什麼是人群圈選
隨著數據時代的發展,各行各業數據平臺的體量越來越大,用戶個性化運營的訴求也越來越突出,用戶標籤系統,做為個性化千人千面運營的基礎服務,應運而生。如今,幾乎所有行業(如互聯網、遊戲、教育等)都有實時精準營銷的需求。通過系統生成用戶畫像,在營銷時通過條件組合篩選用戶,快速提取目標群體,例如:
• 電商行業中,商家在運營活動前,需要根據活動的目標群體的特徵,圈選出一批目標用戶進行廣告推送或進行活動條件的判斷。
• 遊戲行業中,商家需要根據玩家的某些特徵進行圈選,針對性地發放大禮包,提高玩家活躍度。
• 教育行業中,需要根據學生不同的特徵,推送有針對性的習題,幫助學生查缺補漏。
• 搜索、門戶、視頻網站等業務中,根據用戶的關注熱點,推送不同的內容。
以電商平臺中一個典型的目標群體圈選場景為例,如服裝行業對其潛在客戶信息採集,打標,清洗後如下表:
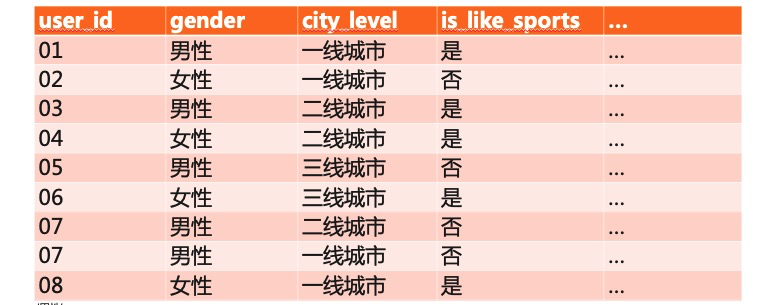 (以上表結構中,第一列為用戶身份的唯一標識,往往作為主鍵,其他列均為標籤列。)
(以上表結構中,第一列為用戶身份的唯一標識,往往作為主鍵,其他列均為標籤列。)
如公司想推出一款高端男性運動產品,則可能的圈選條件為:
1.男性,推出產品的受眾群體為男性。
2.運動愛好者,運動愛好者更有可能消費運動類產品。
3.一線城市,一線城市用戶相比於二三線城市用戶,可能更傾向於消費高端產品。
4....
從上述表結構(人群圈選典型表結構,且大都如此,第一列為用戶id,其餘皆為標籤列)和查詢條件可以看出,人群圈選業務都面臨一些共同的痛點:
• 用戶標籤多、標籤豐富,標籤列可達成百甚至上千列。
• 數據量龐大,用戶數多,從而所需運算量也極大。
• 圈選條件組合多樣化,沒有固定索引可以優化,存儲空間佔用極大。
• 性能要求高,圈選結果要求及時響應,過長的延時會造成營銷人群的不準確。
• 數據更新時效要求高,用戶畫像要求近實時的更新,過期的人群信息也將直接影響圈選的精準性。
針對以上痛點,本文將從原理層面深度分析,多角度對比講解如何使用ClickHouse搭建人群圈選系統,為何選擇ClickHouse,以及選用ClickHouse搭建人群圈選系統的優勢。
為什麼選擇ClickHouse
本文以開ElasticSearch(ES)為例,僅針對人群圈選場景與ClickHouse做對比。開源版ES是一款高效的搜索分析引擎,利用其優秀的索引技術,可以完成各種複雜的條件組合和數據聚合運算。ClickHouse是最近比較火的一款開源列式存儲分析型數據庫,它最核心的特點就是極致存儲壓縮率和查詢性能,尤其擅長單個大寬表的查詢場景。因此細比兩者,相較與ClickHouse,ES雖具備人群圈選業務所需的必要能力,但仍有以下3方面不足:
成本方面:
開源ES的底層存儲使用lucene,主要包含行存儲(storefiled),列存儲(docvalues)和倒排索引(invertindex)。行存中_source字段用於控制doc原始數據的存儲。在寫入數據時,ES把doc原始數據的整個json結構體當做一個string,存儲為_source字段,因此_source字段對存儲佔用量大且關閉_source將不支持update操作。同時,索引也是ES不可缺少的一部分,ES默認全列索引,雖可手動設置對特定的列取消索引,但取消索引的列將不可查詢。在人群圈選場景下,選取標籤過濾條件是任意的,多樣的,不斷變化的。對任意一條標籤列不做索引都是不現實的,因此針對成百上千列的大寬表,全列索引必然使得存儲成本翻倍。
ClickHouse是一款徹底的列式存儲數據庫,且ClickHouse的查詢不依賴索引,使用過程中也不強制構建索引,因此不需要保留額外的索引文件。同時ClickHouse存儲數據的副本數量靈活可配,可將使用成本降至最低。
數據更新與治理方面:
索引為ES帶來了高效的查詢性能,但是索引的構造過程是複雜的,耗時的。每一次索引的構建都需對全列數據進行掃描,排序來生成索引文件。而在人群圈選業務中,人群信息必然是不斷增長的。標籤的不斷更新將會使得ES不得不頻繁的重構索引,這將對ES的性能造成巨大的開銷 。
ClickHouse的查詢不依賴索引,使用過程中也不強制構建索引。因此對於新增數據,ClickHouse不涉及索引的更新與維護。
易用性方面:
開源ES缺少完備的sql支持,查詢請求的json格式複雜。同時ES對多條件過濾聚合的執行策略缺少優化,還以文章開頭的典型場景為例,圈出一款高端男性運動產品的受眾人群。可得如下sql:“SELECT user_id FROM whatever_table WHERE city_level = '一線城市' AND gender = '男性' AND is_like_sports = '是';”
針對以上sql,ES的執行會對3個標籤分別做3次索引掃描,之後再將3次掃描的結果做merge,流程如下圖所示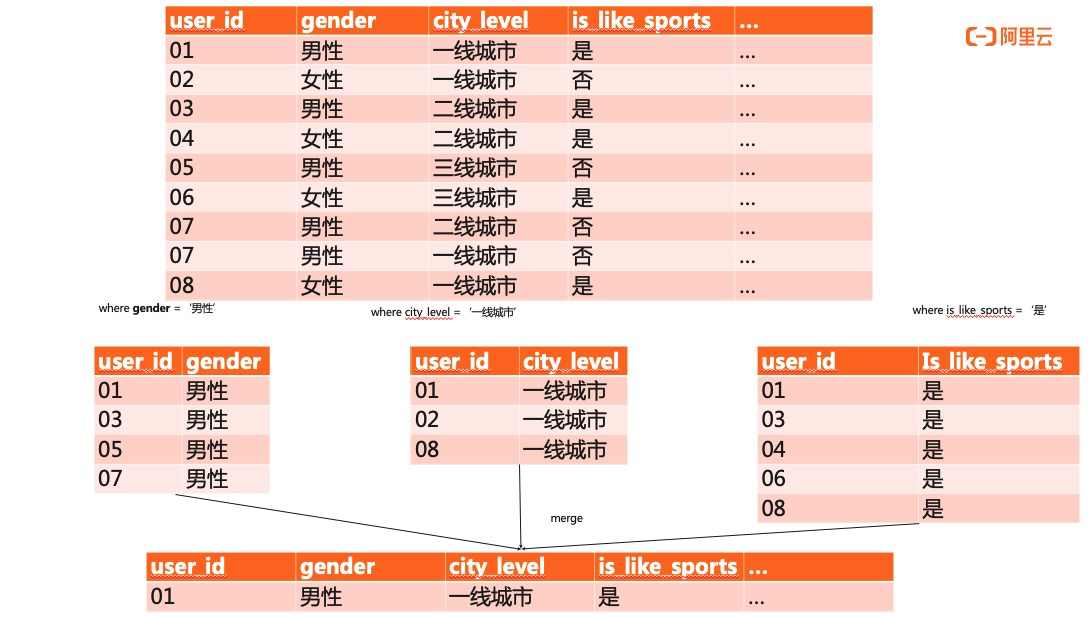
而ClickHouse的執行則更優雅一些。ClickHouse採用標準sql,語法簡單且功能強大。在執行where語句時,會自動優化形成prewhere分層執行,因此二次掃描將基於一次掃描的結果進行,執行流程如下圖所示:
顯而易見,針對複雜條件過濾的場景,ClickHouse對多條件篩選流程做出優化,掃描的數據量更小,性能也較ES而言更高效。
如何基於ClickHouse搭建人群圈選系統:
對比選型完成後,接下來講解如何基於ClickHouse搭建人群圈選系統,回顧文章開頭的業務描述和上一部分的典型sql(“SELECT user_id FROM whatever_table WHERE city_level = '一線城市' AND gender = '男性' AND is_like_sports = '是';”),再次總結人群圈選業務對數據庫能力的要求如下:
1.具備高效的批量數據導入性能。
2.具備處理頻繁,實時update的能力。
3.具備加列/減列的DDL能力。
4.可以指定任意列為過濾條件的高效查詢能力。
面對以上需求,ClickHouse如何使用才能在人群圈選場景下物盡其用,揚長避短?
insert代替update
首先要解決的是ClickHouse的異步update機制。ClickHouse對update的執行是低效的,ClickHouse內核中的MergeTree存儲一旦生成一個Data Part,這個Data Part就不可再更改了。所以從MergeTree存儲內核層面,ClickHouse就不擅長做數據更新刪除操作。ClickHouse的語法把Update操作也加入到了Alter Table的範疇中,它並不支持裸的Update操作。ALTER TABLE [db.]table UPDATE column1 = expr1 [, ...] WHERE filter_expr;
當用戶執行一個如上的Update操作獲得返回時,ClickHouse內核其實只做了兩件事情:
1.檢查Update操作是否合法;
2.保存Update命令到存儲文件中,喚醒一個異步處理merge和mutation的工作線程;異步線程的工作流程極其複雜,總結其精髓描述如下:先查找到需要update的數據所在datapart,之後對整個datapart做掃描,更新需要變更的數據,然後再將數據重新落盤生成新的datapart,最後用新的datapart做替代並remove掉過期的datapart。
這就是ClickHouse對update指令的執行過程,可以看出,頻繁的update指令對於ClickHouse來說將是災難性的。
因此,我們使用insert語句代替update語句。當需要對某一指定user更新標籤時,就重新插入一條該user的數據,
如對錶中07號用戶進行數據更新:
最終,每個user可能都存在多條記錄。針對人群圈選場景,同一user錯亂冗餘的信息顯然對查詢結果產生誤導,無法滿足精準圈選的需求。接下來講解如何使用ClickHouse進行主鍵去重,即同一user,讓後insert進來的數據覆蓋掉已有的數據,實現update的效果。
選用AggregatingMergeTree表引擎
MergeTree是ClickHouse中最重要,最核心的存儲內核,MergeTree思想上與LSM-Tree相似,其實現原理複雜,不在此展開,因為一篇文章也難以講解清楚。本篇圍繞人群圈選場景,著重從功能層面描述如何在人群圈選場景下使用MergeTree的變種AggregatingMergeTree以及使用AggregatingMergeTree可實現的數據聚合效果。AggregatingMergeTree繼承自 MergeTree,存儲上和基礎的MergeTree其實沒有任何差異,而是在數據Merge的過程中加入了“額外的合併邏輯”, AggregatingMergeTree 會將相同主鍵的所有行(在一個數據片段內)替換為單個存儲一系列聚合函數狀態的行。以文章開頭部分的表結構為例,使用AggregatingMergeTree表引擎的建表語句如下:
CREATE TABLE IF NOT EXISTS whatever_table ON CLUSTER default
(
user_id UInt64,
city_level SimpleAggregateFunction(anyLast, Nullable(Enum('一線城市' = 0, '二線城市' = 1, '三線城市' = 2, '四線城市' = 3))),
gender SimpleAggregateFunction(anyLast, Nullable(Enum('女' = 0, '男' = 1))),
interest_sports SimpleAggregateFunction(anyLast, Nullable(Enum('否' = 0, '是' = 1))),
reg_date SimpleAggregateFunction(anyLast, Datetime),
comment_like_cnt SimpleAggregateFunction(anyLast, Nullable(UInt32)),
last30d_share_cnt SimpleAggregateFunction(anyLast, Nullable(UInt32)),
user_like_consume_trend_type SimpleAggregateFunction(anyLast, Nullable(String)),
province SimpleAggregateFunction(anyLast, Nullable(String)),
last_access_version SimpleAggregateFunction(anyLast, Nullable(String)),
others SimpleAggregateFunction(anyLast,Array(String))
)ENGINE = AggregatingMergeTree() partition by toYYYYMMDD(reg_date) ORDER BY user_id;就以上建標語句展開分析,AggregatingMergeTree會將除主鍵(user)外的其餘列,配合anyLast函數,替換每行數據為一種預聚合狀態。其中anyLast聚合函數聲明聚合策略為保留最後一次的更新數據。
數據一致性保證
上一部分講述瞭如何針對人群圈選場景選擇表引擎和聚合函數,但是AggregatingMergeTree並不能保證任何時候的查詢都是聚合過後的結果,並且也沒有提供標誌位用於查詢數據的聚合狀態與進度。因此,為了確保數據在查詢前處於已聚合的狀態,還需手動下發optimize指令強制聚合過程的執行。同時方便起見,可自行配置週期性optimize指令的下發。例如每10分鐘執行一次optimize指令。optimize的執行週期可在業務的實時性需求與計算資源之間做權衡。如數據量過大,optimize生效慢,可按partition級別並行下發做優化。optimize生效後即可實現去重邏輯。
Demo:
import java.sql.*;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.concurrent.TimeoutException;
public class Main {
private static final String DATE_FORMAT = "yyyy-MM-dd HH:mm:ss";
private static final SimpleDateFormat SIMPLE_DATE_FORMAT = new SimpleDateFormat(DATE_FORMAT);
public static void main(String[] args) throws ClassNotFoundException, SQLException, InterruptedException, ParseException {
String url = "your url";
String username = "your username";
String password = "your password";
Class.forName("ru.yandex.clickhouse.ClickHouseDriver");
String connectionStr = "jdbc:clickhouse://" + url + ":8123";
try {
Connection connection = DriverManager.getConnection(connectionStr, username, password);
Statement stmt = connection.createStatement();
// 創建local表
String createLocalTableDDL = "CREATE TABLE IF NOT EXISTS whatever_table ON CLUSTER default " +
"(user_id UInt64, " +
"city_level SimpleAggregateFunction(anyLast, Nullable(Enum('一線城市' = 0, '二線城市' = 1, '三線城市' = 2, '四線城市' = 3))), " +
"gender SimpleAggregateFunction(anyLast, Nullable(Enum('女' = 0, '男' = 1)))," +
"interest_sports SimpleAggregateFunction(anyLast, Nullable(Enum('否' = 0, '是' = 1)))," +
"reg_date SimpleAggregateFunction(anyLast, Datetime)) " +
"comment_like_cnt SimpleAggregateFunction(anyLast, Nullable(UInt32)),\n" +
"last30d_share_cnt SimpleAggregateFunction(anyLast, Nullable(UInt32)),\n" +
"user_like_consume_trend_type SimpleAggregateFunction(anyLast, Nullable(String)),\n" +
"province SimpleAggregateFunction(anyLast, Nullable(String)),\n" +
"last_access_version SimpleAggregateFunction(anyLast, Nullable(String)),\n" +
"others SimpleAggregateFunction(anyLast, Array(String)),\n" +
"ENGINE = AggregatingMergeTree() PARTITION by toYYYYMM(reg_date) ORDER BY user_id;";
stmt.execute(createLocalTableDDL);
System.out.println("create local table done.");
// 創建distributed表
String createDistributedTableDDL = "CREATE TABLE IF NOT EXISTS whatever_table_dist ON cluster default " +
"AS default.whatever_table " +
"ENGINE = Distributed(default, default, whatever_table, intHash64(user_id));";
stmt.execute(createDistributedTableDDL);
System.out.println("create distributed table done");
// 插入mock數據
String insertSQL = "INSERT INTO whatever_table(\n" +
"\tuser_id,\n" +
"\tcity_level,\n" +
"\tgender,\n" +
"\tinterest_sports,\n" +
"\treg_date,\n" +
"\tcomment_like_cnt,\n" +
"\tlast30d_share_cnt,\n" +
"\tuser_like_consume_trend_type,\n" +
"\tprovince,\n" +
"\tlast_access_version,\n" +
"\tothers\n" +
"\t)SELECT\n" +
" number as user_id,\n" +
" toUInt32(rand(11)%4) as city_level,\n" +
" toUInt32(rand(30)%2) as gender,\n" +
" toUInt32(rand(28)%2) as interest_sports,\n" +
" (toDateTime('2020-01-01 00:00:00') + rand(1)%(3600*24*30*4)) as reg_date,\n" +
" toUInt32(rand(15)%10) as comment_like_cnt,\n" +
" toUInt32(rand(16)%10) as last30d_share_cnt,\n" +
"randomPrintableASCII(64) as user_like_consume_trend_type,\n" +
"randomPrintableASCII(64) as province,\n" +
"randomPrintableASCII(64) as last_access_version,\n" +
"[randomPrintableASCII(64)] as others\n" +
" FROM numbers(100000);\n";
stmt.execute(insertSQL);
System.out.println("Mock data and insert done.");
System.out.println("Select count(user_id)...");
ResultSet rs = stmt.executeQuery("select count(user_id) from whatever_table_dist");
while (rs.next()) {
int count = rs.getInt(1);
System.out.println("user_id count: " + count);
}
// 數據合併
String optimizeSQL = "OPTIMIZE table whatever_table final;";
// 如數據合併時間過長,可在partition級別並行執行
String optimizeByPartitionSQL = "OPTIMIZE table whatever_table PARTITION 202001 final;";
try {
stmt.execute(optimizeByPartitionSQL);
}catch (SQLTimeoutException e){
// 查看merge進展
// String checkMergeSQL = "select * from system.merges where database = 'default' and table = 'whatever_table';";
Thread.sleep(60*1000);
}
// 人群圈選(city_level='一線城市',gender='男性',interest_sports='是', reg_date<='2020-01-31 23:59:59')
String selectSQL = "SELECT user_id from whatever_table_dist where city_level=0 and gender=1 and interest_sports=1 and reg_date <= NOW();";
rs = stmt.executeQuery(selectSQL);
while (rs.next()) {
int user_id = rs.getInt(1);
System.out.println("Got suitable user: " + user_id);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}寫在最後
阿里雲已經推出了ClickHouse的雲託管產品,產品首頁地址:雲數據庫ClickHouse,歡迎大家試用,對Clickhouse感興趣的也可加入Clickhouse技術交流群。