一.技術背景
增強現實(AR)技術想必大家都不陌生了,2016年,由任天堂製作的AR手遊Pokeman Go橫空出世,一度造成萬人空巷,大家在全世界各個角落都開始拿著手機“抓怪獸”的盛況。但是唯獨在國內的小夥伴們無法享受到這款遊戲的樂趣,為什麼呢?這要從這款遊戲的技術背景說起,Pokeman Go看起來是一個場景巨大到全世界的AR遊戲,但其實它依賴的技術卻並不複雜,如果簡單來說,就是基於Google Map的定位,地面檢測,局部的相機姿態跟蹤以及渲染能力。
首先,利用Google Map提供的手機位置信息,玩家就可以隨時遇見事先被放置好的“怪獸”,為了增強遊戲的趣味性,遊戲公司會特意在特定的地方(比如公園)放置稀有“怪獸”,吸引玩家集中到某個地方來抓。當玩家用手機發現“怪獸”後,通過手機配置的攝像頭與慣性測量傳感器,算法會大致推斷地面的位置,之後將怪獸的三維模型放到地面上,並計算手機相對於怪獸的姿態,最後像拍照一樣,把怪獸實時地渲染到手機屏幕上,玩家就能看到一個栩栩如生的怪獸出現在前方草地上了。

圖一:五千人在芝加哥街頭用手機抓“怪獸”

圖二:AR手遊:Pokeman Go
其實,以上描述的“抓怪獸的過程”,就是目前應用最廣泛的AR技術基礎鏈路。首先,全局定位能力(Global Localization)。我們需要設定一個場景,並且,我們需要具備在這個場景中自我定位的能力。在Pokeman Go這款遊戲中,可以認為場景就是背靠Google Map的全世界(除中國大陸地區)。在戶外,定位能力就是Google Map結合GPS信號等信息提供手機位置的能力。第二,簡單的場景理解能力(Scene Understanding)。遊戲中,算法利用手機上的傳感器計算出地面的大致三維位置,就可以將任意的虛擬三維模型放置在地面上方恰當的地方。第三,求解手機攝像頭與虛擬三維模型之間的相對姿態(位置和角度)。這是一種利用圖像間的特徵匹配和手機上的慣性測量單元(IMU),進行實時手機姿態解算的能力,此處就不展開討論了,感興趣的讀者可以搜索關鍵字(Visual inertial odometry). 最後,渲染能力(Rendering)將虛擬物體與真實場景疊加,顯示在手機屏幕上。
讀到這裡,讀者應該知道為什麼我們在大陸地區沒法最好地體驗這款遊戲了。因為Google Map在國內無法訪問。這,也就引出了目前AR應用的一個核心問題。在搭建任何AR應用前,我們都需要一張地圖,在室外,目前的地圖服務商Google Map,高德,百度幫我們提供了地圖和定位能力。那如果是在無法獲取GPS的室內,或者GPS信號較弱的市區,商圈,景區呢?一個可以支持AR應用的地圖從何而來呢?對於當前規模越來越大的城市建築,如何在保證一定地圖精度的同時,達到高效地地圖採集呢?在這篇文章裡,我們想和大家分享,阿里雲人工智能實驗室在向大規模AR應用邁進的道路上,對高效構建精確AR地圖的探索。
二. 全局定位技術概述
在講述如何構建AR地圖之前,我們需要弄清楚什麼是AR地圖。在上一節中,我們講到,AR應用的基礎是全局定位功能,也就是說,AR地圖必須要服務於定位能力。所以,我們有必要簡單介紹一下定位算法。定位算法的輸出,根據不同的場景,各有不同。對於簡單的戶外遊戲應用,GPS提供的經緯度和海拔信息可能就足夠了。但是,對於複雜的室內場景應用,如AR導航,我們通常需要得到相機六個自由度的位姿信息 (在三維空間,六個自由度包括三個座標軸上的平移與旋轉角度信息。)
那麼如何得到相機六個自由度的位姿呢?下方圖三是相機成像原理的簡化示意圖,圖四是更加複雜的相機投影數學模型。在這裡,我們先略過數學原理,簡要來說,我們藉助三維重建技術,如果已知(圖三中)真實空間中大樹的頂端和底端的三維位置,以及對應圖像中,樹頂和樹根的圖像座標,我們就可以通過一種被稱之為Perspective-n-Points(PnP)的方法求解得到拍攝這張圖像的相機位姿。當然,實際情況比這裡描述的過程複雜得多,問題在於兩點:一,我們怎麼獲取一張圖片上的圖像座標和三維空間位置的對應關係呢?二,我們怎麼知道大樹頂端和底端的真實三維位置呢?
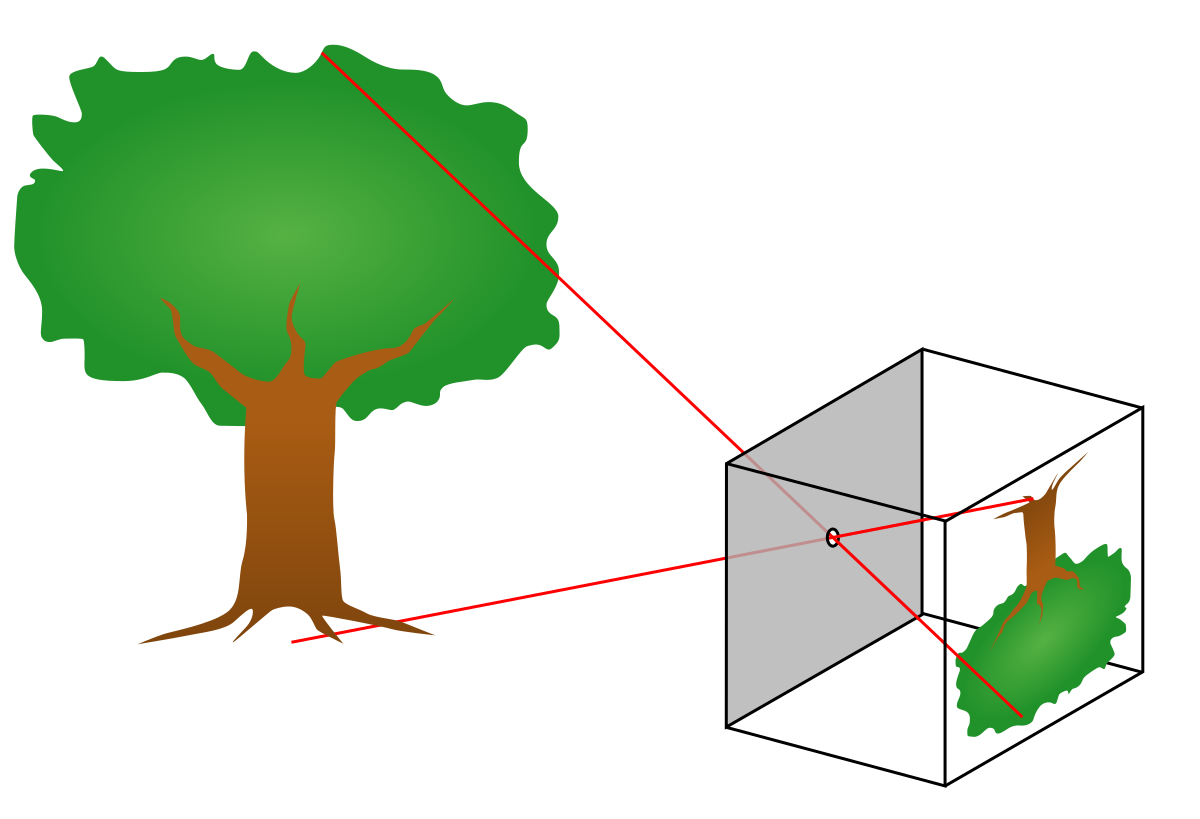
圖三:相機成像原理示意圖
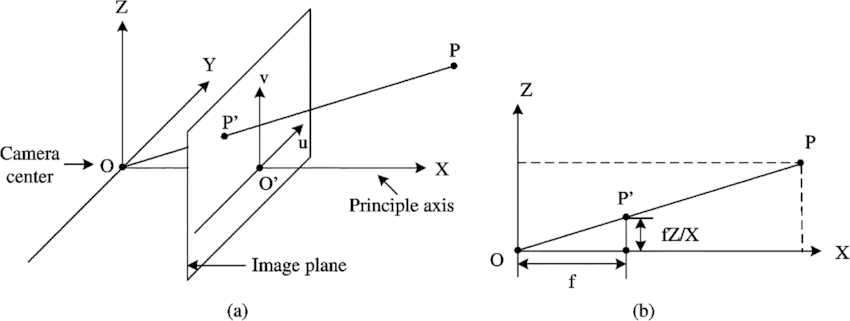
圖四:相機投影數學模型
定位算法試圖解決的,就是第一個問題。而通過構建圖像座標到三維位置對應關係,來求解相機位姿的定位方法,我們可以稱之為“基於結構的”定位方法(structure-based) (另外一種“基於迴歸的”定位方法(regression-based)利用神經網絡“記住”場景,並通過傳入的圖像直接回歸相機位姿。這裡不做展開,感興趣的同學可以參閱[3,4,5])。如果繼續細分,“基於結構的”定位方法又可以分為兩種技術路線:
a. 稀疏特徵匹配(sparse feature matching)。如圖五所示,稀疏圖像特徵,也就是一張圖片中極具特點(distinctive)的像素點。如圖五中所示,目前基於SuperPoint神經網絡[1]提取到的特徵點,以及經過深度學習訓練的特徵匹配器SuperGlue[2],已經可以在光照環境,拍攝視角迥異的兩張圖片中,找到對應特徵點,如果我們已知,右圖中特徵點對應的三維位置,我們就可以以之為中介,得到左圖的特徵點對應的三維位置,從而求解左圖的相機位姿。
b. 稠密場景座標迴歸(dense scene coordinate regression)。如圖六所示,這種方法利用一個場景中,事先採集的圖片與三維信息對神經網絡進行訓練,使得神經網絡對輸入的彩色圖像可以直接估算稠密的三維座標。注意,是對每一個像素點,都利用網絡迴歸出它的三維信息,從而通過稠密的圖像座標與三維座標對應關係,求解相機的位姿。

圖五:基於CNN網絡的Sparse feature matching
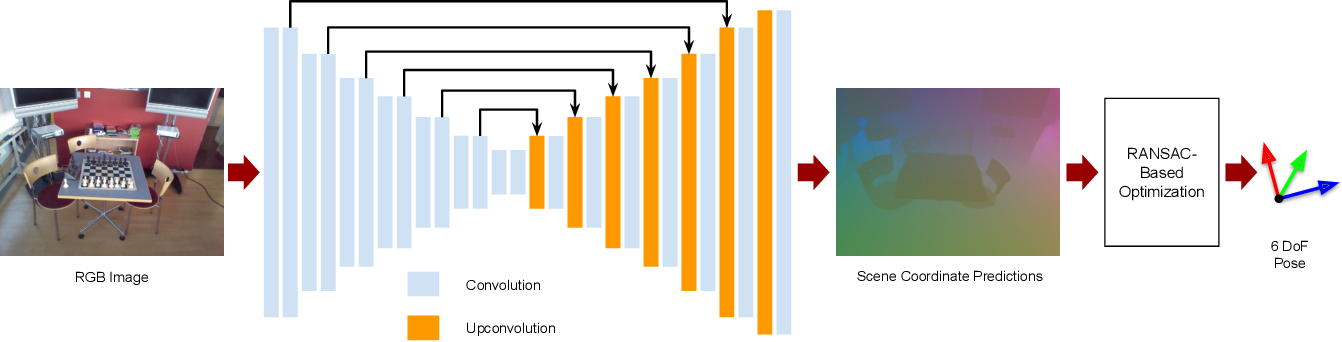
圖六:稠密場景座標迴歸方案
三. 什麼是AR地圖
上一節中,我們花了一些篇幅介紹了前沿的視覺定位算法,我們發現要滿足定位需求,所需要的輸入信息包括:特定場景中採集的彩色圖片,以及它們對應的三維信息以及相機位姿。我將這些信息的集合稱為AR地圖。當然,AR地圖是滿足定位需求的最小集合,我們也可以以此為基礎,加入其他可以用來輔助定位的信息,比如場景中的語義信息等。我們定義了AR地圖的主要元素,並不代表我們就能製作滿足條件的AR地圖,還需要回答下面三個問題:
1.如何高效地採集並且更新AR地圖,來應對變換頻繁的室內場景?
2.如何設計一套建圖算法,來保證AR地圖的精度?
3.如何有效地評估AR地圖,是否達到了AR應用對於地圖的要求?
接下來,我們就圍繞這三個問題,來介紹我們的AR地圖構建方法。
四. AR地圖數據採集
在AR地圖中,最為重要的是和彩色圖片對應的三維信息。那麼,我們目前是通過什麼手段獲取三維信息的呢。如圖七中所示,我們是通過不同的傳感器,獲取到不同類型的三維數據,再經過算法的加工,最後將三維世界數字化的。這些傳感器各有特點,也各有利弊。比如,多線激光雷達通過旋轉的激光發射器,直接獲取周圍環境的深度信息,但是由於造價和工藝結構的約束,單個雷達能掃描到的範圍非常有限,深度值測量也很離散。彩色相機雖然可以捕捉到場景中大範圍的色彩信息,但是需要複雜的算法流程才能恢復出三維信息。而且相機常常受到光照變化和運動模糊的影響。慣導設備IMU可以測量自身感受到的加速度和角速度等信息,但是由於IMU一般存在較大的累積漂移誤差,也不能直接用來測量自身的三維位姿。所以將不同傳感器進行組合,才能以最優的方式獲取到場景的精確三維信息。
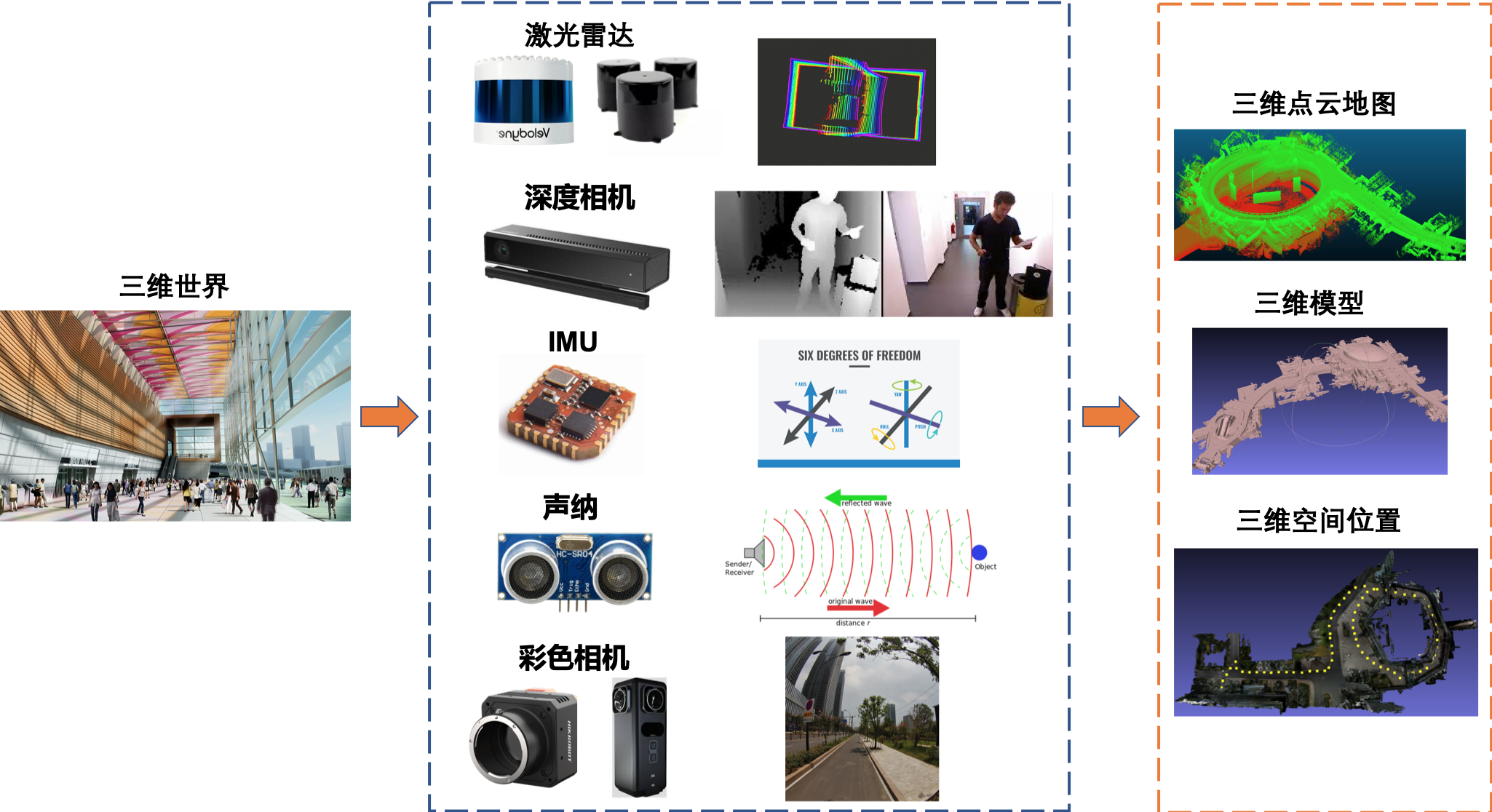
圖七:我們通過不同傳感器獲取真實三維世界的數據,然後利用算法構建AR地圖中的三維數據
所以,我們自研了一款以揹包為形態(如圖八所示),搭載多種傳感器的移動掃描設備。這款設備裝配有全景相機,激光雷達,慣性測量單元(IMU)。所有傳感器通過我們自研的時間同步板進行同步。在對特定的場景進行掃描的時候,使用者揹負著揹包掃描設備,並且手持搭載有采集程序的平板電腦進行數據採集。採集過程中,激光雷達不停旋轉掃描,獲取原始掃描點雲數據,當需要採集全景圖時,使用者會停止走動,通過採集程序中的採集按鈕,進行全景圖圖像採集。因為拍攝全景圖片所需時間很短,我們可以在場景中的任意位置密集採樣全景圖。當對某個場景的數據採集完成後,我們得到的是揹包設備輸出的原始數據,這些數據包括全景相機的圖片,激光雷達的單幀點雲,以及IMU的原始測量數據。
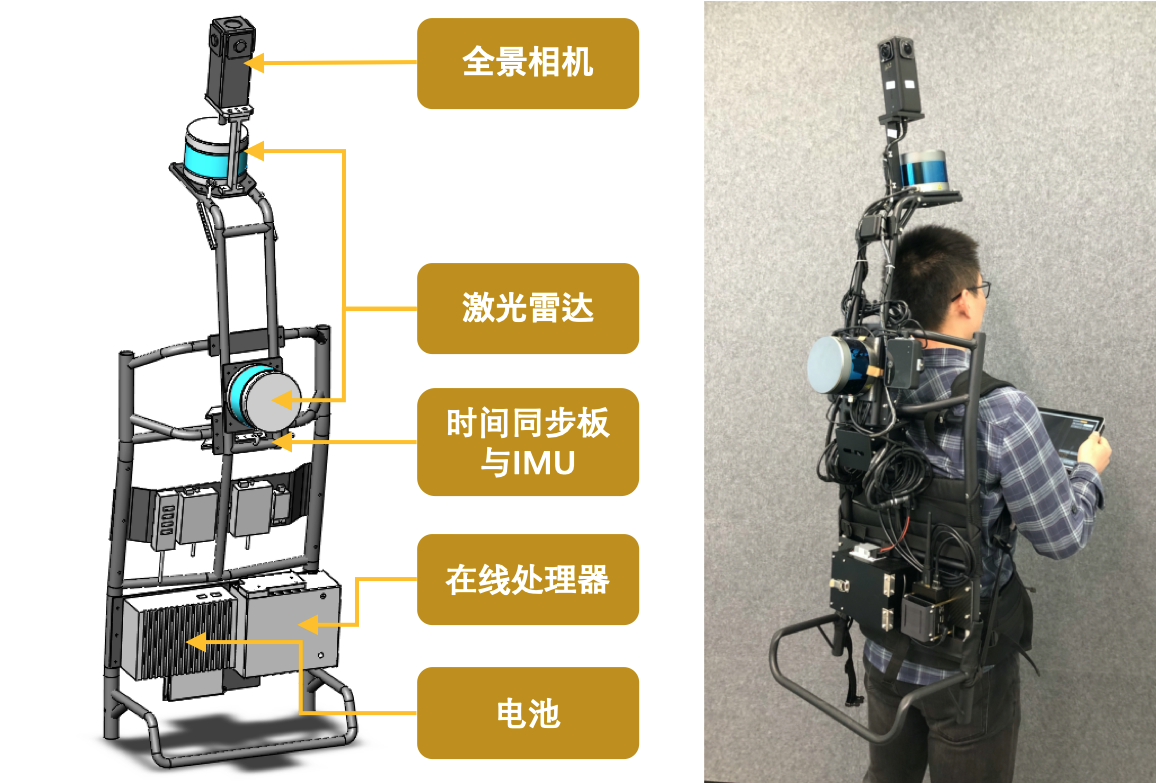
圖八:揹包結構示意圖
藉助自研揹包掃描設備以及掃描距離達到150米的激光雷達,我們就能按照正常的行走速度在大場景裡面進行高效數據採集了。然而,我們獲取的原始數據還需要建圖算法的加工,才能生成包括三維模型和相機位姿在內的三維數據。我們首先通過一套自研的多傳感器標定算法,將揹包上各個傳感器的相對位姿求解出來。這套標定算法克服了傳統方法需要反覆採集多個點位數據,以及傳感器間必須保證視角重疊區域的約束。只需要一個點位的採集數據,就可以得到多相機與多雷達間的相對關係。感興趣的讀者請關注我們團隊關於多傳感器標定的文章。
五. AR地圖生產流程
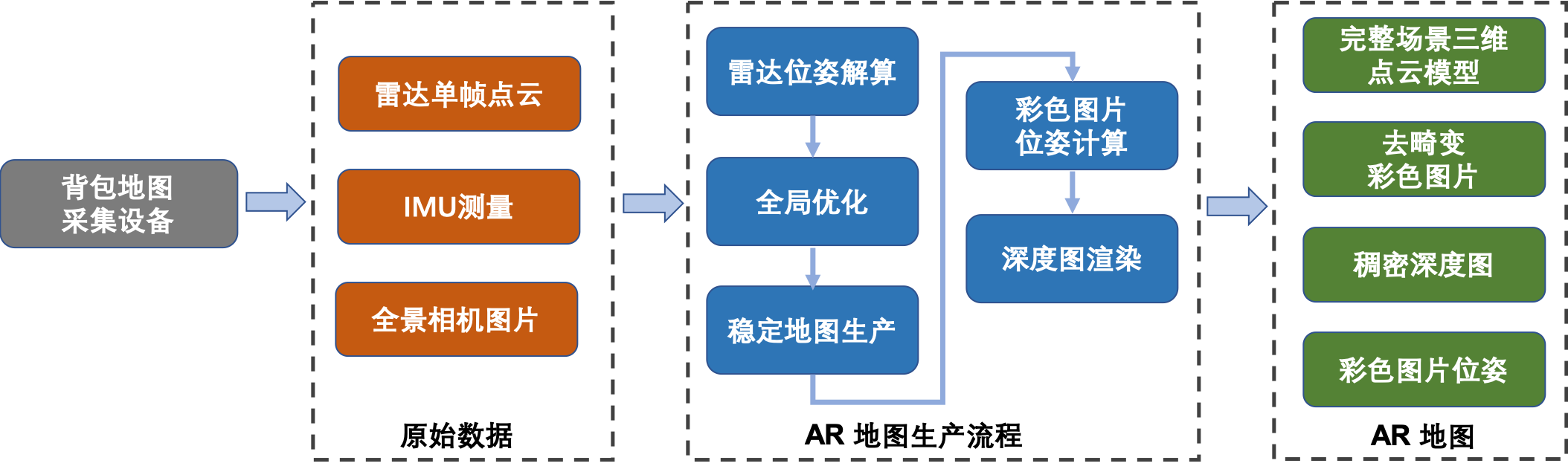
圖九:AR地圖的生產流程圖
如圖九所示,AR地圖的生產流程主要包括五個子模塊:雷達位姿解算,全局優化,穩定地圖生產,彩色圖片位姿計算和深度圖渲染。以下對這五個子模塊進行描述:
1.雷達位姿解算:根據輸入的連續的單幀雷達點雲數據,求解相鄰兩幀點雲數據之間的位姿轉換關係,該轉換關係包括相鄰兩幀雷達數據的平移與旋轉關係。通過不斷積累兩幀之間的轉換關係,得到每一幀雷達在全局座標系下的位置與旋轉信息。
揹包掃描設備上裝配的兩個16線激光雷達,掃描平面呈25度。每個雷達連續旋轉掃描,在0.1秒內旋轉360度,併產生75個數據包(data packet),我們稱0.1秒的雷達數據為單幀掃描點雲。雷達位姿解算就是通過求解連續兩幀的雷達點雲相對關係,來推算雷達的位姿。這裡我們通常用到的算法稱之為ICP-Iterative closest point. 通過查找兩幀點雲中的最近點,迭代地優化雷達在兩幀間的相對位姿(如下圖十)。但是由於每幀點雲的數量很大,ICP中的最近鄰查詢算法會非常耗時。所以2014年的RSS上,Zhang JI提出了經典的LOAM算法 [6],通過計算局部點雲的分佈情況(圖十一),提取單幀點雲中的平面點與角點 (planar feature and corner feature), 這樣減少了相鄰兩幀點雲的匹配關係數量,提高了位姿解算的效率。
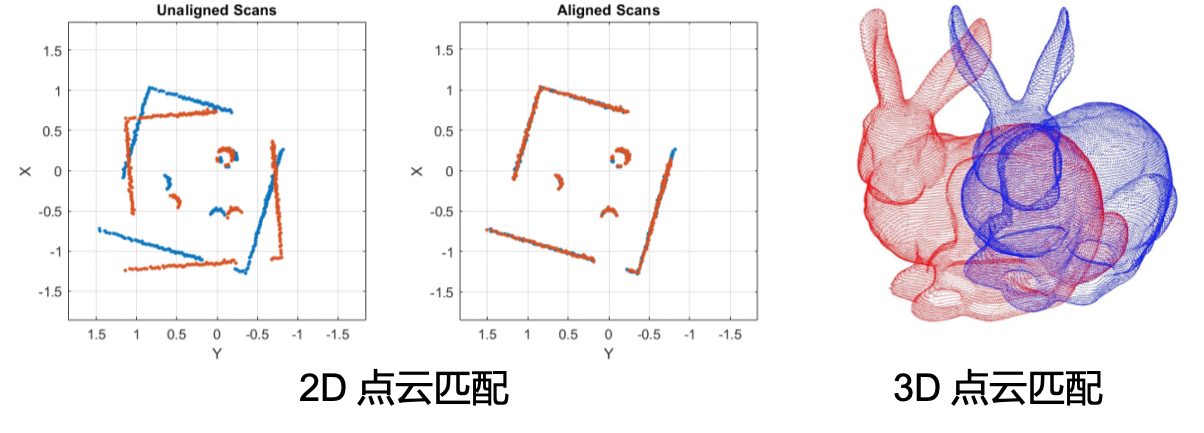
圖十:二維和三維點雲的ICP匹配示意圖
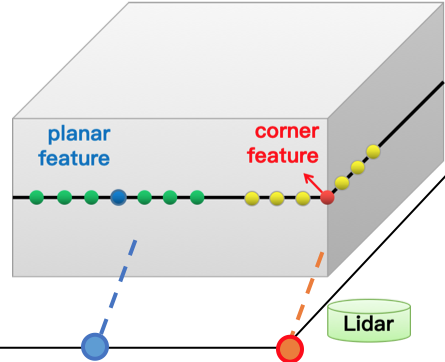
圖十一:LOAM中的點雲特徵點提取
我們利用在每一幀點雲中提取得到的平面點(藍色)與角點(紅色),與上一幀點雲中“平面”和“邊緣”建立對應關係,通過最小化“點到平面”與“點到線”的距離,優化得到兩幀間的相對位姿。邊緣點特徵是通過計算相鄰點的相對距離來決定的,與相鄰點重心距離較大的點,會被提取為邊緣特徵 (如圖十中所示)。但是由於室內場景複雜,常常因為遮擋,噪聲,以及深度不連續的問題,會引入不少“偽”特徵點(如圖十二所示)。這些“偽”特徵點會形成錯誤的特徵匹配關係,影響位姿估計。為了消除“偽”特徵帶來的影響,我們設計的“偽”特徵過濾機制(公式一),可以過濾掉大部分的“偽特徵”。
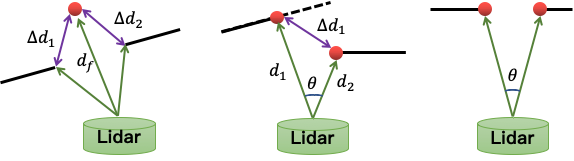
圖十二:“偽”特徵點生成的三種方式:離群點,深度不連續,以及遮擋導致的不連續。
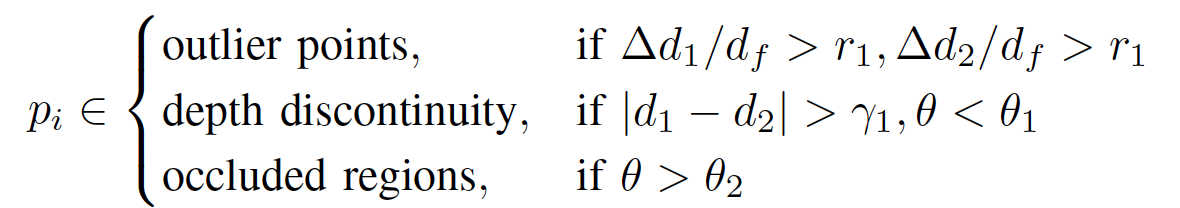
公式一:“偽”特徵過濾機制
如圖十三所示,在戶外場景中,草地往往會引入大量的“偽”邊緣點,影響位姿的估算,針對性的實驗證明,我們的過濾機制可以去除這些噪聲。

圖十三:偽邊緣點的去除
2.全局優化:由於相鄰兩幀雷達的相對位姿解算存在誤差,經過長時間積累得到的全局位姿會存在較大的累積誤差,全局優化模塊通過迴環檢測對所有雷達位姿進行優化,減小累積誤差。我們在傳統的位姿圖優化的基礎上,加入了保持相鄰子點雲地圖間,點雲一致性的約束,使得全局優化後的點雲地圖仍然能保持較好的局部一致性(圖十四)。
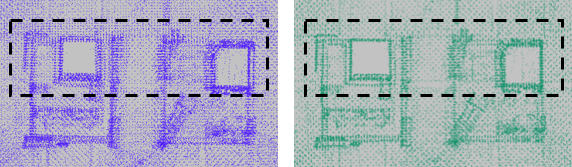
圖十四:不加入與加入點雲一致性的全局優化結果對比,注意左側的點雲存在較大分層現象,右側的點雲結構更加清晰。
3.穩定地圖生產:在得到所有單幀雷達點雲的位姿後,我們可以將點雲拼接得到場景完整的三維點雲模型。由於場景中的動態物體會引入雜點,我們通過過濾雜點,得到穩定完整的三維點雲(圖十五)。我們稱之為穩定地圖點生成模塊。

圖十五:在繁忙室內環境的點雲地圖結果,人來人往,帶入了很多雜點,右側是經過雜點過濾的點雲地圖,消除了動態點引入的噪聲。
4.彩色圖片位姿計算:我們最終需要得到彩色圖片對應的的相機位姿,通過事先標定得到的雷達與全景相機的轉換關係,我們將雷達的位姿轉換得到對應時刻的相機位姿。
5.深度圖渲染:如圖十六所示,在得到完整的三維點雲與彩色圖片相機位姿之後,我們可以通過投影渲染的方式得到對應的深度圖。深度圖可以用來快速索引彩色圖片上某一點的三維座標。
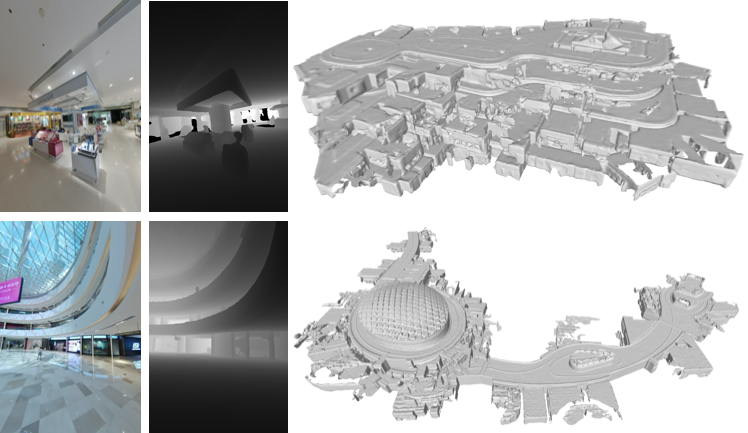
圖十六:兩個大型商場AR地圖中的彩色圖片,深度圖,以及基於三維點雲生成的三維模型。
六. AR地圖的評估
我們生產的AR地圖中主要包含的是場景三維模型與彩色圖片的位姿信息。所以,我們從兩個方面對AR地圖的精度進行評估:1. 點雲地圖的精度;2. 彩色圖片位姿與深度圖的精度。
首先,為了評估點雲地圖的精度,我們利用工業級的掃描設備Leica BLK360對場景進行掃描,再將其生成的點雲地圖作為參考真值,評估揹包掃描地圖的精度(圖十七)。

圖十七:在辦公室與戶外園區場景下,Leica BLK360與揹包設備生成點雲地圖的對比。
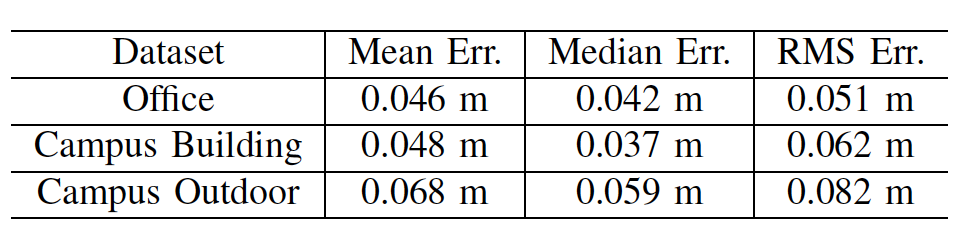
表格一:在三個不同場景Office,Campus Building, Campus Outdoor的點雲地圖精度評測結果。
其次,為了統計局部圖像位姿與深度的一致性,我們計算了圖像間特徵匹配(圖十八)的重投影誤差e1與對極約束誤差e2。

圖十八:圖像間的特徵點匹配
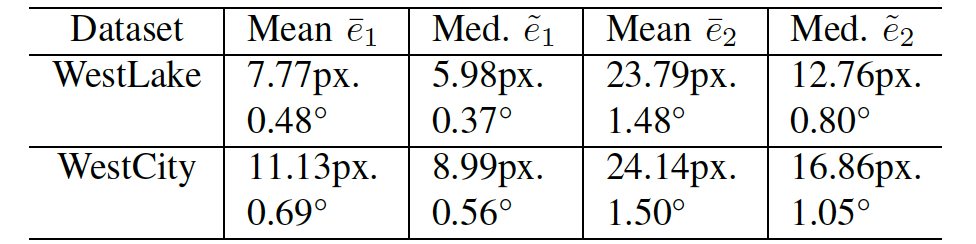
表格二:在西湖與西城兩個場景中,圖像間的特徵重投影誤差均值和中位數。
最後,我們用iPhone11在場景中隨機採集圖像,並利用AR地圖進行定位(圖十九),在全部110張手機圖像中,97張(88.2%)可以被成功定位, 也證明了AR地圖在定位模塊中的可用性。

圖十九:在大型商場場景中的定位結果。第一行為AR地圖中的示例圖片以及場景中的位姿。第二行為iphone11採集得到的查詢圖片,以及在AR地圖中的定位結果。
七. 更多應用案例:VR內容生產
我們生產的AR地圖同樣可以用於VR的內容生成。我們採集了辦公室,商場,園區,地下管廊等場景的AR地圖,並通過我們團隊的“萬花筒”VR漫遊生產系統,生成VR漫遊效果。


圖二十:EFC商場(上圖)以及辦公室(下圖)的VR漫遊效果。
八. 總結
無論是增強現實(AR)或是虛擬現實(VR),都將在未來成為人們與真實世界交互的新方式。在這篇文章中,我們介紹了阿里雲人工智能實驗室在構建大場景室內AR/VR地圖數據上的探索。我們提供了一套從高效硬件採集設備,AR地圖構建算法,到評估體系的全鏈路解決方案。這套解決方案能在包括大型商場,園區等場景高效構建精確的AR地圖數據,也為我們之後能支持大場景下的AR應用,打下了堅實的基礎。
參考文獻
[1] DeTone, Daniel, Tomasz Malisiewicz, and Andrew Rabinovich. "Superpoint: Self-supervised interest point detection and description."Proceedings of the IEEE conference on computer vision and pattern recognition workshops. 2018.
[2] Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. Superglue: Learning feature matching with graph neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4938–4947, 2020. 1, 2, 5, 6
[3] Alex Kendall and Roberto Cipolla. Modelling uncertainty in deep learning for camera relocalization. In 2016 IEEE international conference on Robotics and Automation (ICRA), pages 4762–4769. IEEE, 2016. 1, 2
[4] Alex Kendall and Roberto Cipolla. Geometric loss functions for camera pose regression with deep learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5974–5983, 2017. 1, 2
[5] Alex Kendall, Matthew Grimes, and Roberto Cipolla. Posenet: A convolutional network for real-time 6-dof camera relocalization. In Proceedings of the IEEE international conference on computer vision, pages 2938–2946, 2015. 1, 2, 5
[6] Zhang, Ji, and Sanjiv Singh. "LOAM: Lidar Odometry and Mapping in Real-time."Robotics: Science and Systems. Vol. 2. No. 9. 2014.