一、場景特性
每個業務場景都有自己特有數據特性,IoT也不例外。單純從設備檢索的角度切入來看,IoT的設備檢索特性如下:
1. 億級數據;
2. 數據高頻變更;
3. 時序特性;
4. 無冷熱特徵;
5. 結構鬆散;
6. 數據異構;
二、數據Dump層
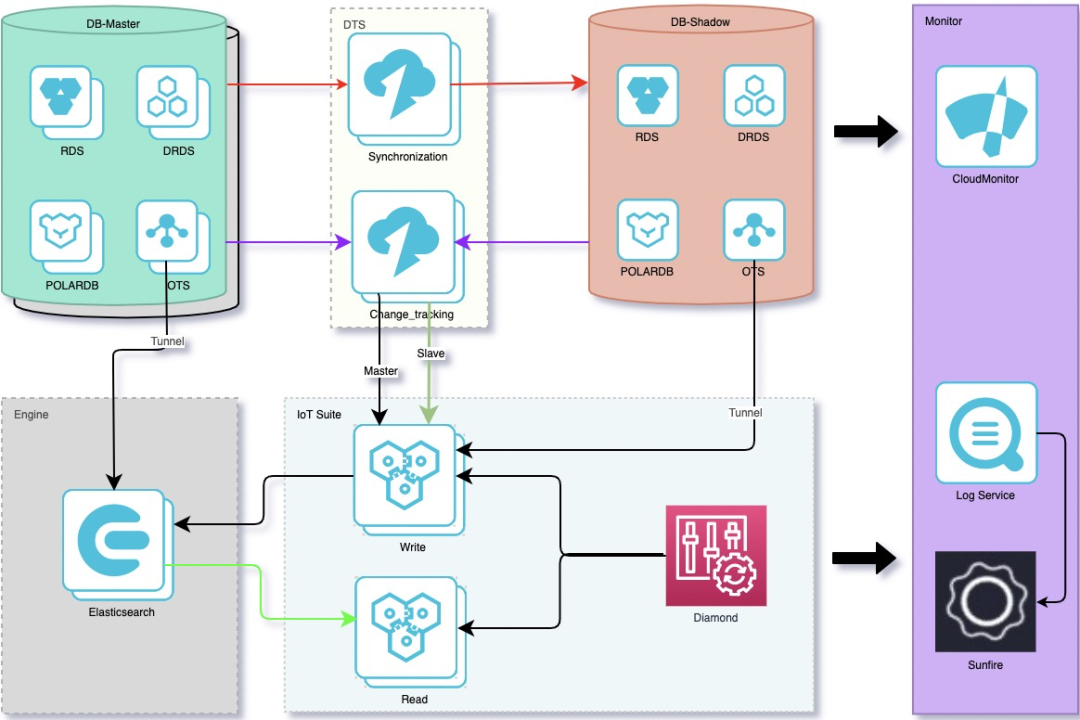
整體思路和多數檢索場景類似:全量數據+增量數據。由於底層用了多套雲檢索引擎,因此整個Dump層天然具備雲原生的能力,與此同時,我們採用了影子庫、主備集群、讀寫分離、配置化、全鏈路監控等手段,來保障數據的吞吐、時延、穩定、高效。
三、物模型檢索
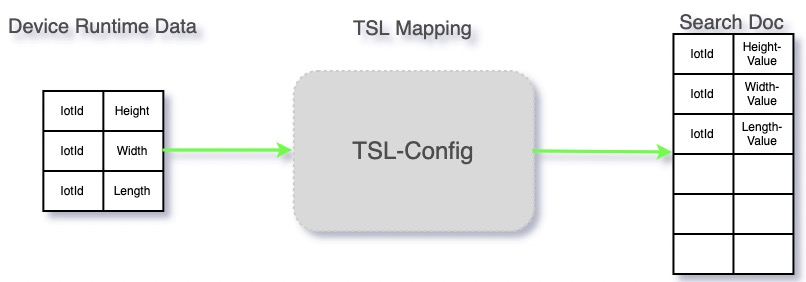
物模型是物理空間中的實體(如傳感器、車載裝置、樓宇、工廠等)在雲端的數字化表示,從屬性、服務和事件三個維度,分別描述了該實體是什麼、能做什麼、可以對外提供哪些信息。因此相對於設備的元數據(名稱等),物模型數據的檢索是極其重要的一部分。然而,雖然單個設備的物模型屬性數量是有限的,但是不同的設備的物模型屬性數是完全不一樣的,這就導致最終最終設備的物模型的屬性是不可窮盡的,但是我們的索引表的寬度是有限的。因此,就需要用有限的索引列存儲無限的物模型數據。
通過結合物模型的特點:數據定義明確、整體數量不可窮盡、單設備可窮盡,將單設備的物模型信息與索引進行映射,多設備複用相同索引,實現物模型數據的檢索。
四、SQL-Like檢索能力
雲上的產品ToB的比重更高,使用我們雲平臺的大多數用戶都有一定技術背景,SQL在技術人員普及度又極高,為了降低用戶的使用成本,我們提供了SQL-Like的檢索能力,用戶能夠像查詢數據庫一樣來檢索數據。與此同時,我們底層用了多套檢索引擎,因此我們希望在上層使用SQL檢索的方式來屏蔽底層引擎的差異。簡而言之,上層使用SQL語法,下層適配多套檢索引擎。
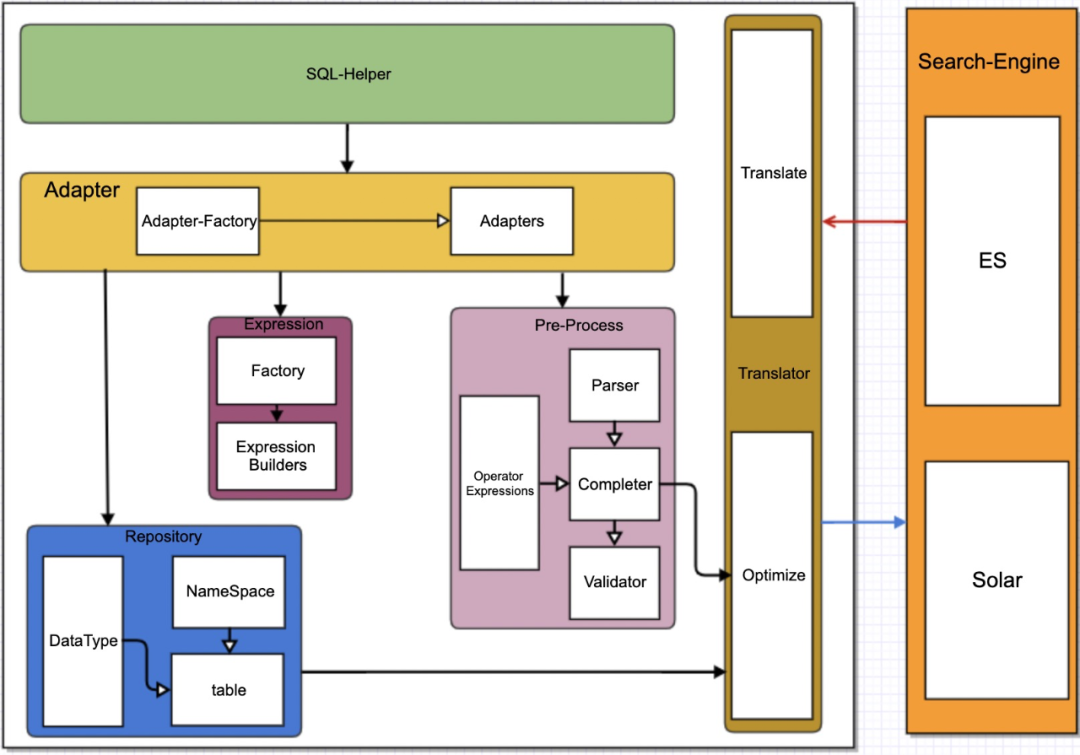
為此,我們設計了一套:適配多引擎、業務自定義、SQL檢索框架。整體架構上,參考了Apache Calcite。
SQL-Helper:我們提供了SQL拼裝工具,用戶可以像寫JAVA那樣完成SQL書寫,防止SQL拼寫錯誤帶來的調試效率問題;
Adapter:適配層模塊,基於底層引擎進行適配、路由;
Parser:SQL解析模塊;
Completer:語句補全、替換等;
Validater:語句校驗模塊;
Tanslator:語句轉義為底層引擎請求,並進行參數優化;
五、使用文檔
https://help.aliyun.com/document_detail/185713.html?spm=a2c4g.11174283.6.712.2d924c07H2j7X7