
微博業務場景
微博的深度學習平臺服務於微博的實際信息流業務。我們對當前業務做了彙總,簡單來講,按照業務背景主要分為兩類:
第一類是多媒體的內容理解,這也是深度學習應用比較多的一個領域,主要包括圖片、視頻、音頻等維度的算法應用。業務應用列舉的比較多,這裡以智能裁剪為例,簡單說一下,對於全身的人像照片,生成縮略圖時,如果沒有做特殊處理,可能會生成到人身的中間部位,這張縮略圖就會顯得比較詭異;智能裁減主要做得事情,就是基於人臉檢測找到人臉位置,根據人臉位置生成縮略圖。
第二類是在 CTR 任務,在做 CTR 排序時,我們常常主要使用特徵工程加上傳統的機器學習模型,像 LR/FM 這樣的模型。這種方式下特徵工程的成本會比較高,總結來說可以歸納為複雜特徵簡單模型模式。與之對應的,便是簡單特徵複雜模型的模式,把複雜的特徵處理和特徵組合,以及高階的特徵組合隱含到模型裡面去,深度學習便是這一模式的典型代表;現在關於這方面的模型也比較多,包括 Wide&Deep、DeepFM、DeepCross 等等。
微博深度學習平臺
在算法應用中,將算法落地到實際生產環境還有很多環節要處理。這裡以微博的深度學習工作流為例,它是基於微博的實際業務,主要分為離線和在線兩條流程。
離線流程經過數據處理,生成原始樣本,各業務方根據需求進行特徵處理,生成模型的訓練樣本,然後進入模型訓練的環節,各業務選取算法進行模型的訓練和迭代,評估這個模型可用之後,將它部署到生產環境,這就是離線的部分。
在線流程也是一一對應的,在線的樣本數據經過特徵處理,特徵處理與離線使用同一套配置文件,以保證一致性與正確性。經過模型預測得到預估值,然後業務根據預估值,再去做一些相應的排序與處理,這是在線部分。
K8s 在這裡的應用主要是模型訓練和模型預測兩個環節,後面會具體展開講。大家可以看到整個工作流環節比較多,除了模型訓練,還有模型部署、樣本生成、模型部署等許多環節,深度學習平臺的目標是為業務提供一站式的工作流服務,讓業務不用關心底層煩瑣的工程細節,比如資源的調度、GPU 的分配細節等等,專注於算法和效果的調優。

圖 2 顯示的是深度學習平臺的整體架構,主要分為算法、存儲、計算、調度還有資源。在算法方面,算法又分為算法訓練和算法服務,算法訓練主要是樣本的處理和數據處理,模型訓練和評估流程,這一部分是基於 weilearn 計算框架來實現;算法服務主要是在線的特徵查詢、模型服務。另外,平臺目前也在做端上內容生成的業務需求:比如圖片風格化,給你一張目標圖片,生成跟目標圖片一樣風格的圖片,這裡有一個端上引擎。最後,對於成熟的 CTR 任務它需要一個迭代的更新上線的系統機制,這部分目前基於 K8s 和 weiflow ,實現了一套持續訓練持續部署的方案。調度這方面目前主要用 Yarn 和 K8s ,這是深度學習平臺架構。

離線訓練篇
背景
接下來介紹一下離線訓練。隨著接入的業務方越來越多,平臺面臨的問題逐漸暴露出來,簡單總結了一下,從兩個角度來看。
首先是從業務角度,業務接入門檻高。剛才提到了微博業務模式有 CTR 排序,多媒體內容理解,還有像圖片風格化這樣的多媒體內容生成。
- 訓練框架多,每個業務模式下面成熟的框架不太一致。CTR 方面業務方更多的會使用 TensorFlow 去做,圖片的視頻處理很多都會使用 Caffe 和 TensorFlow ,在語音方面 kaldi 做得更成熟一些,自然首選 kaldi。
- 遷移成本高,不同框架的設計與編程模式不同。比如 TensorFlow 是基於 tensor 張量與 graph 靜態圖的計算,當然現在的版本增加了對動態圖模式的支持;Caffe 是基於分層概念進行網絡設計,PyTorch使用了動態圖的模式。這樣的情況下,如果做 CTR 預估任務的業務方,現在需要做視頻內容方面的理解,由 TensorFlow 遷移到 Caffe,重新學習框架,那遷移框架的成本就會比較高,也是比較頭疼的一件事。
- 分佈式訓練,另外真正要作用於線上大規模應用的時候,會遇到一個分佈式訓練的問題,分佈式訓練的實施也比較複雜,後面基於 TensorFlow 會具體展開
另外從平臺角度去看,平臺需要保證穩定性,這裡基於不同的粒度做了下總結。分別是任務管理、資源管理,還有集群管理,每個粒度展開去講內容會比較多,這裡簡單說幾個點:
- 在資源管理方面,因為資源需求多樣,不同的業務在不同的算法階段,計算需求會有所差異,比如,最近 Google 發佈一個 NLP 模型 BERT 模型,有些業務方可能會去嘗試一下,只是想看一下能不能用,簡單的做下算法調研。大家都知道 GPU 挺貴的,這個時候平臺就會分配單機單卡。而有些業務方已經確定某個模型可用,有上線生成環境的需求;這種情況下想要提高一些性能,如果樣本量不大,平臺就會分配單機多卡的模式。第三種場景是大樣本大模型,單機不能滿足需求,則會分配多機多卡。所以不同的業務有不同的資源需求,需要區分對待。
- 還有集群管理這方面,今年 TensorFlow 從 1.5 版本發展到現在的 TensorFlow 1.12 版本,大約不到一年的時間迭代了7個版本,可以看到迭代速度是很快的,不同的業務方有的用1.4,有的用1.6,有的可能已經用1.12,如果沒有一個統一的隔離容器環境,很多時候,還要去解決版本不兼容的問題,比如說不同的 TensorFlow 對於 cuda 的版本要求不一致,裸機的部署成本也比較高。
深度學習訓練框架
出於這兩點,我們開發了 weilearn 深度學習框架,主要分為這四部分:樣本庫、訓練庫、調度計算、模型庫。實現業務內容的配置化,比如說你要提交一個任務,只要把參數配置一下,配需要的資源和算法,通過訓練框架將它轉化成具體的計算任務,通過配置化降低業務的接入成本。另外我們通過統一調度,提高任務的效率和平臺穩定性。基於 Yarn 跟 K8s ,跟阿里容器團隊合作,使用的 Arena 深度學習訓練工具,通過調度提交到集群,訓練完之後,把模型放到模型庫裡。另外,比如像 BERT 這種模型剛出來,每個業務都有自己的需求,自己都想試一下,其實這些任務是重複的,我們就打通了樣本庫和模型庫,實現了模型和樣本的共享,通過這種方式避免業務重複造輪子。

分佈式 TensorFlow
接下來,基於 TensorFlow 去看分佈式遇到的一些問題。首先圖 4 顯示的是 TensorFlow 的一個集群拓撲模式的發展演變過程:
- 最早 TensorFlow 支持通過 gRPC 來 ParamaterServer 模式,分佈式的性能表現平平
- 到2017年,百度的同學發佈了 ring All reduce 算法,這個算法實際上是對 Allreduce 的帶寬優化,在2017年下半年,Uber基於 ring All reduce 算法還有 NVIDIA 針對 GPU 的 NCCL 機制,對 TensorFlow 進行改造,發佈了 Horovod,大大提升了分佈式性能;
- 18年 TensorFlow 官網看到了Allreduce 的優勢,今年便把相關功能整合到在官方版本里。另外 TensorFlow 原來對分佈式沒有特別明確的語義,PS 異步模式依賴於MonitoredTrainingSession,而PS同步模式在其基礎上又增加了 SyncReplicasOptimizer 為了明確語義,它又抽象出了一層分佈式策略的模式。
對於 TensorFlow PS 模式展開講,其實它的 ParamaterServer 模式可以分為同步和異步,對於同步模式,性能是最大的瓶頸,為了提升性能,TensorFlow 使用了一個 Worker backup 的方式,簡單來講如果我們的集群起了 10 個 Worker,但是真正進行梯度聚合的時候用了 7 個,這樣通過丟掉一定的樣本數據,在保證同步的訓練效果的同時保證性能。ring All reduce 如果細分,除了 MPI 本身的 Allreduce 語義,它還有基於環狀的 ring All reduce,還有基於樹狀的 treeAllreduce。對於分佈式策略現在支持的有單機多卡的 mirrored 模式,還有多機多卡的模式。
從這裡可以看到,集群拓撲比較複雜,我們的訓練系統需要適配各種的模式。

關於 TensorFlow 在分佈式訓練遇到的一些問題,首先是前面提到的集群拓撲模式繁多,另外對於靜態拓撲,需要額外去保證端口不重複,因為靜態拓撲需要在集群啟動前,明確各個結點的服務發現信息、包括 IP 以及端口號,TensorFlow 並沒有幫你管理這些端口,需要自己去管理。另外一個問題就是任務穩定性和狀態跟蹤,這是分佈式計算任務裡面基本的需求。此外,TensorFlow 在啟動的時候,不論你的機器上有多少張卡,會把機器所有的 GPU 卡佔滿,這也是一個比較頭疼的地方。
基於 K8s 的分佈式解決方案
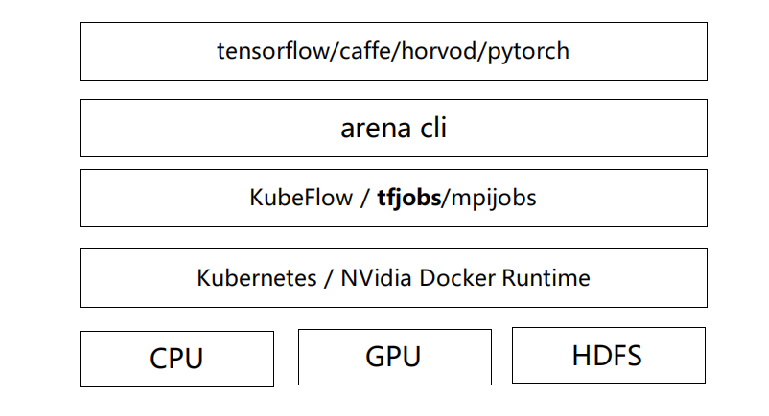
K8s 分佈式訓練的解決方案,我們是基於 Arena 來實現的,關於 Arena,現在阿里雲已經開源,大家如果想嘗試,可以從網上去下載。圖 5 顯示的是 Arena 的基礎架構,基於 Kubeflow 來做的集成與擴展。
Kubeflow 包括兩部分,一個是 ksonnet,另一個是自定義的 Operator,在 Arena 實現時,使用 helm 替代了 ksonnect,在上面又封裝了一層 CLI 的接口。回到 TensorFlow ,分佈式機制是基於自定義資源對象 TFjob,實現對分佈式集群的管理 ,簡單來說,當前提交了一個分佈式任務後,會生成一個 TFjob 描述文件,自定義控制器 TFoperator 發現 TFJob 後,根據描述文件去起一個分佈式任務集群。另外在通信方面,arena 是基於 headless Service 來實現的節點尋址。普通的 Service 如果我們要根據 DNS 尋址,它實際上線找到的是 Service 的 VIP 地址,然後在進行一次路由轉發,找到 Pod 對應的地址。而 headless service 在 DNS 尋址時直接 對 Pod 尋址, 跳過了 Service 這層路由轉發,會提升一定的性能,Pod 使用的是 Host 的網絡,這種方式也保證了集群通訊的性能。
){kind=link}
前面講了基本原理,那 Arena 都做了哪些事情?第一,支持多種集群拓撲,包括 PS、MPI、單機模式,都可以通過 Arena 提交。第二,簡化了任務的管理,前面提到到端口分配與資源調度等都是 Arena 去管理,支持多種代碼提交方式, rsync 或者 git,這部分是基於 init container 機制實現的,起任務之前先把代碼拉到本地去做。第三,TFJob 提供了一個 Dashboard,可以通過這個 Dashboard 看分佈式任務的狀態和日誌。
以上是離線訓練框架以及 K8s 的應用,這裡看到的是某個圖片分類的業務方,在接入平臺前後的對比,性能跟效果提升還是比較明顯的。
在線預測篇
模型訓練完成後,就是模型的上線部署。接下來看下模型上線這一部分基於 K8s 做的應用實踐。
模型預測,這是深度學習框架重要的環節,因為微博的業務場景需求,對併發量和延時性要求都是比較敏感的,這張圖顯示的是模型服務的整體框架,主要分為三層。
第一層是集群調度層,模型服務現在線上有 CPU、也有 GPU 的支持,基於一些歷史原因,以及業務對機器的特殊需求,這些 CPU 可能有很多型號,包括 8 核、16 核、32 核,GPU 也有 P 系列、M 系列的。基於 K8s 和 Docker 進行了資源的管理和調度,保證業務集群的穩定性。
第二層就是核心架構層,是在線服務和性能提升的關鍵層,通過統一的版本管理,對模型進行動態加載,保證線上服務更新的及時性。另外通過批處理,還有編譯優化的一些機制,保證 GPU 的性能和利用率。
第三層是算法模型層,主要封裝機器學習與深度學習常見的模型,另外離線開源的訓練框架現在有很多,不同框架導出的模型格式各不相同,這方面我們也做了兼容。

接下來從以下幾個場景跟大家介紹:多任務多模型、高可用高性能、持續訓練持續部署。
多任務多模型
模型服務平臺現在支持的服務可以歸一下類,包括多媒體服務、自然語言服務、排序模型服務。這幾類在線服務對於資源的需求是不太一樣的,多媒體服務對 GPU 的資源更敏感一些,CTR 這種,CPU 的機器一般情況下就能滿足。另外就是多模型,正常來講,一個在線服務,同一條在線樣本,只要過一個算法模型就可以了,有些場景,比如進行多模型的融合,這時同一臺樣本可能要過多個模型,這種場景可能就需要在有限的機器資源內做一些變化。
為了滿足這些需求,我們基於 K8s 做了兩件事情,一個是根據資源類型對任務進行了歸類,分為 GPU 密集型、CPU 密集型、密集型。像傳統 LR/FM 就屬於 CPU 密集型; GPU 密集型包括人臉識別、人臉分類、這些卷積神經網絡相關的,比較耗 GPU 資源,IO 密集型包括圖片下載和視頻下載。然後基於不同的類型劃分任務組,這個任務組內會整合,這些任務儘量是不同類型的。我們基於 K8s 的 label 機制,把同一個組內的任務調度到同一臺、同一批機器上,通過這種方式提高資源的利用率。
在多模型方面,基於現在的在線推理引擎,把多個模型融合在一個服務裡面,這樣同一條樣本,經過一次特徵處理,生成的這個模型可識別的格式之後直接過三個模型,通過這個方式提升一定的性能。另外這種多模型的場景,因為不同的業務方模型大小是不一樣的,有的模型可能比較小,可能只有幾兆,有的模型可能幾十兆、幾十 G、幾百 G,單機可能存不下,我們沒法去對所有的服務做統一的資源限制,主要針對業務組進行 ResourceQuota 的機制,這個圖展示是目前做到了現在一個數量。
高可用高性能
第二個場景,在線 WeiServing 平臺很大一部分服務流量來自於推薦系統,推薦系統的一個整體邏輯,簡單來看主要包括召回、過濾、粗排、精排、分發控制這幾個階段,可以看到,從粗排、精排這兩個階段來看,推薦系統大約有一千到兩千條的物料會調到 WeiServing 裡面去,推薦系統服務調用量集在十億的量,通過放大之後,WeiServing 承擔的量一天可能達到千億級,甚至萬億級,對服務的高可用性要求會更大,而且響應時間也比較敏感。
另外需要說的是,現在推薦系統的每次調用請求,某些場景下有一百多 KB,加上峰值,入流量的帶寬可能會達到幾百個 GB,所以在線 WeiServing 很大的一個特點就在於服務端的入流量比較大,那麼怎麼解決高可用和高性能?
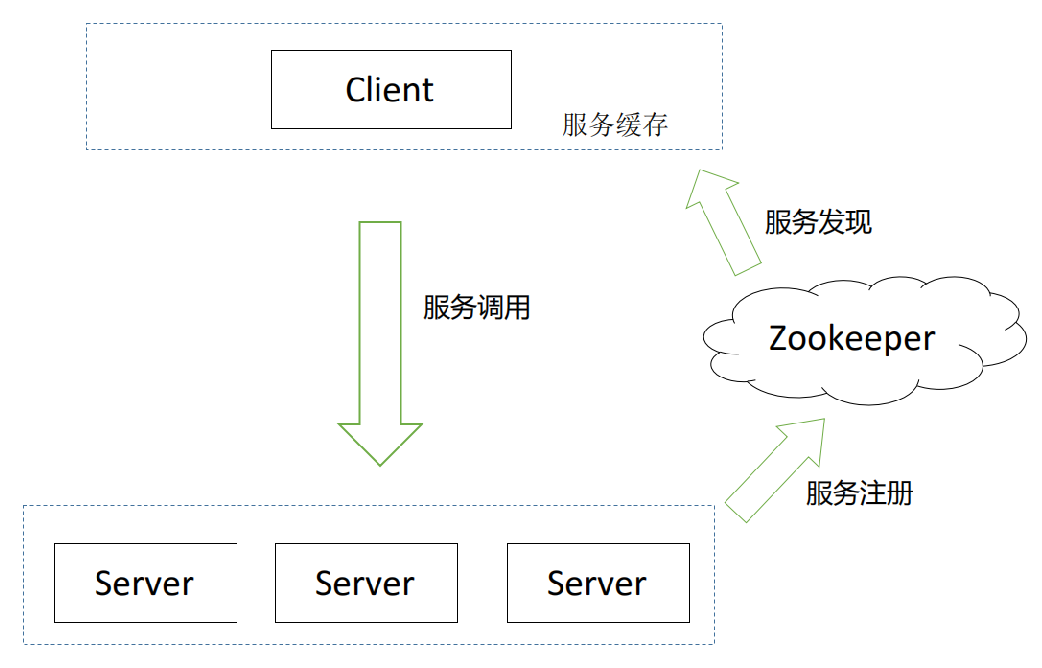
首先,我們實現了客戶端的負載均衡功能,這裡沒有使用 K8s 原生負載均衡機制機制, K8s 的負載均衡總體分為兩類,不論是 4 層的 Service,基於四層鏈路的 IPtable 與 IPVS 來實現的,還有基於 7 層鏈路 ingress,都屬於服務端的負載均衡。服務端的負載均衡有很多好處,這裡就不一一列舉了,它的缺點對於我們來說就是加長了一個網絡鏈路,轉發會引起一定的性能損耗,另外在入流量比較大的時候,proxy 可能會成為瓶頸,這張圖顯示的是早期我們用 LVS 做負載均衡,某個業務擴張了 30%,proxy 網卡將近被打滿。
基於這些原因,我們選擇了客戶端負載均衡。客戶端負載均衡,第一是直連,性能服務有保障;第二就是大的入流量情況下,沒有單點的瓶頸,任一結點故障,不會影響到整個系統的性能。客戶端的負載均衡實現也比較簡單,大同小異,這塊基於 Zookeeper 做的服務發現,客戶端做了一個緩存。我們的在線集群是一個異構的集群,CPU 核數不一樣,每臺機器的處理能力也不一樣,這裡服務端做了一些動態的權重調整,保證異構集群的性能穩定。
){kind=link}
另外,基於 K8s 的探針模式實現了服務的健康檢查,服務上線之後,通過執行業務自定義的健康檢查命令進行檢查 Pod,如果這個 Pod 失效,我們會將這種無狀態的服務進行重啟。業務方上線的這些服務,因為它的特徵處理不一樣,算法模式也不太一樣,有的是分類模型,分類模型有得分就可以了,對於迴歸模型,它需要一個連續的得分,所以在線服務有效性校驗這一塊需要業務去自定義,我們是通過 initContainer 去加載業務自定義的健康檢查插件。
關於優化,深度學習預測的優化主要分為兩部分,一個是計算的優化,一個是通訊的優化。
在優化的時候,會經常聽到一個阿姆達爾定律,它主要是講優化的投入產出比,針對鏈路裡耗時最長的階段進行優化,是投入產出比是最高的選擇,在我們這裡也比較適用。
列了兩個比較有效果的優化點,首先是 batching,batching 有一定的應用條件,GPU 的 batching,如果是調用量比較小,做 batching 可能對性能影響比較大,但是在線 QPS 比較高的情況下,做 batching 的效果是非常好的,它跟 GPU 的利用率有關。
其次,我們在做 CTR D&W 模型的時候,發現有的業務模型會特別慢,經過 Profiling 之後,發現主要耗時在 onehot 編碼處理,TensorFlow 這一部分原生使用 Eigen 的線性計算庫,這部分重寫 onehot 之後,性能提交效果比較明顯,這是實踐的效果。
持續訓練持續部署
最後一個場景就是持續訓練和持續部署(CTCD),對於推薦排序的業務場景來說,當模型穩定的時候,持續訓練持續部署是一個基本的業務需求。當模型更新的時間週期比較長時,它的在線樣本跟離線樣本的分佈會有比較大的差異,尤其是像微博這樣一個產品場景,經常有熱點流量,有不可預知性,這種樣本分佈在線、離線的差異在微博更加明顯。第二就是 CT/CD 帶來的好處,可以及時捕獲用戶短期行為的興趣,快速反饋當前用戶感興趣的內容。
基於這些背景,我們看下持續訓練持續部署的流程,簡單來講,首先是模型訓練,包括實時訓練與離線訓練生成的模型會放在模型庫裡面,模型驗證階段會從模型庫拿到模型,進行離線的指標驗證,部署到線上,再做一個線上的指標驗證,部署時會做一個灰度的發佈,根據需要有些場景需要做藍綠部署,這樣將模型推到線上,進行在線 seriving。
在具體實現部分 ,主要應用有兩個重要環節,一個是 基於 cronjob 的週期執行。cronjob 會做兩件事情,對離線訓練,會週期性地啟動,把整個流程拉起來;對於實時訓練,因為一直在線上運行,這就需要週期的去 checkpoint。
另外一個環節就是模型部署,在部署時使用的 olsubmit,它封裝了 kubectl 與服務配置管理, 提供一鍵式的服務部署與管理。首先,從模型庫裡拿到模型數據信息,包括模型文件與特徵處理文件,然後從配置中心獲取的服務元數據信息、包括需要指定的算法庫、用於服務發現的配置、模型版本管理的策略;將模型數據信息與服務元數據信息進行封裝,推到服務庫裡,然後服務庫的這些服務,主要用來熱升級和服務的部署。基於 K8s deployment 資源對象,部署在線的服務。

總結與計劃
以上是今天分享的主要內容,總結來看,基於 K8s 主要做了以下幾個事情:
- 分佈式深度學習訓練,一鍵集群任務創建,提高訓練與調度速率
- 在線預測服務異構混合調度,提高資源利用率
- 在線預測服務保障,保證服務高可用
- 持續訓練持續部署,保障模型時效性與線上效果
K8s 在微博機器學習平臺上的應用,目前處於起步階段,還有很多的事情可以做。為了更好地將 K8s 應用到平臺裡,這裡有些簡單的規劃:
第一,離線訓練數據本地化。 從目前 K8s 元語去看,它在進行調度時計算跟存儲是解耦的,那在離線大規模訓練場景中,通訊很有可能會達到一個瓶頸,所以我們計劃做一些數據本地化的事情,比如基於 Alluxio 做中間件,用於樣本數據的緩存;
第二,基於 K8s 支持更多的模型訓練框架;
第三,在線方面,為了應對熱點流量,對微博來說服務的動態擴縮容可能是個強需求,我們準備打通在線和離線集群,基於監控系統的自定義指標,比如 Prometheus,去做在線服務的動態擴縮容。
嘉賓介紹

於翔,新浪微博機器學習研發架構師,在機器學習平臺中曾負責特徵工程項目,目前主要負責算法服務平臺與深度學習平臺的搭建與開發。