背景
被实验案例的数据和完整实验流程已经内置于PAI-Studio建模平台https://data.aliyun.com/product/learn
进入PAI-Studio,首页模板最下方位置点击从模板创建“推荐场景-FM向量召回”开箱即用
智能推荐分为排序和召回两大模块,在召回模块中通常会采用将 用户User和待推荐的 内容Item 分别以向量表示,然后通过User和Item的向量乘积大小作为User对Item的感兴趣程度的判断。本案例介绍如何基于真实的推荐场景数据,通过使用PAI平台提供的FM算法和Embedding提取算法产生User和Item的描述向量。
详细流程
完整业务流程图:
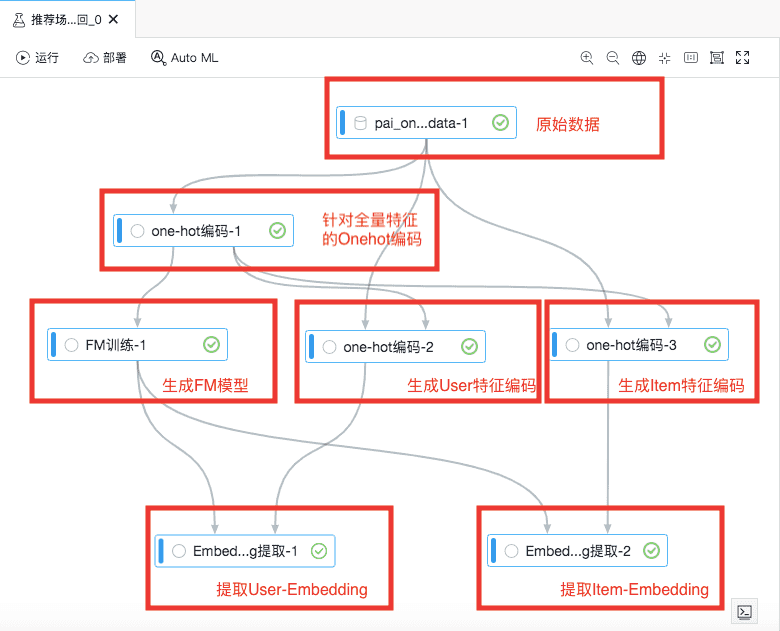
1.数据说明
原始数据如图:
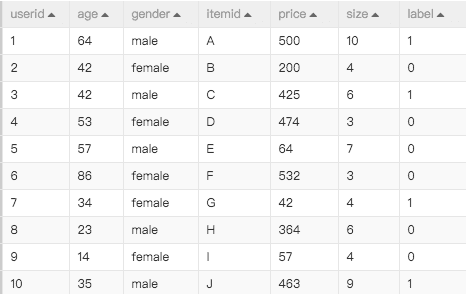
数据字段描述:
- userid:user的id信息
- age:user的年龄
- gender:user的年龄
- itemid:item的id信息
- price:item的价格
- size:item的大小
- label:目标列,是否购买,1为买,0为未买
2.One-hot编码
One-hot编码可以将字符型数据转成数值型表示,在FM-Embedding方案中首先利用“onehot编码-1”针对全量数据进行编码,生成编码模型再输入到“onehot编码-2”和“onehot编码-3”中,“onehot编码-2”需要选择User对应的特征信息进行编码,“onehot编码-3”选择Item对应的特征信息进行编码。
“onehot编码-2”的输入是userid、gender、age,附加列选择userid。
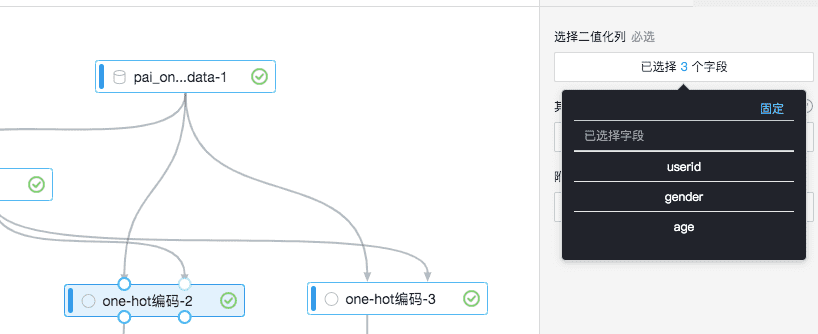
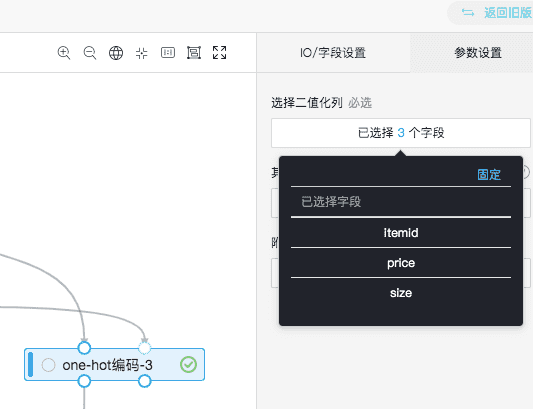
“onehot编码-3”的输入是itemid、price、size,附加列是itemid。
3.FM训练
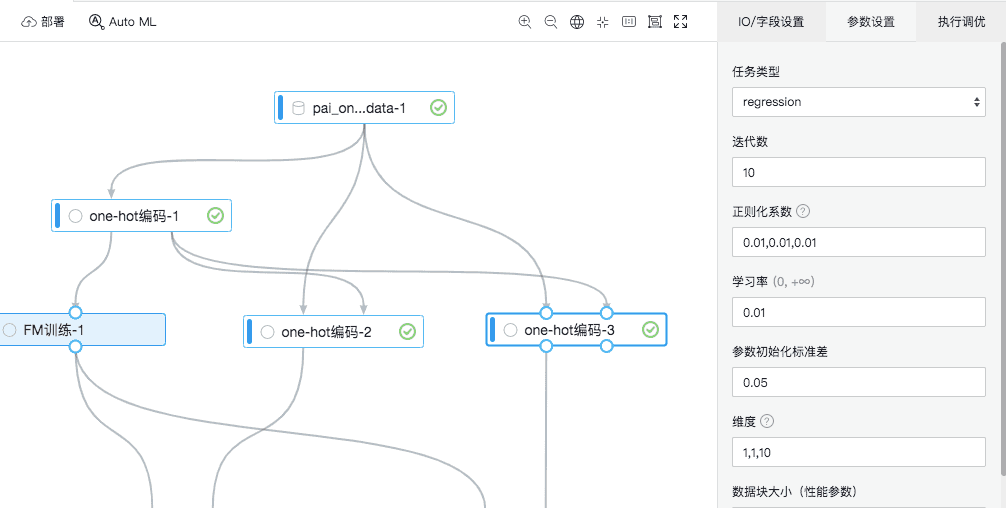
正则化和维度这两个参数有3个参数,分别对应常数项、一次项和二次项。其中维度的第3个参数“10”代表生成的Embedding的维度。
4.Embedding提取
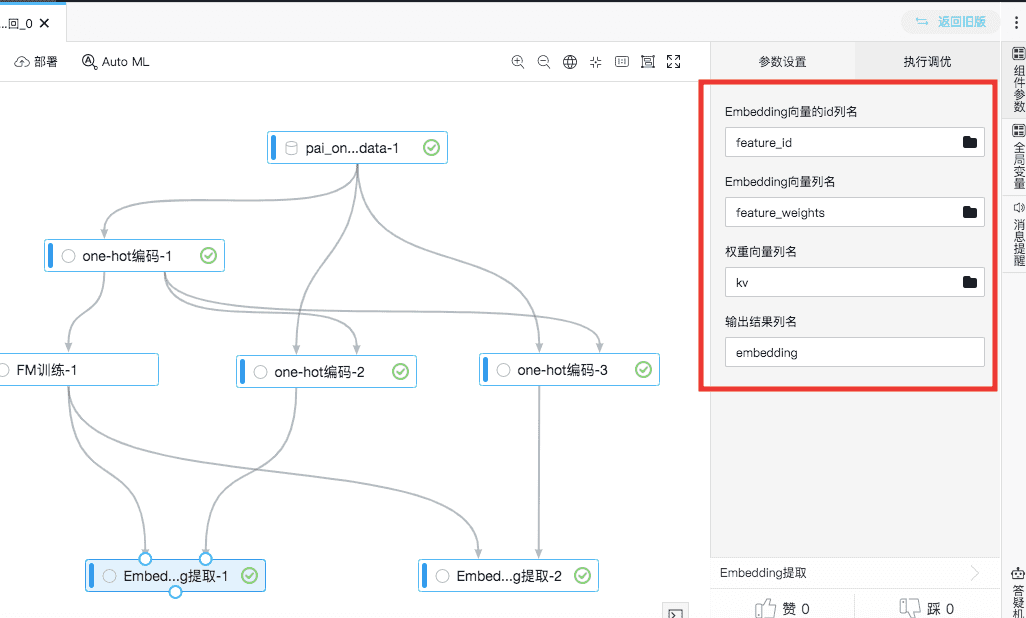
- Embedding向量id列名:输入左桩FM训练中的模型“feature_id”
- Embedding向量列名:输入左桩FM训练中的模型的“feature_weights”
- 权重向量列名:输入右桩对应的稀疏化数据列
- 输出结果列名:输出的Embedding字段名
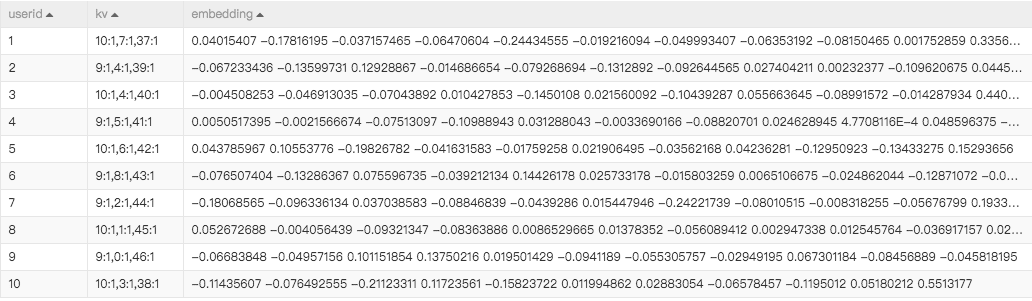
最终输出结果:
总结
使用PAI提供的整套FM-Embedding方案可以在推荐业务场景中快速挖掘出User和Item对应的特征向量,在实际召回模块只要做User和Item的特征向量积就可以得到打分结果。