某個商品統計月消費額度。
- ......
這些功能如果轉換為數據庫的功能,則是:
- 主鍵查詢。
- 非主鍵列的自由組合查詢。
- 排序。
- 模糊查詢。
- 全文檢索。
- 翻頁或跳頁。
- 統計聚合:count、max、sum、groupby等。
上述功能集合基本可以覆蓋所有的查詢需求,我們實現的訂單系統的功能需求一般都在這些裡面。
性能
性能:是指寫入和查詢時的耗時情況。性能要分“查詢性能”和“寫入性能”,這裡我們分別進行討論:
- 寫入性能:大多數的訂單系統規模較大是靠長時間的累積,因此寫入一般不會有瓶頸。但是如果在較短時間內系統有大量訂單寫入,這時候就要優先考慮寫入性能。比如雙十一零點訂單、中午12點左右外賣訂單等場景。
- 查詢性能:訂單系統的請求可以分為兩類:OLTP 和 OLAP,其中核心是OLTP類請求,這類請求查詢結果需要在毫秒內返回。在訂單存儲量較小的時候,性能問題不會突顯出來,但是隨著規模的增長,查詢性能可能會越來越差,最終影響客戶使用,所以這裡要特別注意的時候,在規模增大以後的查詢性能是否可以保持穩定。其次,有時候會有些特別大的客戶,這些大客戶會導致數據存在傾斜或熱點,這些大客戶的請求就會成為慢請求,這些請求的耗時情況也需要特別注意,如果太慢會嚴重影響客戶體驗,甚至面臨流失大客戶的風險。
隱含需求
考慮完“基礎需求”後,一個訂單系統最主要的輪廓應該已經出來了,可能也能滿足當前的業務需求了,但是這個系統上線後是否可以穩定運行?遇到大促是否可以快速擴展?這裡面臨的就是一個從“60分”到“80分”的架構質量提升問題。要讓系統架構達到“80分”,主要是需要考慮以下一些“隱含需求”:可靠性、可用性、擴展能力、低成本等。
可靠性
可靠性是指數據的可靠性,也就是數據不丟失能力,一般通過百分比來表示,比如99.99%,簡稱為4個9。4個9一般是關係型數據庫的可靠性能力,而基於分佈式文件系統的分佈式系統的可靠性最高可以達到11個9,也就是保證數據不丟的能力大幅增強。
訂單系統中存儲的海量訂單很多時候是一個企業核心資產,這部分數據的可靠性很重要,選擇存儲系統或數據庫的時候最好能考慮到這一點。
可用性
可用性是指系統服務的可用能力,比如多長時間系統穩定,一般也是用百分比來表示,比如99.9%,簡稱3個9的可用性。為了保障上層業務系統的穩定性,依賴的數據庫的可用性越高越好。但是當前可用性的提高一般都是通過系統冗餘的方式來實現,比如“一主多備”“雙集群”等,這樣可用性越高的同時,成本也會越高。所以,當選擇可用性的時候,需要根據業務特徵和成本一起來權衡考慮。
擴展能力
隨著業務的發展和時間推移,業務數據會越來越多,業務請求量會繼續增長,如果遇到業務大爆發,那麼數據和請求量更會快速爆發式增長,這些增長再給業務帶來喜悅的同時,會給系統帶來更大的壓力。
這裡需要考慮的擴展能力主要有兩類,一類是存儲部分,一類是寫入和查詢的請求數。這兩個擴展能力如果沒處理好,可能一年,甚至幾個月後就需要推翻現有架構,重新選型數據庫,然後再重新設計系統。如果一開始就選擇一款可以更容易擴展的系統,那麼後續就不會被這個問題限制系統能力。所以,擴展能力也是一個很重要的因素,最好需要在設計的時候就考慮周全。
成本
成本有多個角度需要考慮,包括從其他系統遷移過來的遷移成本、運維成本、硬件成本等,包含了從系統開始建設到最後穩定運行的各個階段。
- 遷移成本:系統遷移可能發生在雲上與雲下的相互遷移,也可能發生在系統A不滿足要求需要遷移到系統B,因此我們選擇的系統組件要提供豐富的遷移手段,方便大規模訂單系統進行前期準備。
- 運維成本:高可靠、高可用、彈性等都可以節省運維成本,如果選用雲上服務的話,Severless 全託管的雲服務是一個不錯的選擇,避免處理CPU 打滿、壞盤、網絡故障等各種問題,同時按量付費,隨時彈性擴容縮容,可以節省大量運維開銷,這樣就可以將資源全部投入研發。
- 硬件成本:如果使用了雲服務,則為雲服務的價格。我們期望價格要儘可能低,因為訂單量會越來越大,不能導致最後價格太高而承受不起,導致頻繁改變系統架構。
高級需求
訂單系統滿足基礎需求和隱含需求後,已經能夠構建出健壯高效的大規模訂單系統。隨著用戶需求越來越豐富,對系統要求越來越高,訂單系統可能會在原有的 OLTP 類請求之上增加 OLAP的分析需求,這時候就需要具有一定的計算能力並能夠完成一些實時計算和批量計算需求。因此這裡列出兩個最常見的高級需求:同時支持TP/AP、豐富的計算生態。
同時支持TP/AP
訂單系統在最開始的時候可能都是簡單查詢請求(TP請求),隨著業務量發展,可能會出現一些偏分析類型的請求(AP請求),但是 AP 類型請求對資源消耗可能會很大,一個簡單的AP請求可能就會消耗完系統資源,從而影響現有的 TP 類線上業務請求,因此需要TP/AP進行隔離。
為了達到隔離,一般會引入一個ETL系統將TP數據複製一份給AP使用,這樣會帶來更高的維護成本和整合成本。因此最好選擇能同時支持TP/AP請求的數據存儲組件,一個實例就可以完成TP/AP兩種請求,避免提升架構的複雜性。
豐富的計算生態
部分訂單系統需要依靠計算來實現更豐富的功能,比如訂單信息補全、稽核、刷單檢測、用戶行為分析等。目前計算主要分為批量計算和流計算,因此設計的訂單系統要有能力對接 Spark、Flink 等流批計算引擎,通過計算引擎完成更多的用戶需求。
上面我們介紹了在設計一個訂單系統時候,需要考慮的多種因素,接下來,我們看一下訂單類系統的架構演進。
架構演進
在訂單增長迅速、需求愈加複雜的背景下,大規模訂單系統的架構經過了多輪的演進,從單一的MySQL到結合各種NoSQL的架構方案,慢慢解決了各方面的問題來滿足上一章提到的需求,接下來我們看一下訂單系統的架構是如何演進的。
小規模
在訂單系統早期,企業處於剛開始發展的階段,訂單量和查詢量都不大,很多方案都可以滿足需求。為了加快應用上線和版本迭代速度,很多訂單系統都沒有考慮後續的可擴展性,直接採用了單MySQL數據庫這種集中式的架構方案。MySQL這一類數據庫的優勢十分明顯,主要是支持SQL、事務。SQL結合事務的ACID特性,可以方便的完成業務邏輯並提供一些查詢能力,同時SQL比較通用且容易遷移到同類產品中,這種架構也是訂單架構中精簡模型。
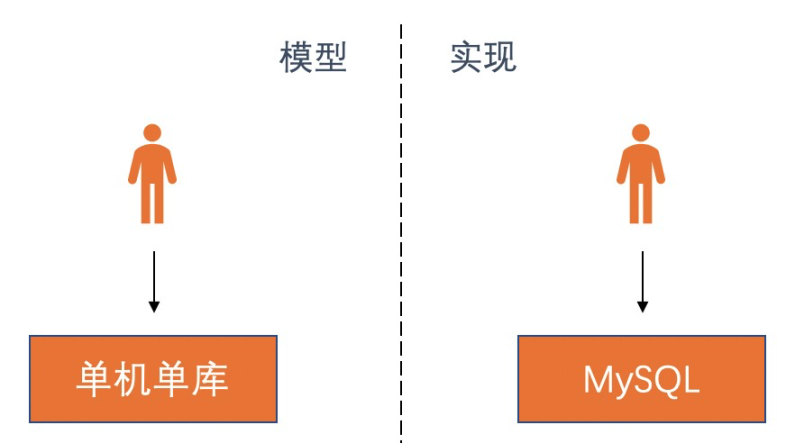
大規模
隨著系統中的訂單量和查詢量迅速增長,系統規模從小規模階段進入了大規模階段,MySQL這類數據庫的劣勢逐漸凸顯出來,用戶需求變得更多且更復雜,訂單系統也越來越難以維護,其中最主要的問題是性能問題和容量問題。
MySQL分庫分表
容量和性能的單機瓶頸問題是伴隨業務增長一直存在的,隔一段時間就需要提升MySQL實例規格進行MySQL擴容。基於MySQL解決單機瓶頸的方案是採用分庫分表,將單個庫的壓力分散到多個庫上,可以暫時解決容量瓶頸問題和部分查詢性能問題,但是過一段時間最終還是會遇到當前分庫分表量不夠,需要重新水平切分的場景,然後會伴隨數據遷移等繁瑣的後續工作,升級壓力十分巨大。而且分庫分表會和上層的業務邏輯強耦合,帶來更大的後續架構升級難度。
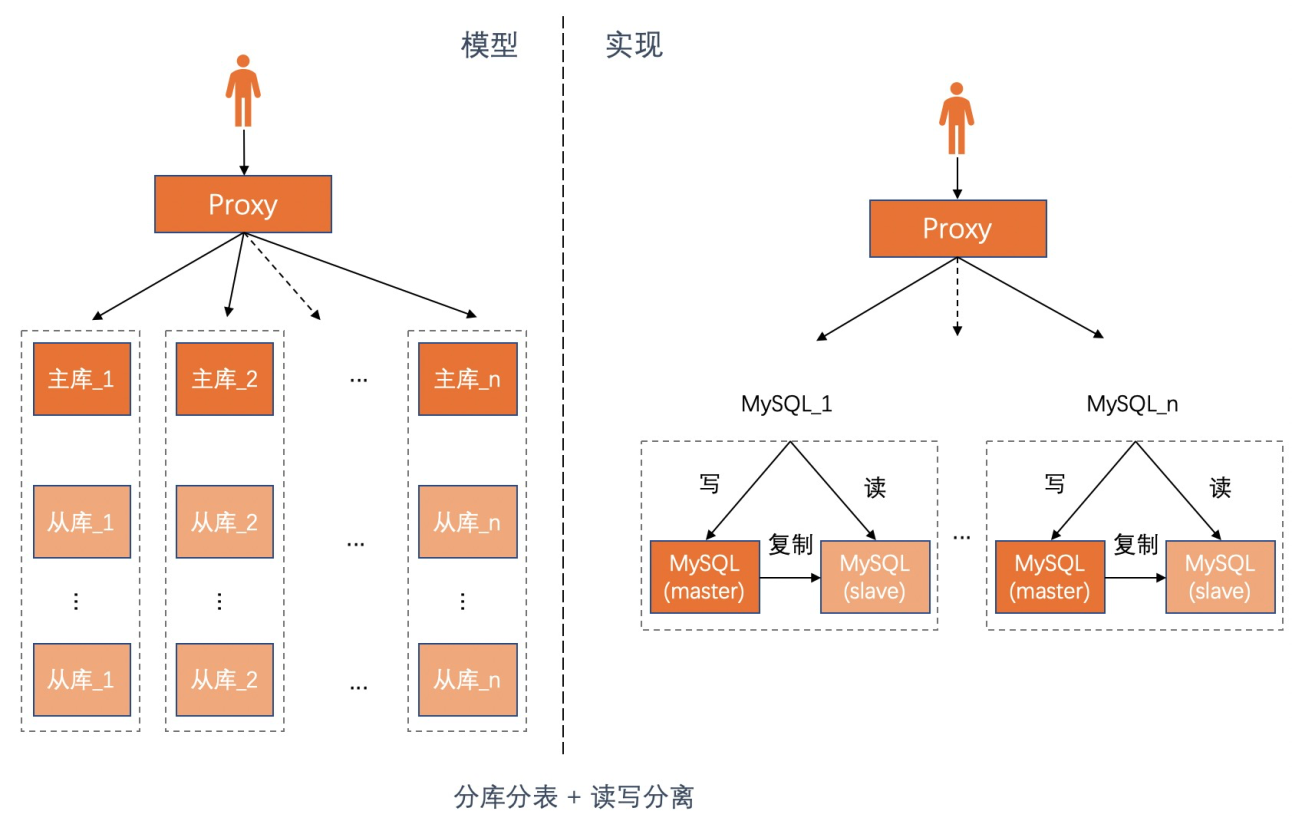
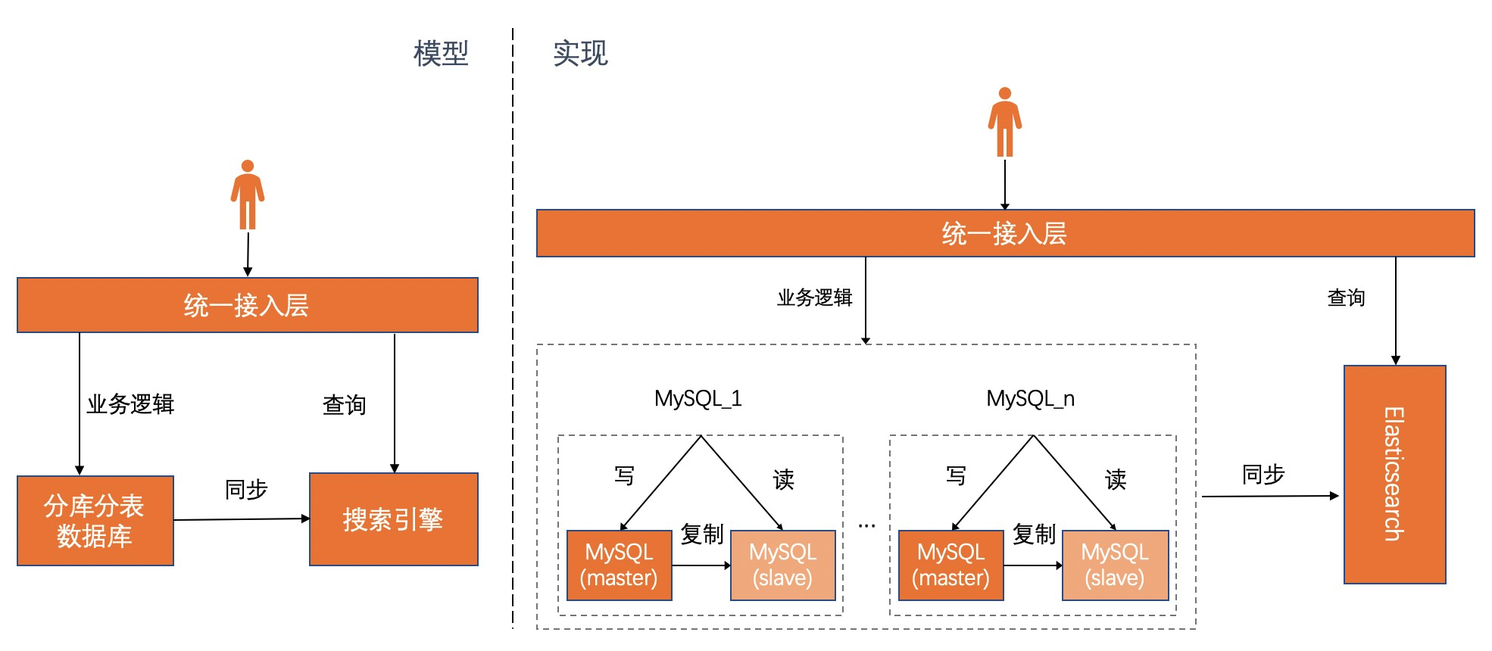
MySQL 分庫分表+ Elasticsearch
為了解決 MySQL 在複雜查詢場景下的查詢性能瓶頸,一般的訂單系統會引入 Elasticsearch 或者 Solr 等搜索引擎作為查詢引擎,用來做查詢加速。該架構選型通過 Elasticsearch 彌補了 MySQL 的查詢短板問題,提供了一些更優秀的功能實現,比如更快的模糊查詢,更好用的多字段自由組合查詢,更豐富的統計接口和很強大的全文檢索等等。該架構模式下,主要的業務邏輯還是通過 MySQL 完成,確實解決了查詢的痛點,但同時暴露了一個新的問題,用戶需要自己維護數據同步服務,保證兩部分數據的一致性,因此,這裡需要考慮如何完成數據同步。
常見的同步方案是監聽 MySQL 的 binlog 異步寫數據到 Elasticsearch 中,同步過程中為了解決消費亂序、消費失敗、數據不一致等問題,引入了 Canal、Kafka 等中間件來,還需要自己定製化地開發同步組件。
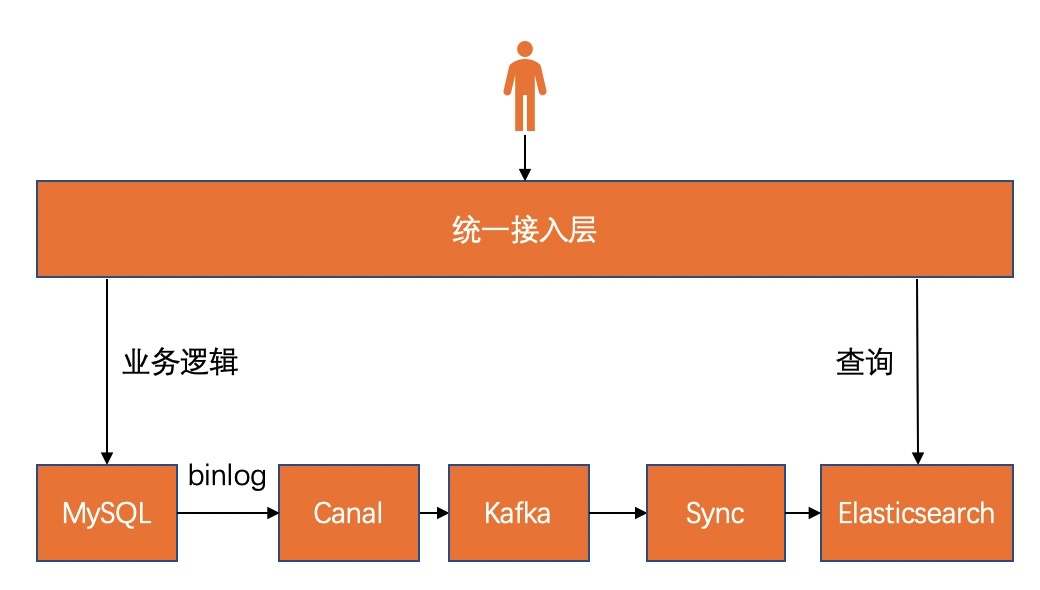
該架構確實解決了查詢的短板問題,為用戶帶來了優秀的查詢體驗,但還是有些問題沒有解決:
- 當數據量和業務量翻倍後,容量和性能又再次遇到瓶頸。要解決新的單機瓶頸,這時候需要重新分庫分表,帶來的體驗很差。或者是尋找一款可以橫向擴展的數據庫組件,不用考慮單機瓶頸,因此無需進行分庫分表,從根本上解決單機瓶頸問題。
- 該架構引入的數據同步鏈路較長,開發複雜、運維成本極高,一旦出現丟數據的問題,處理起來比較麻煩。
- Elasticsearch 需要進行運維和優化,即便是雲上託管的 Elasticsearch 服務也需要進行運維和優化,因此這裡也會存在很大一部分開銷成本。
無分庫分表
分庫分表可以分散單庫單表的壓力,但是需要預先規劃好容量,一旦觸發再次擴容,需要重新進行數據 hash 遷移,代價較高,我們期望尋找一種無分庫分表的解決方案。
MySQL + Tablestore
表格存儲(Tablestore)是阿里雲自研的結構化數據存儲服務,提供海量結構化數據存儲以及快速的查詢和分析服務。表格存儲的分佈式存儲和強大的索引引擎能夠支持 PB 級存儲、千萬 TPS 以及毫秒級延遲的服務能力。
採用 MySQL+Tablestore 的架構方案後,上述架構遇到的各種問題都能夠解決,包括MySQL查詢瓶頸和容量問題、數據同步的開發成本問題、數據一致性問題、組件過多帶來的維護複雜問題等等。該架構簡單清晰,兩個系統能力互補,可以發揮各自系統最大的優勢,且成本最低、性能最好、擴展性最強,可以支撐X10,X100的業務增長。
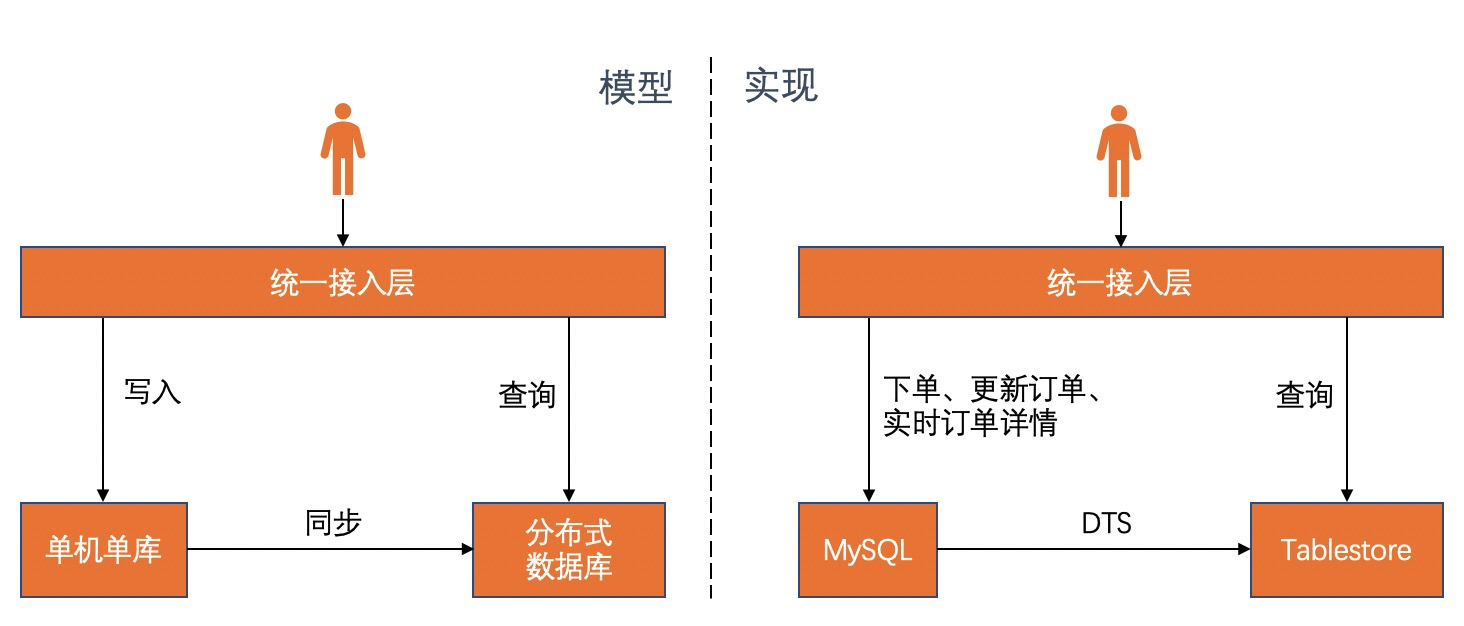
該架構依賴 MySQL 和 Tablestore 作為核心組件,MySQL 完成業務邏輯相關任務,且數據根據需求僅保留最近0.5 ~ 3個月,不會觸發 MySQL 的各項瓶頸,因此無需再分庫分表。Tablestore 作為訂單數據中臺完成訂單查詢、分析等一系列功能。該架構方案能夠滿足我們在需求分析中提到的各項需求,總結如下:
- 千億級的數據存儲能力。MySQL僅僅存儲近一段時間的數據,Tablestore可以無限水平擴展,因此該架構方案的存儲能力和容量都不是問題。
- 成本。Tablestore是採用存儲計算分離架構,底層基於飛天盤古分佈式文件系統,實現存儲和計算成本分離,因此相對傳統的MySQL等數據庫成本要低很多。
- 查詢功能及其完整度。Tablestore具有豐富的查詢方式,包括基於主表的主鍵查詢、主鍵範圍查詢,基於多元索引的多字段自由組合查詢、模糊查詢、統計聚合、全文檢索、地理位置查詢等。因為訂單查詢場景豐富,不同的查詢場景需要不同類型的索引。Tablestore 提供多元化的索引來滿足不同類型場景下的數據查詢需求,其多元索引基於倒排索引和列式存儲,可以應對大規模數據和複雜查詢場景下的各項查詢難題。
- 系統可用性和擴展能力。Tablestore 是一個 Serverless 服務化的產品,全託管,零運維。在大規模訂單系統裡,偶爾需要定期的大規模數據導入,來自在線數據庫或者是來自離線計算引擎,此時需要有足夠的計算能力能接納高吞吐的寫入,而平時可能僅需要比較小的計算能力,計算資源要足夠的彈性。在訂單量突增的情況下,Tablestore 能夠自動水平擴容,用戶無感知。Tablestore 的 Serverless 化讓用戶體驗更好,做到開箱即用,彈性擴容,按量付費。
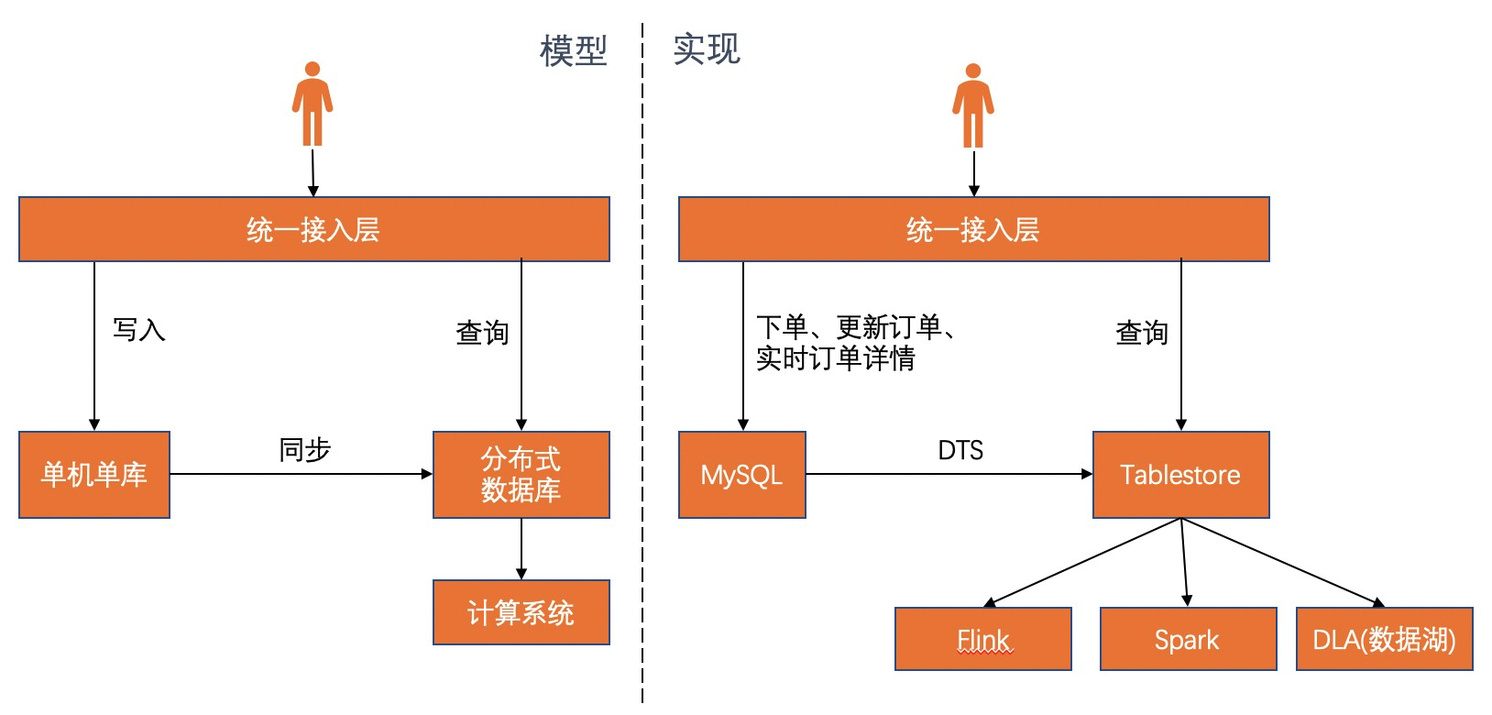
- 計算生態。企業在業務剛開始發展階段,一般是不需要流計算和批計算的,只需要一個能處理業務邏輯、一個查詢性能足夠的訂單系統即可,僅依賴 MySQL+Tablestore 即可滿足大部分需求。當然,Tablestore 擁有豐富的計算生態,積極的擁抱開源,除了比較好的支持阿里雲自研計算引擎如 MaxCompute 和 DataLakeAnalytics的計算對接,也能支持 Flink 和 Spark 等主流計算引擎的計算需求,無需數據搬遷。
基於MySQL+Tablestore的架構方案在阿里內部多個業務部門以及外部公司得到應用,使得訂單查詢和計算變得更加簡單。阿里內部某百億~千億級訂單系統採用基於Tablestore的設計後,效果改善十分明顯:
- 存儲瓶頸。之前MySQL容量告急,頻繁擴容。採用基於 Tablestore 的方案後解決了大規模訂單的容量問題,未來都不需要考慮擴容的問題。
- 查詢性能。慢查詢接口平均耗時從 7 秒左右降低到 100 毫秒。
- 成本。跟之前 MySQL 費用相比,成本下降7倍以上。
- 計算。採用基於 Tablestore 作為數據倉庫和計算引擎進行對接後,之前的定時批量計算可以採用流計算,實時性更高,同時批量計算拉取速度更快,離線計算的數據可見性週期更短。
Tablestore
MySQL+Tablestore 的方案是一個相對完善的架構方案,如果不是強依賴MySQL,比如沒有遺留系統必須依賴SQL等限制外,那麼該架構還有精簡的餘地。去掉MySQL後,將僅僅依賴Tablestore完成訂單系統相關的所有需求,系統的架構複雜度更低。
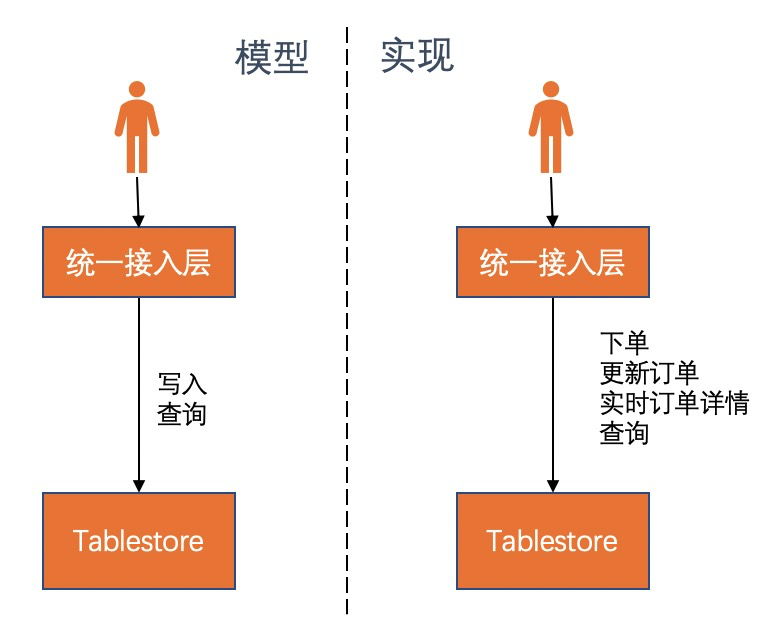
僅基於 Tablestore 的架構方案,是需要犧牲一些MySQL的能力,比如連表查詢(join)、複雜事務、SQL語句支持等。 在 Tablestore上,一般是寬表的形式來存儲訂單,儘量避免 join。同時 Tablestore 支持分區鍵級別的事務,能滿足一些簡單的事務需求。關於 SQL 語句,大部分 SQL 都可以轉化成 Tablestore 的 API。如果能夠接受這些方面的不足,僅使用 Tablestore 將能夠極大的降低架構複雜度,同時能夠使用 Tablestore 更多的優勢,包括大規模數據存儲和擴展能力、較低的成本、完整的查詢能力、高可用性、實時擴展能力、完善的計算生態等等。
總結
本篇文章主要探討了大規模訂單系統的需求和架構設計,從單 MySQL 到結合 NoSQL 彌補短板,到最後的MySQL+Tablestore,解決了容量、成本、查詢性能、擴展、計算生態等各方面的問題,讓大規模訂單系統更加簡單易實現。
除了訂單外,其他類似訂單的系統,比如物聯網傳感器數據、監控數據、日誌、指令數據、通知消息等等也都可以採用訂單系統類似的架構方案。
之後我們將會詳細介紹大規模訂單系統的一些實現細節。
- 存儲篇:詳細介紹基於 MySQL+Tablestore的大規模訂單系統的架構實現細節。
- 計算篇:詳細介紹 Tablestore 作為數據中臺的計算生態,以及基於計算系統如何完成大規模訂單系統中的一些特殊需求。
最後,歡迎加入我們的釘釘公開群(釘釘號:23307953),與我們一起探討大規模訂單系統的一些實現問題。
