前言
NeurlPS 2019 大会刚结束,看了看相关的内容,绝大部分是各种前沿理论的文章。这些和我工作的内容还有比较长的距离:不论是知识领域空间上的距离,还是相关理论转为工业界实践的时间上的距离。但有两篇还是吸引了我的注意。一篇是用于普及的教程:“Efficient Processing of Deep Neural Networks: from Algorithms to Hardware Architectures". 另一篇是PyTorch的简短设计理念的介绍:“PyTorch: An Imperative Style, High-Performance Deep Learning Library“。今天,谈一下对前一篇的细读和体会。
教程是一系列的主题的集合,主题是从算法模型到硬件架构,以及两者如何共同设计(co-design),高效地处理深度神经网络。涉及的面还是比较广的。演讲人是Vivienne Sze,MIT副教授,来自MIT的高效能多媒体组。里面的内容是团队的合作研究的一个总结。
教程的主要内容大家可以仔细看视频,也有对应的Slides。Slides里面有很多的链接,可以找到对应的论文,代码等,非常有用。他们团队的主页在这里https://www.rle.mit.edu/eems/publications/tutorials/。里面有对应的材料。
总结
首先,上干货图,我总结的学习思维导图。
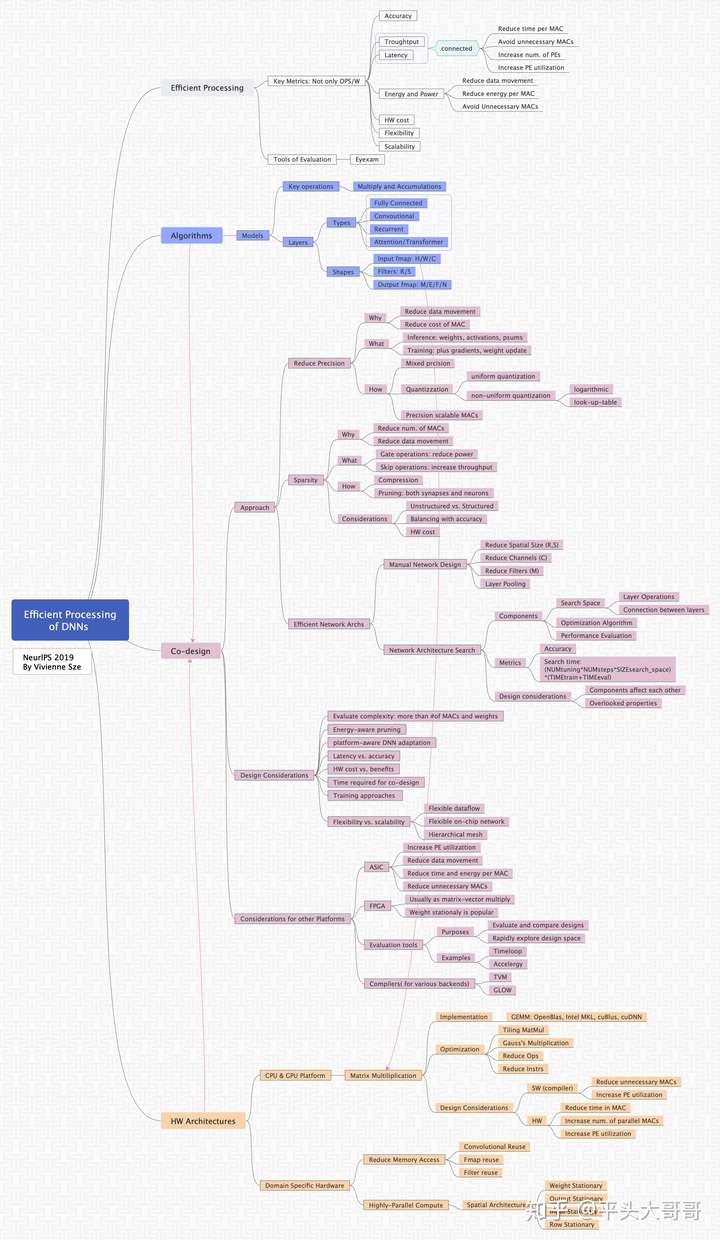
思维导图-Efficient Processing of DNNs: From Algorithm to HW
总体来说,里面谈到的内容挺广的了。因为是作为教程,里面的内容偏初级,偏理论一些,非常适合用于学习和总结。我选择一些自己认为比较感兴趣,或者值得讨论的地方来和大家一起讨论一下,并做适当地展开。
1. DNN运算
教程里的大部分篇幅强调的是MAC(Multiply and Accumulate)。为此,还特别地提到了矩阵乘在recurrent和attention层也使用得非常的多。可能一方面因为这是初级教程,另一方面也是因为有些材料是两年前就有的,稍显有些过时,属于所谓AI1.0的重点,所以会过于强调MAC。
当前AI2.0阶段,应用更丰富,作为对比,我们可以看看工业界的数据。来自Facebook的数据:
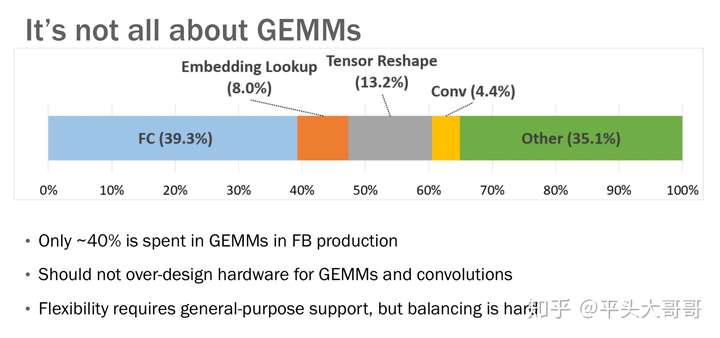
我们实际上也是同样遇到这样一个问题:随着深度神经网络在各方面的应用越来越多,DNN里面的操作也变得多样化起来。工业界对这些问题更需要进一步的研究:包括各类应用场景中,DNN的各类操作的比例,包括当前的以及未来一段时间的。
然后,对这个问题的解决有多种方式,并且这些方案可能结合起来:
- 采用多种可并行的硬件计算单元:MatMul, vector op, reshape/transpose, etc. 做好比例的调研工作。
- 灵活可变的(flexible)微架构(HW pipe),也就是同一个硬件模块可以用作不同的操作。可以由软件,比如编译器调整比例,驱动控制使用类型。
- 软件栈做优化,包括算法,框架,编译器等,将一种类型的操作转化成另一种类型的操作,以适应硬件的能力。
2. 主要的效能评估标准
教程关于效能的评估标准谈得比较的全面,覆盖了计算准确性,吞吐,延迟,能耗,硬件费用,以及应用的灵活性。详细地介绍了一些对应的主要的设计目标,如何达到更高效的DNN处理器。
同时,教程也谈到了一些评估的规范标准,特别强调了各个度量标准有自己独立的意义,所有的评估度量都需要综合考虑,遗漏其中的一些度量会导致评估的不公平。
这通常需要一系列比较复杂的基准测试,比如相对比较成熟和全面的MLperf,它通过多种不同的方式来尽量地让评估全面和公平。比如推理基准测试,
- 包含4种模式:single stream, multiple stream, server, offline
- 包含多种不同类型的模型,覆盖image classification,object detection,语言模型,翻译,语音识别,情感分析。
- 定义了比较详细的一些规则。(https://github.com/mlperf/policies/blob/master/submission_rules.adoc)
- 可以提供不同的scale: x1, x2, x4, x8,...,x32等多种成绩
除了使用主流的Benchmark外,在工业界,针对激烈的市场竞争,产品设计者需要考虑的是在多维评估度量之间如何定位自己的产品。通常会根据设计者对相应的产品定位,对上面提到的评估度量排出一定的优先级。比如,性能优先,还是通用性优先等。通常,还会使用一些组合的度量,比如PPA(Power-Performance-Area: power area per w)。会正对这些不同的度量具体化,给出一个可以度量的数字以明确设计目标。
3. 高效的数据流
这非常非常重要的一个话题。教程首先强调DNN计算,存储访问是瓶颈,数据流动是非常昂贵的。教程提供了四层存储架构(RF-寄存器,PE-本地存储,Buffer-全局存储,DRAM)的访问能量消耗比。从矩阵乘法MAC计算的角度,总结了各种类型的数据重用方法。这些数据重用的方法很基础,在各种不同的架构中,可能都有一些使用,虽然具体的方法有些差别。
教程在最后“Other Platforms"章节里提到了ASIC使用定制的存储层次架构和数据流来减少数据的移动。但比较遗憾的针对这个话题,教程没有继续展开深入的讨论。
导读:
近存计算(NMC: Near-memory Computing):
https://arxiv.org/pdf/1908.02640.pdf
http://www.emc2-ai.org/assets/docs/neurips-19/emc2-neurips19-verma-talk.pdf
存内计算(IMC: In-memory Computing) NeurlPS正好也有一篇IMC的文章:
https://www.emc2-workshop.com/assets/docs/neurips-19/emc2-neurips19-verma-talk.pdf
4. 算法硬件协同设计(Co-Design)
这是整个教程的后半部分。Sze教授从几个主要的协同设计点来讲述DSH(Domain Specific Hardware)的协同设计思想和实践:
首先是如何选择合适的精度,包括混合精度以及可变精度的一些实现。降低计算精度的目的是减少操作数的存储和计算量,教程里给出了各种精度乘/加/读的能量消耗。也提到了量化的问题。
其次如何利用和降低稀疏性。不过压缩的问题最近也不是热点了。这要是硬件代价和收益的对比比较大。
然后用了较大的篇幅讲高效DNN的网络架构。包括手动设计和自动的网路架构搜索。后面这个话题挺有意思的,虽然和我的工作没有直接关系,但这种自动搜索的理念是很方便应用在其他场景的。
协同设计时,很多方面需要考虑的是如何做平衡(Tradeoff):性能和延迟,延迟和准确性,硬件成本和精度,等等。做难的一个方面,是既要保证主流DNN计算高效能,又要保证整个设计的灵活性和扩展性,以能满足日益增长的多种类型的计算需求。
感兴趣的同学可以去学习一下相关的两个架构里的设计思想:
导引1: Graphcore IPU,已经在微软 AZURE 上开测。
IPU创新的使用BSP(Bulk Synchronous Parallel)架构,在数据流处理上完全不同于传统的系统。感兴趣的同学可以去仔细阅读。我也还在学习当中。
导引2:AWS Inferentia推理芯片,存储层次和互联都是亮点,可惜我还没有找到更进一步材料。
https://www.eetimes.com/aws-rolls-out-ai-inference-chip/
AWS: Each chip has 4 “Neuron Cores” alongside “a large amount” of on-chip memory. There is an SDK for the chip which can split large models across multiple chips using a high-speed interconnect.
讨论
整体来说这一教程作为初级入门学习非常好。建议感兴趣的同学可以慢慢品读一下。如果我来介绍的话,我还会多研究学习工业界Facebook,Graphcore,Habana,AWS等,加上其他的一些其他的话题,比如
软硬件的协同设计
首先是软件和硬件的协同设计。在上层应用和研究者眼里,通常会认为算法和硬件就是DNN计算的两大块。其实从真正的从业人员的角度来看,我们跟偏向于算法-软件-硬件的协同设计。比如上面引用的Facebook的在AI Hardware Submit 2019的一篇演讲: 《AI System Co-Design: How to Balance Performance & Flexibility》。演讲人是Facebook的AI Systems Co-Design Director。演讲里比较明确地谈论了一些软件和硬件协同的思想和方法。
DSH的架构,必然加大上层应用和底层硬件之间的逻辑距离。从框架,到DSL,通过编译器到特有的ISA。中间的转化和对接工作,是特定领域的软硬件协同核心价值所在。只有这个从算法到软件栈到硬件的通路设计得合理和高效,才能充分体现DSA的意义。
• Dave Kuck, software architect for Illiac IV (circa 1975)
“What I was really frustrated about was the fact, with Iliac IV, programming the machine was very difficult and the architecture probably was not very well suited to some of the applications we were trying to run. The key idea was that I did not think we had a very good match in Iliac IV between applications and architecture.”
• Achieving cost-performance in this era of DSAs will require matching the applications, languages, architecture, and reducing design cost.
很多的公司都在进行软硬件协同设计的实践,特别是AI方面的ASIC,FPGA。这些实践离理想的软硬件协同设计概念还比较远,但不可否认,这些实践在芯片和软件栈上的落地,推动了这一理念的发展。通过对相关行业和公司的研究,可以比较明显地看到,在硬件/芯片设计前期,如果脱离软件(框架,编译,驱动)的协同,即使硬件/芯片成功出来了,也会有很大的业务落地问题,包括但不限于:
- 算法对接硬件难,编译,驱动实现工作量大,
- 应用编程难,编程模型和编程接口不好用
- 硬件性能很难发挥,算力的利用率低下
这大概就是大家在实践中体会到的“硬件好做,软件困难”的问题。而实践好的设计,在前期如果协同考虑和系统性地解决了一些主要问题,就能比较好的加速后期业务落地。
导引:
https://semiengineering.com/hardware-software-co-design-reappears/
总结
在原来的思维导图的基础上,我搜集并添加了相关的一些资料,产生一个新的知识图谱: