本文由美團研究員、實時計算負責人鞠大升分享,主要介紹 Flink 助力美團數倉增量生產的應用實踐。內容包括:
- 數倉增量生產
- 流式數據集成
- 流式數據處理
- 流式 OLAP 應用
- 未來規劃
一、數倉增量生產
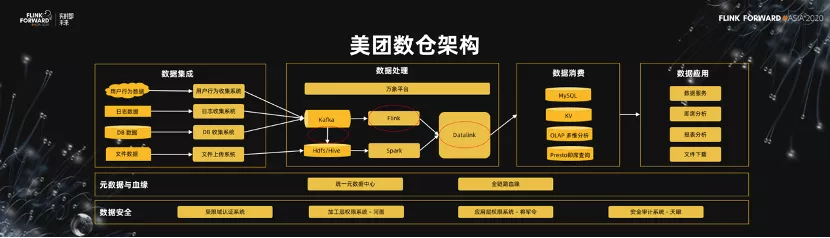
1.美團數倉架構
先介紹一下美團數倉的架構以及增量生產。如下圖所示,這是美團數倉的簡單架構,我把它叫做三橫四縱。所謂三橫,第一是貫穿全鏈路的元數據以及血緣,貫穿數據集成、數據處理、數據消費、以及數據應用的全過程鏈路。另外一塊貫穿全鏈路的是數據安全,包括受限域的認證系統、權限系統、整體的審計系統。根據數據的流向,我們把數據處理的過程分為數據集成、數據處理、數據消費、以及數據應用這 4 個階段。
在數據集成階段,我們對於公司內部的,比如說用戶行為數據、日誌數據、DB 數據、還有文件數據,都有相應的集成的系統把數據統一到我們的數據處理的存儲中,比如說 Kafka 中。
在數據處理階段,分為流式處理鏈路、批處理鏈路以及基於這套鏈路的數倉工作平臺(萬象平臺)。生產出來的數據,經過 Datalink 導入到消費的存儲中,最終通過應用以不同的形式呈現出來。
我們目前在 Flink 上面應用比較廣泛的地方,包括從 Kafka 把數據導到 Hive,包括實時的處理,數據導出的過程。今天的分享就集中在這些方面。
2.美團 Flink 應用概況
美團的 Flink 目前大概有 6000 臺左右的物理機,支撐了 3 萬左右的作業。我們消費的 Topic 數在 5 萬左右,每天的高峰流量在 1.8 億條每秒這樣的水平上。

3.美團 Flink 應用場景
美團 Flink 主要應用的場景包括四大塊。
- 第一,實時數倉、經營分析、運營分析、實時營銷。
- 第二,推薦、搜索。
- 第三,風控、系統監控。
- 第四,安全審計。

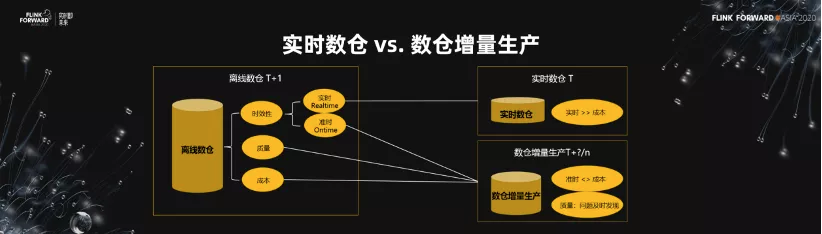
4.實時數倉 vs 數倉增量生產
接下來我要引入增量生產的概念。離線數倉關注的三塊需求,第一個就是時效性。第二個就是質量,產出的數據的質量。第三個就是成本。
關於時效性,有兩個更深層次的含義,第一個叫做實時,第二個叫準時。並不是所有的業務需求都是實時的,很多時候我們的需求是準時。比如做經營分析,每天拿到相應的昨天的經營數據情況即可。實時數倉更多的是解決實時方面的需求。但是在準時這一塊,作為一個企業,更希望在準時跟成本之間做一個權衡。所以,我把數倉的增量生產定義為對離線數倉的一個關於準時跟成本的權衡。另外,數倉增量生產解決比較好的一個方面是質量,問題能夠及時發現。
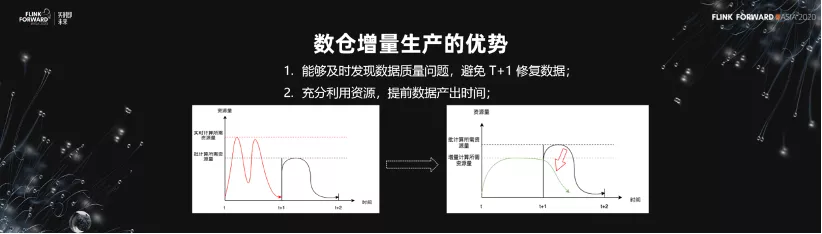
5.數倉增量生產的優勢
數倉增量生產的優勢有兩點。
- 能夠及時發現數據質量問題,避免 T+1 修復數據。
- 充分利用資源,提前數據產出時間。
如下圖所示,我們期望做的實際上是第二幅圖。我們期望把離線的生產佔用的資源降低,但同時希望它的產出時間能夠提前一步。
二、流式數據集成
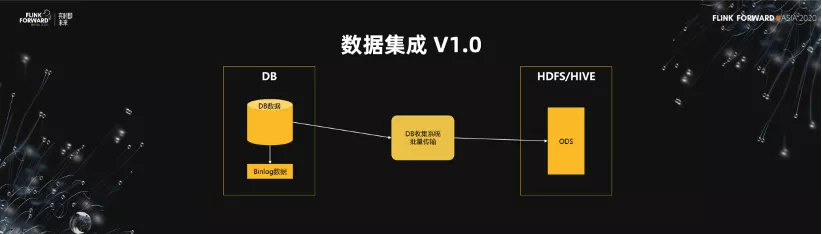
1.數據集成 V1.0
我們來看一下流式數據集成的第一代。當數據量非常小以及庫非常少的時候,直接做一個批的傳輸系統。在每天凌晨的時候把相應的 DB 數據全部 load 一遍,導到數倉裡面。這個架構優勢是非常簡單,易於維護,但是它的缺點也非常明顯,對於一些大的 DB 或者大的數據,load 數據的時間可能需要 2~3 個小時,非常影響離線數倉的產出時間。
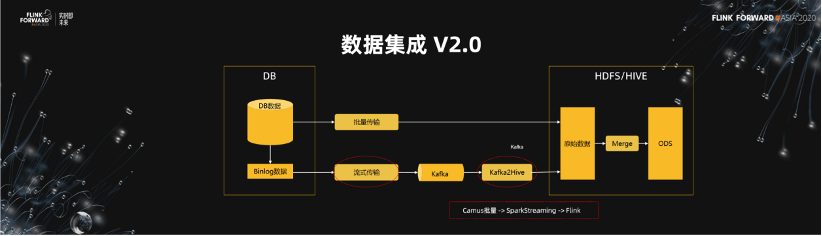
2.數據集成 V2.0
基於這個架構,我們增加了流式傳遞的鏈路,我們會有經過流式傳輸的採集系統把相應的 Binlog 採集到 Kafka,同時會經過一個 Kafka 2 Hive 的程序把它導入到原始數據,再經過一層 Merge,產出下游需要的 ODS 數據。
數據集成 V2.0 的優勢是非常明顯的,我們把數據傳輸的時間放到了 T+0 這一天去做,在第二天的時候只需要去做一次 merge 就可以了。這個時間可能就從 2~3 個小時減少到一個小時了,節省出來的時間是非常可觀的。
3.數據集成 V3.0
在形式上,數據集成的第三代架構前面是沒什麼變化的,因為它本身已經做到了流式的傳輸。關鍵是後面 merge 的流程。每天凌晨 merge 一個小時,仍然是非常浪費時間資源的,甚至對於 HDFS 的壓力都會非常大。所以在這塊,我們就迭代了 HIDI 架構。
這是我們內部基於 HDFS 做的。

4.HIDI
我們設計 HIDI,核心的訴求有四點。第一,支持 Flink 引擎讀寫。第二,通過 MOR 模式支持基於主鍵的 Upsert/Delete。第三,小文件管理 Compaction。第四,支持 Table Schema。

基於這些考慮,我們來對比一下 HIDI,Hudi 和 Iceberg。
HIDI 的優勢包括:
- 支持基於主鍵的 Upsert/Delete
- 支持和 Flink 集成
- 小文件管理 Compaction
劣勢包括:不支持增量讀。
Hudi 的優勢包括:
- 支持基於主鍵的 Upsert/Delete
- 小文件管理 Compaction
劣勢包括:
- 寫入限定 Spark/DeltaStreamer
- 流讀寫支持 SparkStreaming
Iceberg 的優勢包括: 支持和 Flink 集成。
劣勢包括:
- 支持基於 Join 的 Upsert/Delete
- 流式讀取未支持。

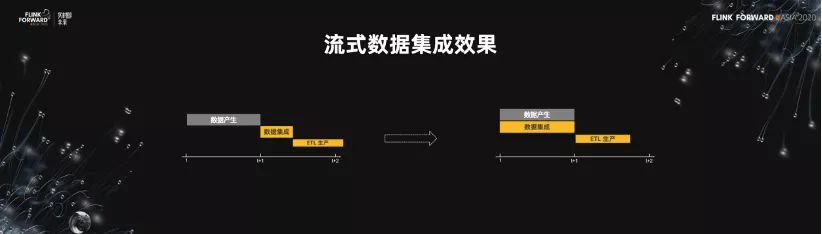
5.流式數據集成效果
如下圖所示,我們有數據產生,數據集成,ETL 生產三個階段。把流式數據集成做到 T+0,ETL 的生產就可以提前了,節省了我們的成本。
三、流式數據處理
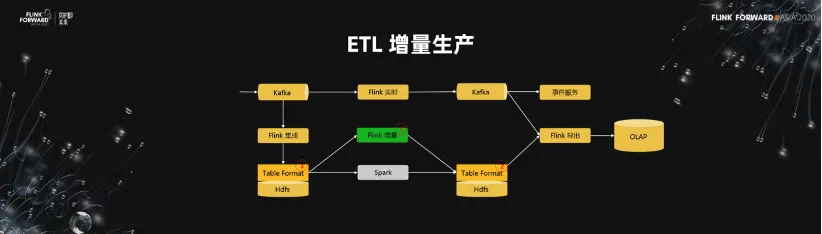
1.ETL 增量生產
我們來講一下 ETL 的增量生產過程。我們的數據從前面進來,到 Kafka 之後,有 Flink 實時,然後到 Kafka,再到事件的服務,甚至到分析的場景中,這是我們自己做的分析鏈路。
下面是批處理的一個鏈路,我們通過 Flink 的集成,集成到 HDFS,然後通過 Spark 去做離線生產,再經過 Flink 把它導出到 OLAP 的應用中。在這樣的架構中,增量的生產實際上就是下圖標記為綠色的部分,我們期望用 Flink 的增量生產的結構去替換掉 Spark。
2.SQL 化是 ETL 增量生產的第一步
這樣的一個架構有三個核心的能力。
- 第一, Flink 的 SQL 的能力要對齊 Spark。
- 第二, 我們的 Table Format 這一層需要能夠支持 Upsert/Delete 這樣的主鍵更新的實時操作。
- 第三, 我們的 Table Format 能夠支持全量和增量的讀取。
我們的全量用於查詢和修復數據,而我們的增量是用來進行增量的生產。SQL 化是 ETL 增量生產的第一步,今天分享的主要是說我們基於 Flink SQL 做的實時數倉平臺對這一塊的支持。

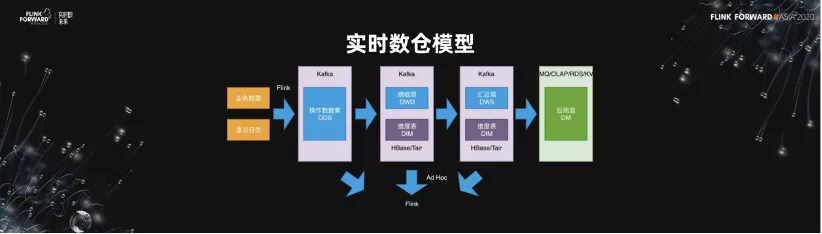
3.實時數倉模型
如下圖所示,這是實時數倉的模型。業界應該都看過這樣的一個模型。
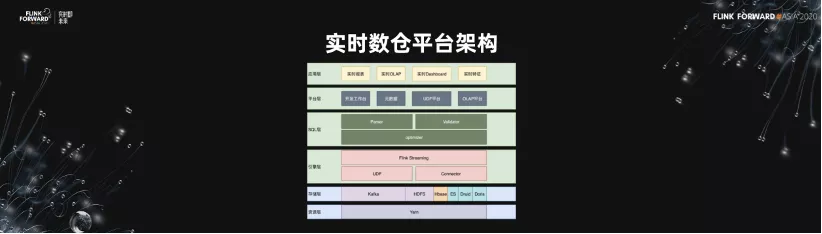
4.實時數倉平臺架構
實時數倉的平臺架構,分為資源層、存儲層、引擎層、SQL 層、平臺層、還有應用層。在這裡重點強調兩點。
- 第一,是對於 UDF 的支持。因為 UDF 是彌補算子能力中的非常重要的一環,我們希望在這裡面做的 UDF 能夠加大對於 SQL 能力的支持。
- 第二,是在這個架構裡面只支持了 Flink Streaming 的能力,我們並沒有去做 Flink 的批處理的能力,因為我們設想未來所有的架構都是基於 streaming 去做的,這跟社區的發展方向也是一致的。
5.實時數倉平臺 Web IDE
這是我們數倉平臺的一個 Web IDE。在這樣的一個 IDE,我們支持了一個 SQL 的建模的過程,支持了 ETL 的開發的能力。
四、流式 OLAP 應用
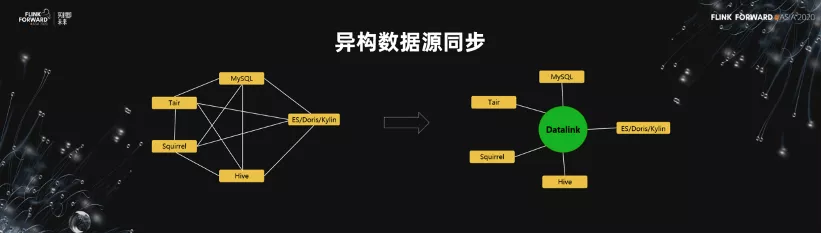
1.異構數據源同步
下面看關於流式的導出跟 OLAP 的應用這一塊。如下圖所示,是異構數據源的同步圖。業界有很多開源的產品做這一塊。比如說,不同的存儲裡面,數據總是在其中進行交換。我們的想法是做一個 Datalink 這樣的一箇中間件,或者是中間的平臺。然後我們把 N 對 N 的數據交換的過程,抽象成一個 N 對 1 的交換過程。
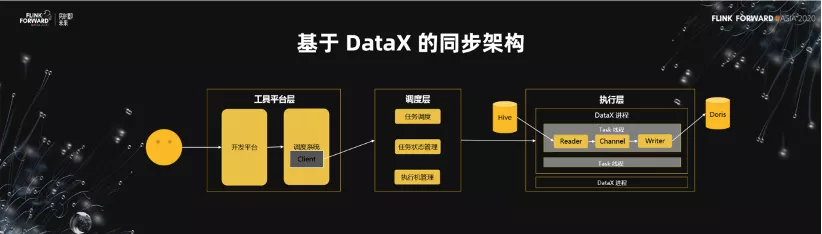
2.基於 DataX 的同步架構
異構數據源的第一版是基於 DataX 來做同步的架構。在這套架構裡面,包含了工具平臺層、調度層、執行層。
- 工具平臺層的任務非常簡單,主要是對接用戶,配置同步任務,配置調度,運維。
- 調度層負責的是任務的調度,當然對於任務的狀態管理,以及執行機的管理,很多的工作都需要我們自己去做。
在真正的執行層,通過 DataX 的進程,以及 Task 多線程的一個形式,真正執行把數據從源同步到目的地。 - 在這樣的一個架構裡面,發現兩個核心的問題。第一個問題就是擴展性的問題。開源的單機版的 DataX 是一個單機多線程的模型,當我們需要傳輸的數據量非常大的時候,單機多線程模型的可擴展性是很大的問題。第二個問題在調度層,我們需要去管理機器、同步的狀態、同步的任務,這個工作非常繁瑣。當我們的調度執行機發生故障的時候,整個災備都需要我們單獨去做這塊的事情。
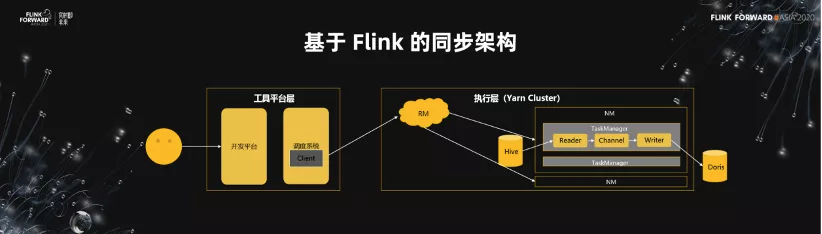
3.基於 Flink 的同步架構
基於這樣的架構,我們把它改成了一個 Flink 的同步的架構。前面不變,還是工具平臺層。在原有的架構裡面,我們把調度層裡面關於任務調度和執行機的管理這一塊都交給了 Yarn 去做,這樣我們就從中解脫出來了。第二個,我們在調度層裡面的任務狀態管理可以直接遷移到 cluster 裡面去。
基於 Flink 的 Datalink 的架構優勢非常明顯。
- 第一, 可擴展性問題得到解決了,同時架構也非常簡單。現在當我們把一個同步的任務拆細之後,它在 TaskManager 裡面可以擴散到分佈式的集群中。
- 第二, 離線跟實時的同步任務,都統一到了 Flink 框架。我們所有同步的 Source 和 Sink 的主鍵,都可以進行共用,這是非常大的一個優勢。
3.基於 Flink 的同步架構關鍵設計
我們看一下基於 Flink 的同步架構的關鍵設計,這裡總結的經驗有四點。
- 第一,避免跨 TaskManager 的 Shuffle,避免不必要的序列化成本;
- 第二,務必設計髒數據收集旁路和失敗反饋機制;
- 第三,利用 Flink 的 Accumulators 對批任務設計優雅退出機制;
- 第四,利用 S3 統一管理 Reader/Writer 插件,分佈式熱加載,提升部署效率。

4.基於 Flink 的 OLAP 生產平臺
基於 Flink 我們做了 Datalink 這樣的一個數據導出的平臺,基於 Datalink 的導出平臺做了 OLAP 的生產平臺,在這邊除了底層的引擎層之外,我們做了平臺層。在這上面,我們對於資源、模型、任務、權限,都做了相應的管理,使得我們進行 OLAP 的生產非常快捷。

這是我們的 OLAP 生產的兩個截圖。一個是對於 OLAP 中的模型的管理,一個是對於 OLAP 中的任務配置的管理。

五、未來規劃
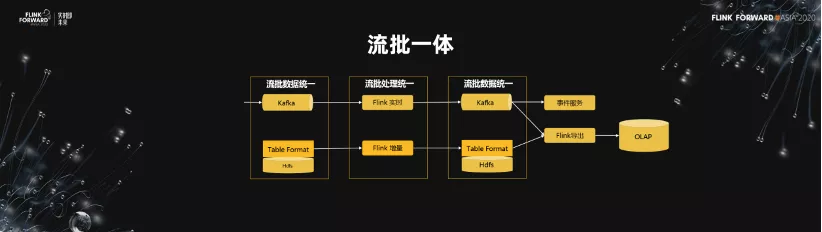
經過相應的迭代,我們把 Flink 用到了數據集成、數據處理、離線數據的導出,以及 OLAP 生產的過程中。我們期望未來對於流批的處理能夠是統一的,希望數據也是流批統一的。我們希望,不管是實時的鏈路,還是增量處理的鏈路,在未來數據統一之後,統一用 Flink 處理,達到真正的流批一體。