作者:閒魚技術-雲聽
背景
在之前的文章中,我們介紹了納米鏡的功能和背後的分析算法,而閒魚目前業務線多且複雜,怎麼構建一個可擴展性強的系統,使每個業務線都能夠便捷地接入,成為首要關注的問題。
思路分析
標準數據集
納米鏡的分析算法,輸入輸出是固定的,要求輸入是一個固定的標準ODPS數據集,字段包含userid/分桶id/人群切面1/人群切面2/指標1/指標2等,但實際業務場景中,每個業務關注的人群切面與數據指標都是大相徑庭的,為了在約束中尋找靈活性,我們必須對納米鏡的標準數據集做些改造。
由於納米鏡存在數據集依賴,比如說預測算法和切面顯著性算法,就需要依賴具體的某張表去做二次計算,比較好的解決方案是讓業務方按照數據集規範往標準數據集的中間表裡面插數據。
數據集自動生成
只要讓每個業務將自己的數據按照標準數據集的規範插入到納米鏡中間表中,就能開始使用納米鏡的功能。但實際場景中,業務產出數據集的開發成本很大,並且這種方式對使用方的開放權限很大,假如使用方不按照規範插入數據,會對源數據造成汙染,使其變得不可控。那是否能做到數據集自動生成,讓使用方不需要關注數據採集流程呢?
可以看看,在平常的業務開發流程中,生成ODPS數據源的工作流程是: 
這整個過程下來,一般都會花費至少2天(1天埋點梳理與開發、1天寫SQL生成報表)的時間,並且很多時候會出現埋點遺漏的問題,又需要重新走一遍開發和發佈流程,造成很多人力上的浪費。
方案設計
標準數據源制定
數據集中的數據類型是固定的,數據類型下字段名稱和值可以是靈活的。
在數據集上,我設計這種一種數據格式,參考:
userid: 用戶userid
bucket_id:bucket_A
indexes: index_visit=1,index_ipv=2
tags: tag_sex=F,tag_age=19
業務數據集自動生成
行業成熟方案及缺點
數據自動生成,意味著上面提到的常規數據開發流程直接抹除,不需要關注埋點開發、也不需要跨專業領域去寫SQL,頁面只要一上線,活動數據就會自動存儲到納米鏡的標準數據源中。要做到無埋點,業界有類似的方案,也叫做“全埋點”,自動採集坑位曝光點擊,但這個方案的缺點很明顯:
1、上傳數據是dom節點位置信息,清洗麻煩,並且擺脫不了寫SQL的工作
2、增加帶寬、服務器壓力(每個坑位的曝光點擊,無論是否需要都會上傳)
3、業務侵入太強(weex下要監聽坑位曝光事件,模塊開發時需引入定製組件)
4、攜帶不了trackparam信息(實際業務場景還會關注更多業務信息 eg.商品id/分桶/紅包金額)
提取用戶行為的最大公約數
本質上,業務關注的是用戶行為。我對歷史埋點開發的數據做了統計,梳理出業務關注的用戶行為類型,包含點擊跳轉頁面、紅包曝光、紅包領取、紅包金額、分桶id、渠道等。並且發現,所有這些用戶行為,底層都經過了頁面跳轉/HTTP接口請求/url傳參這幾個API調用,如果API調用的輸入輸出是可固化的,那理解用戶行為的業務語義並採集上報,就具備可能性!
最終方案
要做一個適用所有業務(閒魚/手淘/天貓)的用戶行為採集方案,技術實現上不可能,原因是每個業務自己的工程實現方案完全不同,也無法保持一致。不過對閒魚來說,工程基建基本成熟穩定,具有業務語義的用戶行為的API輸入輸出已固化,使實現一套只適用於閒魚的用戶行為自動採集技術方案具有了可能性。總體技術方案如下: 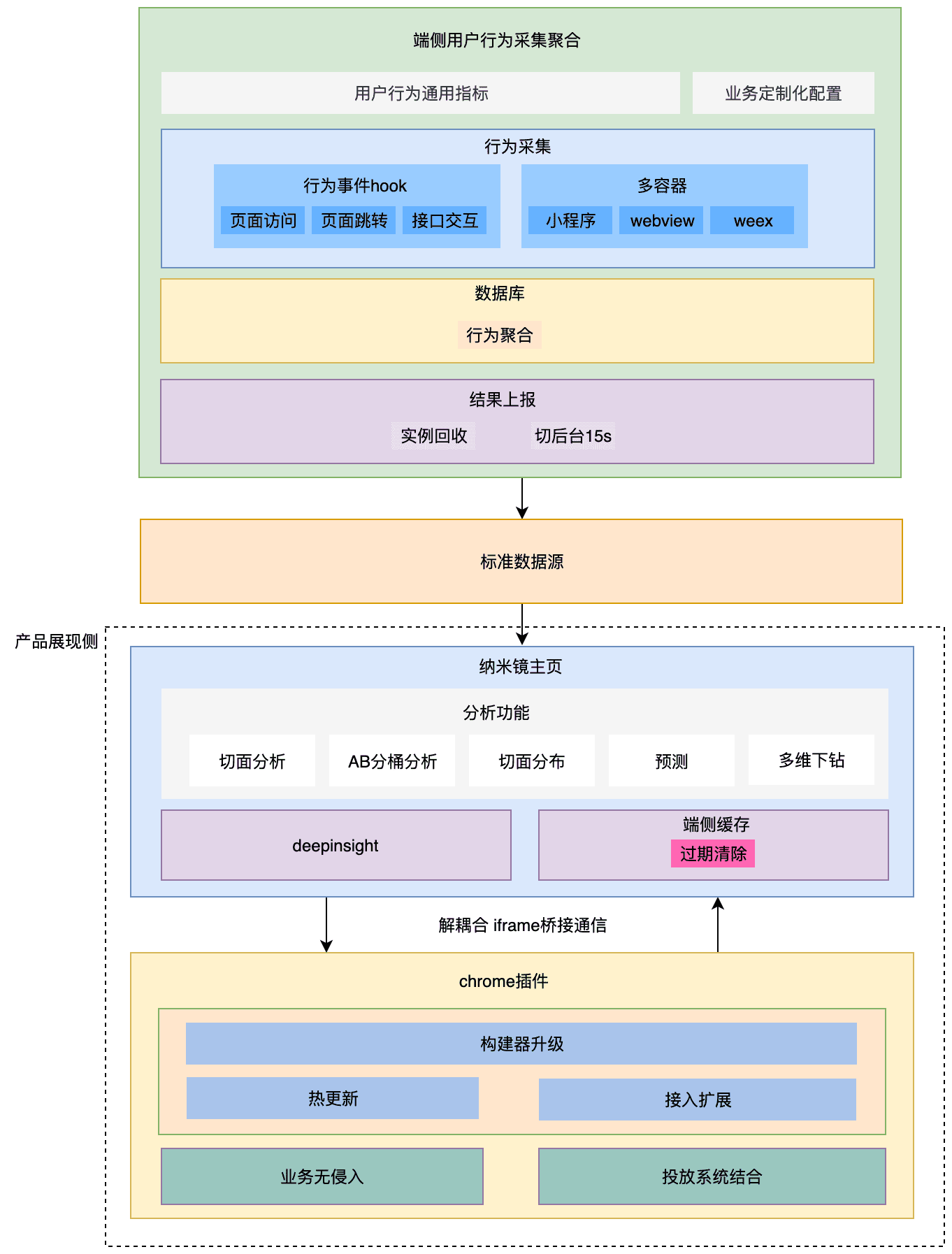
圖中下半部分的虛線部分:產品展現側本文不做太多擴展,本文主要講上半部分的,從端側用戶行為採集到生成納米鏡標準數據源。
相比全埋點,它的特點是:
1、靈活配置
2、減少帶寬、服務器計算壓力
3、業務無侵入
4、可攜帶trackparam信息
落地
hook API
閒魚前端封裝了一個util,頁面跳轉(navigator)、http請求(mtop)都由它暴露出來給開發使用,具體調用方式是navigator.push()、mtop.request()。使用Proxy代理對這兩個API進行hook。這裡以navigator為例。
navigator['push'] = new Proxy(navigator['push'], {
get(target, propKey) {
return target[propKey];
},
set(target, propKey, value) {
target[propKey] = value;
return target[propKey];
},
apply(target, thisArg, args) {
// 先執行原邏輯
const result = target.apply(this, args);
// 是否指定忽略納米鏡分析
const ignoreNanoAnaly = args && args[0] && args[0].api && args[0].ignoreNanoAnaly;
if (ignoreNanoAnaly) {
return result;
}
if (result instanceof Promise && result.then) {
result.then(d => {
// 這裡寫入監聽邏輯
// ...
return Promise.resolve(d);
}).catch(e => {
// 這裡寫入監聽邏輯
// ...
return Promise.reject(e);
});
}
return result;
}
});用戶行為採集通用配置與可定製化配置
閒魚目前已沉澱下成熟的一套用戶行為採集通用配置,滿足業務方數據分析時的各種數據指標訴求,並且,我們還支持定向擴展,可對具體的頁面spmId定製自己個性化的用戶行為指標,具體的配置參數與含義參考以下demo。
{
"spms": [{
"spm": "common", // 用戶行為通用配置 會對所有頁面產生的用戶行為進行匹配
"tasks": [{
"indexType": 0, // 0代表指標 1代表bucket_id 2代表infos 3代表擴展信息 默認0 這裡主要是需要與納米鏡的標準數據源建立映射關係
"index": "index__ipv", // 指標名稱 IPV
"behavior": [
{
"type": 0, // 用戶行為類型 0代表navigator 1代表mtop 2代表location.href
"condition": "fleamarket://item", // 正則匹配是否目標行為 type=navigator匹配下跳url;type=mtop匹配接口返回值 不校驗填true
"valueType": "1" // 指標數值類型 0代表boolean 1代表count 字符串屬性鏈代表對應取對應值
}
]
}]
}, {
"spm": "spma.spmb",
"match_uv": true, // 是否採集頁面uv 默認指標名稱是 index__visit
"tasks": [{
"indexType": 0,
"index": "index__gold_copper", // 金寶箱是否打開
"behavior": [{
"type": 1, // mtop接口請求的行為類型
"api": "mtop.api.lottery.draw", // 抽獎接口api名稱
"condition": "d.data.status===5", // mtop返回值符合該正則匹配 則認為符合採集記錄條件 status==5代表用戶成功打開了金寶箱
"valueType": "0" // 是否領取成功 0/1
}]
}]
}]
}行為聚合與上報
為了減少帶寬和服務器計算壓力,每次採集到的用戶行為不會立即上報,而是把整個頁面實例生命週期的用戶行為做聚合,直到頁面被銷燬或者應用從前臺切到後臺15秒後做統一上報。
上面提到的demo,假設用戶在spmId為spma.spmb的頁面點擊跳轉了10次商品詳情頁,並打開了金寶箱,最終上報到服務器日誌的數據長這樣:
{
"page": "spma.spmb",
"indexes": "index__visit=1,index__ipv=10,index__gold_copper=1"
}效果
目前,已經有多個業務通過這種方式靈活輕便地接入納米鏡,eg. 邊逛邊賺錢、侃侃刀、報價單、322閒魚大促等等,從原本要花費至少2人日的開發量,到只要活動上線,即可上手納米鏡查看活動智能分析結論,整體納米鏡使用體驗和使用效率都獲取了極大的提升。
未來
目前納米鏡設計的業務接入模式,已能夠滿足業務0成本接入,如果有更多定製化數據指標訴求,也支持低成本地動態配置。
未來,納米鏡會在數據科學的道路上深入鑽研,現階段我們更多在理解人,也在嘗試從浩如煙海的歷史活動中抽象沉澱知識庫,並且開始嘗試理解貨,理解人與貨之間的喜好關係,並建立人與貨之間的匹配關係。
想了解更多細節,就請繼續關注閒魚公眾號吧。