整理 | Aven (Flink 社區志願者)
摘要:本文由 Apache Flink Committer,字節跳動架構研發工程師李本超分享,以四個章節來介紹 Flink 在字節的應用實戰。 內容如下:
- 整體介紹
- 實踐優化
- 流批一體
- 未來規劃
一、整體介紹

2018 年 12 月 Blink 宣佈開源,經歷了約一年的時間 Flink 1.9 於 2019 年 8 月 22 發佈。在 Flink 1.9 發佈之前字節跳動內部基於 master 分支進行內部的 SQL 平臺構建。經歷了 2~3 個月的時間字節內部在 19 年 10 月份發佈了基於 Flink 1.9 的 Blink planner 構建的 Streaming SQL 平臺,並進行內部推廣。在這個過程中發現了一些比較有意思的需求場景,以及一些較為奇怪的 BUG。
基於 1.9 的 Flink SQL 擴展
雖然最新的 Flink 版本已經支持 SQL 的 DDL,但 Flink 1.9 並不支持。字節內部基於 Flink 1.9 進行了 DDL 的擴展支持以下語法:
- create table
- create view
- create function
- add resource
同時 Flink 1.9 版本不支持的 watermark 定義在 DDL 擴展後也支持了。
我們在推薦大家儘量的去用 SQL 表達作業時收到很多“SQL 無法表達複雜的業務邏輯”的反饋。時間久了發現其實很多用戶所謂的複雜業務邏輯有的是做一些外部的 RPC 調用,字節內部針對這個場景做了一個 RPC 的維表和 sink,讓用戶可以去讀寫 RPC 服務,極大的擴展了 SQL 的使用場景,包括 FaaS 其實跟 RPC 也是類似的。在字節內部添加了 Redis/Abase/Bytable/ByteSQL/RPC/FaaS 等維表的支持。
同時還實現了多個內部使用的 connectors:
- source: RocketMQ
- sink:
RocketMQ/ClickHouse/Doris/LogHouse/Redis/Abase/Bytable/ByteSQL/RPC/Print/Metrics
並且為 connector 開發了配套的 format:PB/Binlog/Bytes。
在線的界面化 SQL 平臺
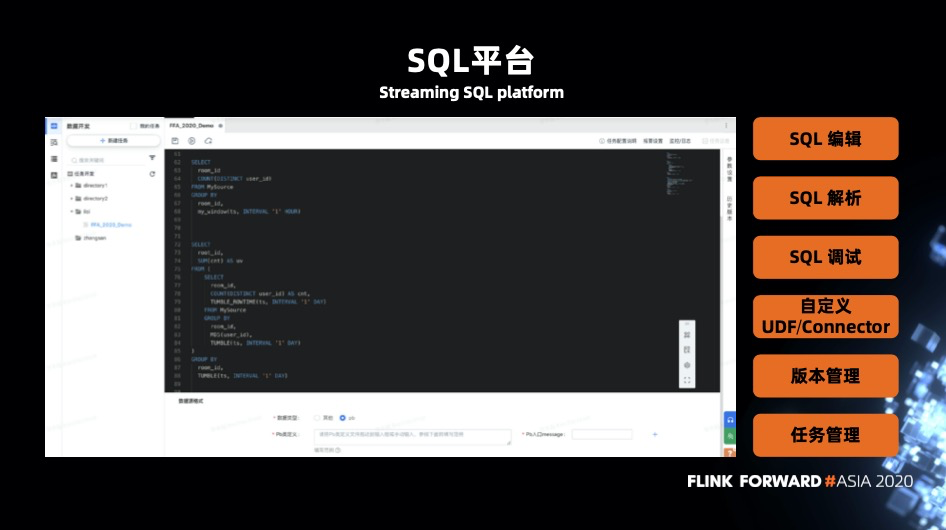
除了對 Flink 本身功能的擴展,字節內部也上線了一個 SQL 平臺,支持以下功能:
- SQL 編輯
- SQL 解析
- SQL 調試
- 自定義 UDF 和 Connector
- 版本控制
- 任務管理
二、實踐優化
除了對功能的擴展,針對 Flink 1.9 SQL 的不足之處也做了一些優化。
Window 性能優化
1、支持了 window Mini-Batch
Mini-Batch 是 Blink planner 的一個比較有特色的功能,其主要思想是積攢一批數據,再進行一次狀態訪問,達到減少訪問狀態的次數降低序列化反序列化的開銷。這個優化主要是在 RocksDB 的場景。如果是 Heap 狀態 Mini-Batch 並沒什麼優化。在一些典型的業務場景中,得到的反饋是能減少 20~30% 左右的 CPU 開銷。
2、擴展 window 類型
目前 SQL 中的三種內置 window,滾動窗口、滑動窗口、session 窗口,這三種語意的窗口無法滿足一些用戶場景的需求。比如在直播的場景,分析師想統計一個主播在開播之後,每一個小時的 UV(Unique Visitor)、GMV(Gross Merchandise Volume) 等指標。自然的滾動窗口的劃分方式並不能夠滿足用戶的需求,字節內部就做了一些定製的窗口來滿足用戶的一些共性需求。
-- my_window 為自定義的窗口,滿足特定的劃分方式
SELECT
room_id,
COUNT(DISTINCT user_id)
FROM MySource
GROUP BY
room_id,
my_window(ts, INTERVAL '1' HOURS)3、window offset
這是一個較為通用的功能,在 Datastream API 層是支持的,但 SQL 中並沒有。這裡有個比較有意思的場景,用戶想要開一週的窗口,一週的窗口變成了從週四開始的非自然周。因為誰也不會想到 1970 年 1 月 1 號那天居然是週四。在加入了 offset 的支持後就可以支持正確的自然周窗口。
SELECT
room_id,
COUNT(DISTINCT user_id)
FROM MySource
GROUP BY
room_id,
TUMBLE(ts, INTERVAL '7' DAY, INTERVAL '3', DAY)維表優化
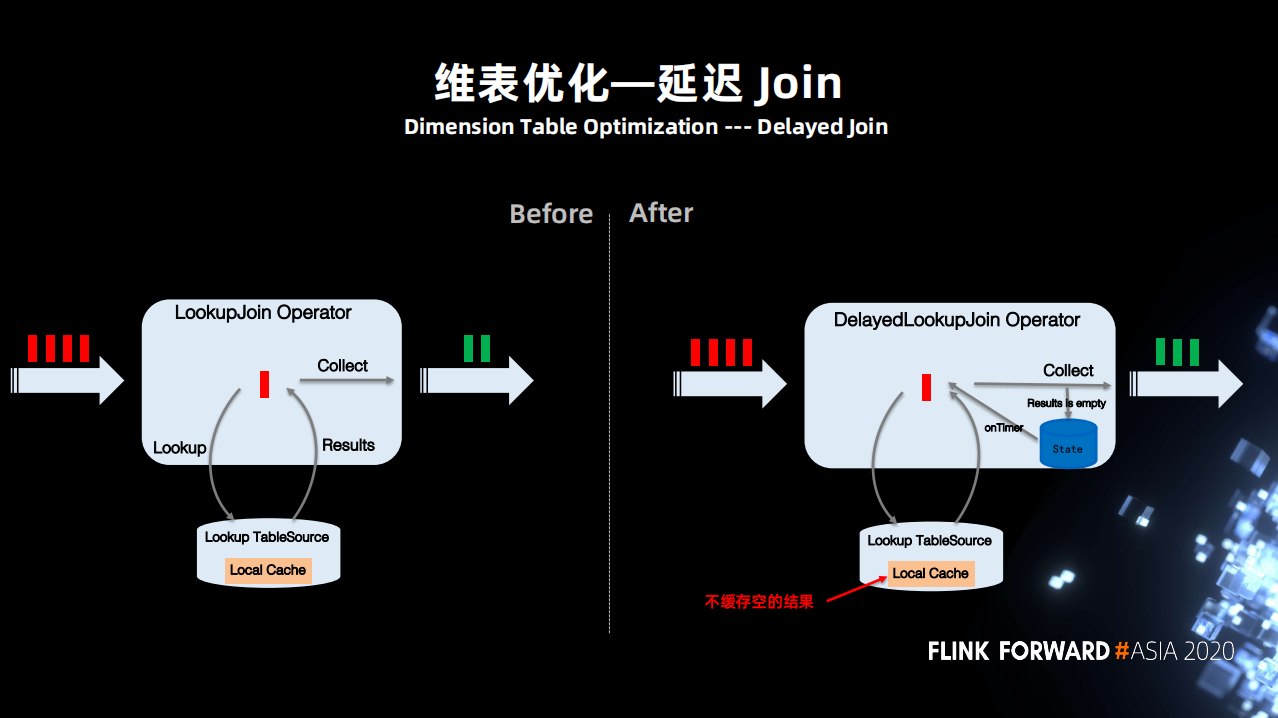
1、延遲 Join
維表 Join 的場景下因為維表經常發生變化尤其是新增維度,而 Join 操作發生在維度新增之前,經常導致關聯不上。
所以用戶希望如果 Join 不到,則暫時將數據緩存起來之後再進行嘗試,並且可以控制嘗試次數,能夠自定義延遲 Join 的規則。這個需求場景不單單在字節內部,社區的很多同學也有類似的需求。
基於上面的場景實現了延遲 Join 功能,添加了一個可以支持延遲 Join 維表的算子。當 Join 沒有命中,local cache 不會緩存空的結果,同時將數據暫時保存在一個狀態中,之後根據設置定時器以及它的重試次數進行重試。
2、維表 Keyby 功能

通過拓撲我們發現 Cacl 算子和 lookUpJoin 算子是 chain 在一起的。因為它沒有一個 key 的語義。
當作業並行度比較大,每一個維表 Join 的 subtask,訪問的是所有的緩存空間,這樣對緩存來說有很大的壓力。
但觀察 Join 的 SQL,等值 Join 是天然具有 Hash 屬性的。直接開放了配置,運行用戶直接把維表 Join 的 key 作為 Hash 的條件,將數據進行分區。這樣就能保證下游每一個算子的 subtask 之間的訪問空間是獨立的,這樣可以大大的提升開始的緩存命中率。
除了以上的優化,還有兩點目前正在開發的維表優化。
1、廣播維表:有些場景下維表比較小,而且更新不頻繁,但作業的 QPS 特別高。如果依然訪問外部系統進行 Join,那麼壓力會非常大。並且當作業 Failover 的時候 local cache 會全部失效,進而又對外部系統造成很大訪問壓力。那麼改進的方案是定期全量 scan 維表,通過Join key hash 的方式發送到下游,更新每個維表 subtask 的緩存。
2、Mini-Batch:主要針對一些 I/O 請求比較高,系統又支持 batch 請求的能力,比如說 RPC、HBase、Redis 等。以往的方式都是逐條的請求,且 Async I/O 只能解決 I/O 延遲的問題,並不能解決訪問量的問題。通過實現 Mini-Batch 版本的維表算子,大量降低維表關聯訪問外部存儲次數。
Join 優化
目前 Flink 支持的三種 Join 方式;分別是 Interval Join、Regular Join、Temporal Table Function。
前兩種語義是一樣的流和流 Join。而 Temporal Table 是流和表的的 Join,右邊的流會以主鍵的形式形成一張表,左邊的流去 Join 這張表,這樣一次 Join 只能有一條數據參與並且只返回一個結果。而不是有多少條都能 Join 到。
它們之間的區別列了幾點:
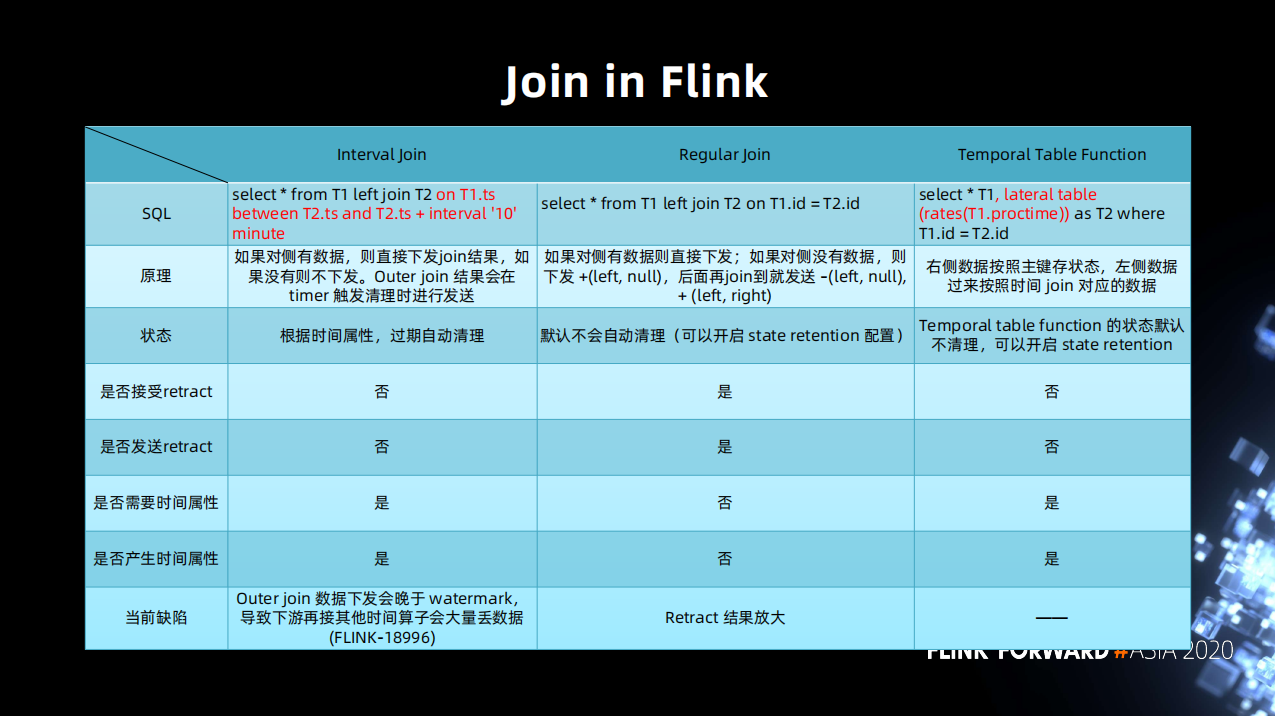
可以看到三種 Join 方式都有它本身的一些缺陷。
- Interval Join 目前使用上的缺陷是它會產生一個 out join 數據和 watermark 亂序的情況。
- Regular Join 的話,它最大的缺陷是 retract 放大(之後會詳細說明這個問題)。
- Temporal table function 的問題較其它多一些,有三個問題。
- 不支持 DDl
- 不支持 out join 的語義 (FLINK-7865 的限制)
- 右側數據斷流導致 watermark 不更新,下游無法正確計算 (FLINK-18934)
對於以上的不足之處字節內部都做了對應的修改。
增強 Checkpoint 恢復能力
對於 SQL 作業來說一旦發生條件變化都很難從 checkpoint 中恢復。
SQL 作業確實從 checkpoint 恢復的能力比較弱,因為有時候做一些看起來不太影響 checkpoint 的修改,它仍然無法恢復。無法恢復主要有兩點;
- 第一點:operate ID 是自動生成的,然後因為某些原因導致它生成的 ID 改變了。
- 第二點:算子的計算的邏輯發生了改變,即算子內部的狀態的定義發生了變化。
例子1:並行度發生修改導致無法恢復。

source 是一個最常見的有狀態的算子,source 如果和之後的算子的 operator chain 邏輯發生了改變,是完全無法恢復的。
下圖左上是正常的社區版的作業會產生的一個邏輯, source 和後面的並行度一樣的算子會被 chain 在一起,用戶是無法去改變的。但算子並行度是常會會發生修改,比如說 source 由原來的 100 修改為 50,cacl 的併發是 100。此時 chain 的邏輯就會發生變化。
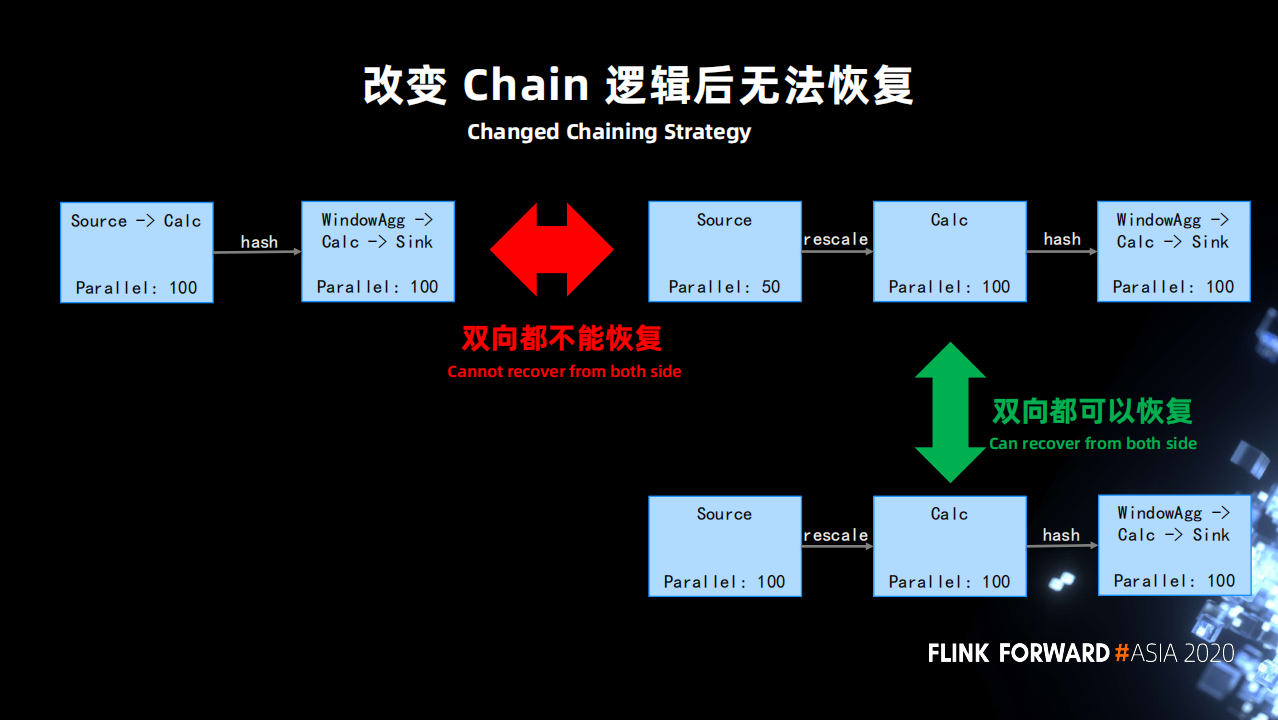
針對這種情況,字節內部做了修改,允許用戶去配置,即使 source 的並行度跟後面整體的作業的並行度是一樣的,也讓其不與之後的算子 chain 在一起。
例子2:DAG 改變導致無法恢復。
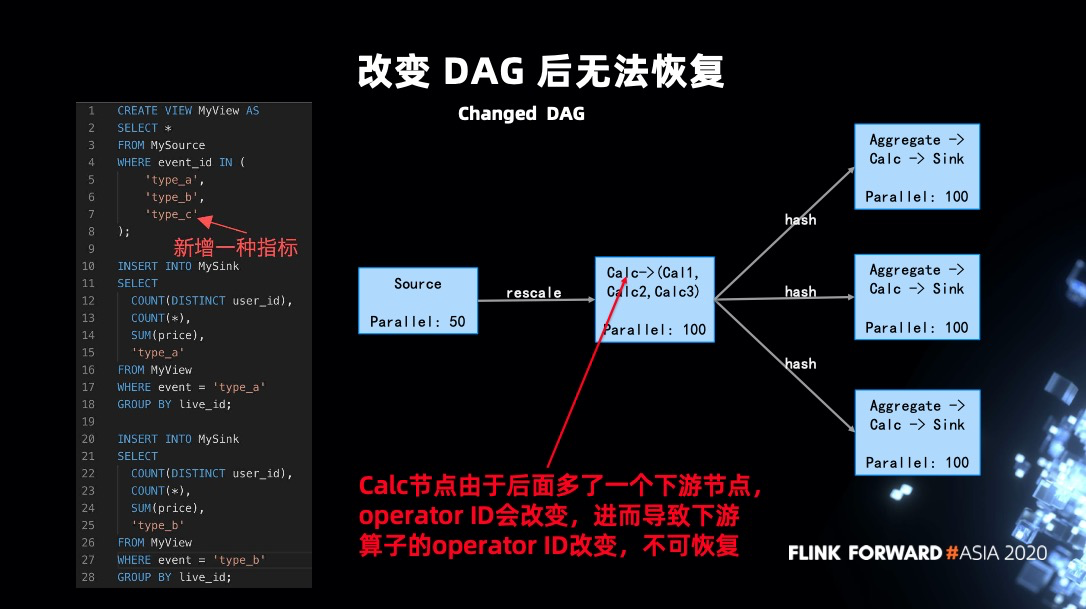
這是一種比較特殊的情況,有一條 SQL (上圖),可以看到 source 沒有發生變化,之後的三個聚合互相之間沒有關係,狀態竟然也是無法恢復。
作業之所以無法恢復,是因為 operator ID 生成規則導致的。目前 SQL 中 operator ID 的生成的規則與上游、本身配置以及下游可以 chain 在一起的算子的數量都有關係。 因為新增指標,會導致新增一個 Calc 的下游節點,進而導致 operator ID 發生變化。
為了處理這種情況,支持了一種特殊的配置模式,允許用戶配置生成 operator ID 的時候可以忽略下游 chain 在一起算子數量的條件。
例子3:新增聚合指標導致無法恢復
這塊是用戶訴求最大的,也是最複雜的部分。用戶期望新增一些聚合指標後,原來的指標要能從 checkpoint 中恢復。
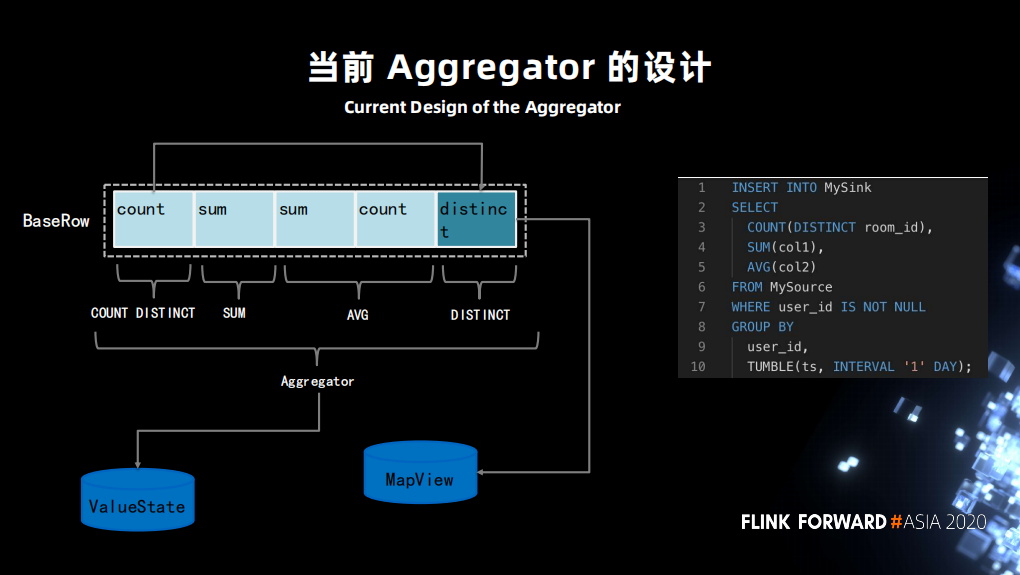
可以看到圖中左部分是 SQL 生成的算子邏輯。count,sum,sum,count,distinct 會以一個 BaseRow 的結構存儲在 ValueState 中。distinct 比較特殊一些,還會單獨存儲在一個 MapState 中。
這導致瞭如新增或者減少指標,都會使原先的狀態沒辦法從 ValueState 中正常恢復,因為 VauleState 中存儲的狀態 “schema” 和新的(修改指標後)的 “schema”不匹配,無法正常反序列化。
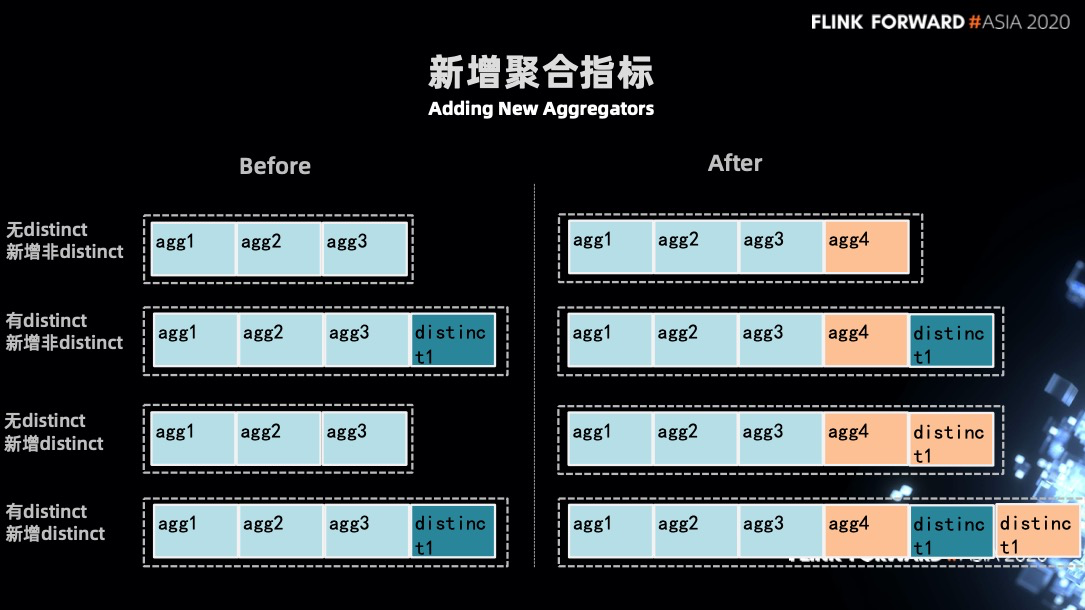
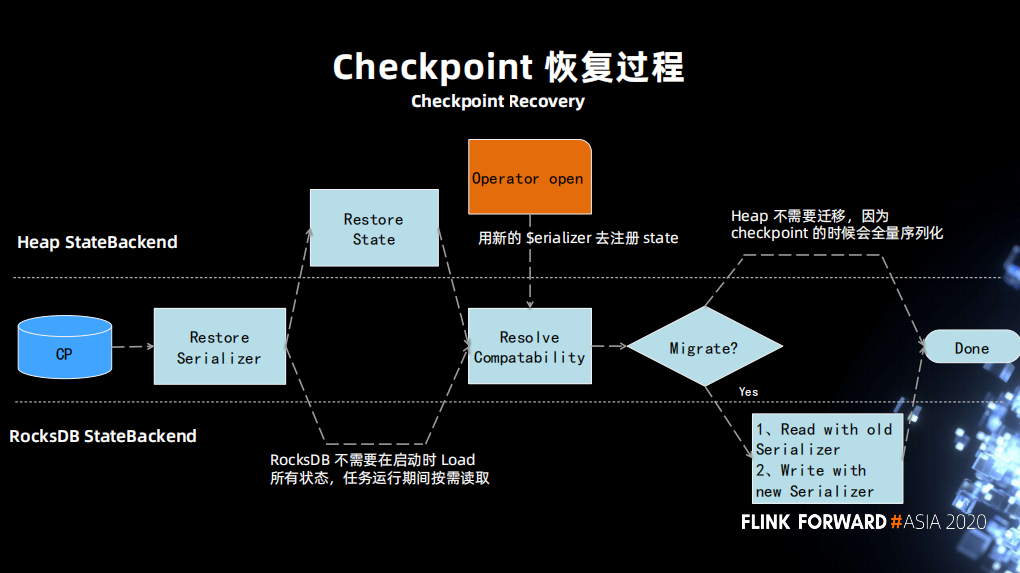
在討論解決方案之前,我們先回顧一下正常的恢復流。先從 checkpoint 中恢復出狀態的 serializer,再通過 serializer 把狀態恢復。接下來 operator 去註冊新的狀態定義,新的狀態定義會和原先的狀態定義進行一個兼容性對比,如果是兼容則狀態恢復成功,如果不兼容則拋出異常任務失敗。
不兼容的另一種處理情況是允許返回一個 migration(實現兩個不匹配類型的狀態恢復)那麼也可以恢復成功。
針對上面的流程做出對應的修改:
- 第一步使新舊 serializer 互相知道對方的信息,添加一個接口,且修改了 statebackend resolve compatibility 的過程,把舊的信息傳遞給新的,並使其獲取整個 migrate 過程。
- 第二步判斷新老之間是否兼容,如果不兼容是否需要做一次 migration。然後讓舊的 serializer 去恢復一遍狀態,並使用新的 serializer 寫入新的狀態。
- 對 aggregation 的代碼生成進行處理,當發現 aggregation 拿到的是指標是 null,那麼將做一些初始化的工作。
通過以上的修改基本就可以做到正常的,新增的聚合指標從拆開的方案恢復。
三、流批一體探索
業務現狀
字節跳動內部對流批一體和業務推廣之前,技術團隊提前做了大量技術方面的探索。整體判斷是 SQL 這一層是可以做到流批一體的語義,但實踐中卻又發現不少不同。
比如說流計算的 session window,或是基於處理時間的 window,在批計算中無法做到。同時 SQL 在批計算中一些複雜的 over window,在流計算中也沒有對應的實現。
但這些特別的場景可能只佔 10% 甚至更少,所以用 SQL 去落實流批一體是可行的。
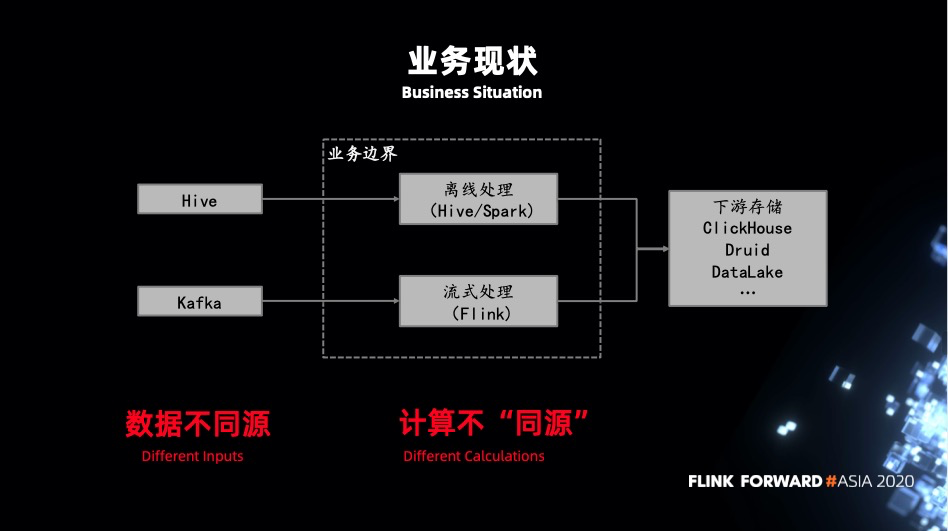
流批一體
這張圖是比較常見的和大多數公司裡的架構都類似。這種架構有什麼缺陷呢?
- 數據不同源:批任務一般會有一次前置處理任務,不管是離線的也好實時的也好,預先進過一層加工後寫入 Hive。而實時任務是從 kafka 讀取原始的數據,可能是 json 格式,也可能是 avro 等等。直接導致批任務中可執行的 SQL 在流任務中沒有結果生成或者執行結果不對。
- 計算不同源:批任務一般是 Hive + Spark 的架構,而流任務基本都是基於 Flink。不同的執行引擎在實現上都會有一些差異,導致結果不一致。不同的執行引擎有不同的 API 定義 UDF,它們之間也是無法被公用的。大部分情況下都是維護兩套基於不同 API 實現的相同功能的 UDF。
鑑於上面的問題,提出了基於 Flink 的流批一體架構來解決。
- 數據不同源:流式處理先通過 Flink 處理之後寫入 MQ 供下游流式 Flink job 去消費,對於批式處理由 Flink 處理後流式寫入到 Hive,再由批式的 Flink job 去處理。
- 引擎不同源:既然都是基於 Flink 開發的流式,批式 job,自然沒有計算不同源問題,同時也避免了維護多套相同功能的 UDF。
基於 Flink 實現的流批一體架構:
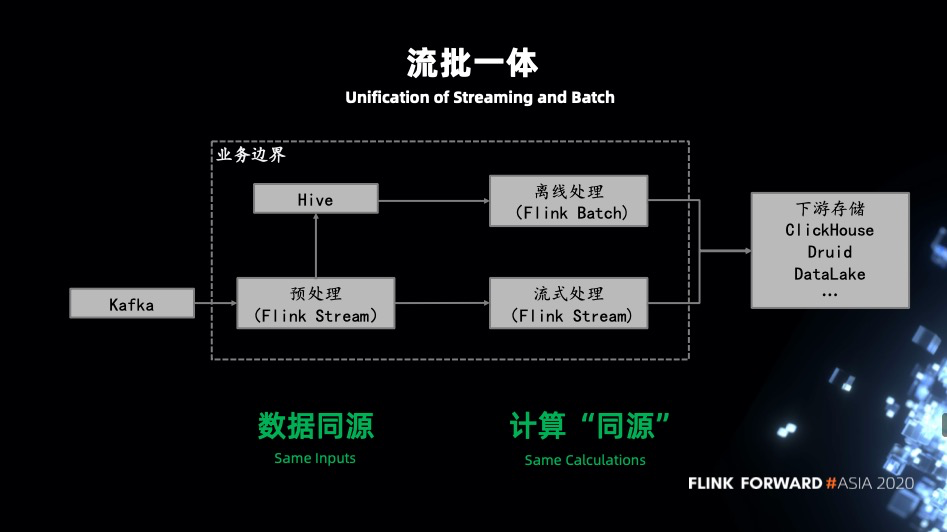
業務收益
- 統一的 SQL:通過一套 SQL 來表達流和批計算兩種場景,減少開發維護工作。
- 複用 UDF:流式和批式計算可以共用一套 UDF。這對業務來說是有積極意義的。
- 引擎統一:對於業務的學習成本和架構的維護成本都會降低很多。
- 優化統一:大部分的優化都是可以同時作用在流式和批式計算上,比如對 planner、operator 的優化流和批可以共享。
四、未來工作和規劃
優化 retract 放大問題

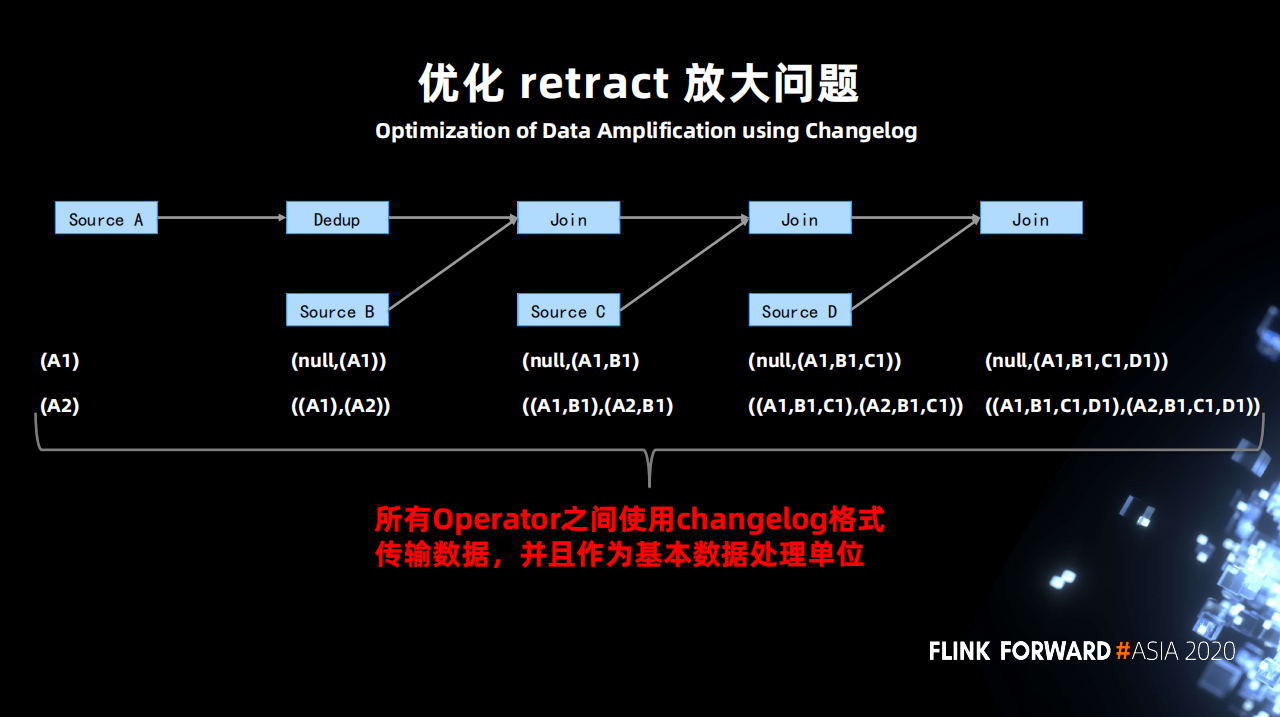
什麼是 retract 放大?
上圖有 4 張表,第一張表進行去重操作 (Dedup),之後分別和另外三張表做 Join。邏輯比較簡單,表 A 輸入(A1),最後產出 (A1,B1,C1,D1) 的結果。
當表 A 輸入一個 A2,因為 Dedup 算子,導致數據需要去重,則向下遊發送一個撤回 A1 的操作 -(A1) 和一個新增 A2 的操作 +(A2)。第一個 Join 算子收到 -(A1) 後會將 -(A1) 變成 -(A1,B1) 和 +(null,B1)(為了保持它認為的正確語義) 發送到下游。之後又收到了 +(A2) ,則又向下遊發送 -(null,B1) 和 +(A2,B1) 這樣操作就放大了兩倍。再經由下游的算子操作會一直被放大,到最終的 sink 輸出可能會被放大 1000 倍之多。
如何解決?
將原先 retract 的兩條數據變成一條 changelog 的格式數據,在算子之間傳遞。算子接收到 changelog 後處理變更,然後僅僅向下遊發送一個變更 changelog 即可。
未來規劃

1.功能優化
- 支持所有類型聚合指標變更的 checkpoint 恢復能力
- window local-global
- 事件時間的 Fast Emit
- 廣播維表
- 更多算子的 Mini-Batch 支持:維表,TopN,Join 等
- 全面兼容 Hive SQL 語法
2.業務擴展
- 進一步推動流式 SQL 達到 80%
- 探索落地流批一體產品形態
- 推動實時數倉標準化
