Linked大佬Jay Kreps曾發表過一篇博客,簡單闡述了他對數據倉庫架構設計的一些想法。從Lambda架構的缺點到提出基於實時數據流的Kappa架構。本文將在Kappa架構基礎上,進一步談數倉架構設計。
什麼是Lambda架構?
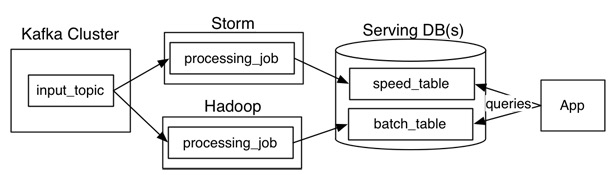
借用Jay Kreps的一張圖來看,Lambda架構主要由這幾部分構成:數據源(Kafka),數據處理(Storm,Hadoop),服務數據庫(Serving DB)。其中數據源和服務數據庫是整個架構數據的入口和出口。數據處理則是分為在在線處理和離線處理兩部分。
當數據通過kafka消息中間件,進入Lambda架構後,會同時進入離線處理(Hadoop)和實時處理(Storm)兩個處理模塊。離線處理進行批計算,將大量T+1的數據進行彙總。而實時處理則是進行流處理或者是微批處理,計算秒級、分鐘級的結果。最後都錄入到服務數據庫(Serving DB)中進行彙總,暴露給上層服務調用。
Lambda架構的好處是:架構簡單,很好的結合了離線批處理和實時流處理的優點,穩定且實時計算成本可控。
此外,它對數據訂正也很友好。如果後期數據統計口徑變更,重新運行離線任務,則可以很快的將歷史數據訂正為最新的口徑。
然而,Lambda也有很多問題。
其中Jay Kreps認為最突出的問題就是需要同時維護實時處理和離線處理兩套代碼的同時還要保證兩套處理結果保持一致。這無疑是非常讓人頭疼的。
什麼是Kappa架構
Jay Kreps認為通過非常,非常快地增加並行度和重播歷史來處理重新處理實時數據,避免在實時數據處理系統上再“粘粘”一個離線數據處理系統。於是,他提出了這樣的架構:

Kafka或者其他消息中間件,具備保留多日數據的能力。正常情況下kafka都是吐出實時數據,經過實時處理系統,進入服務數據庫(Serving DB)。
當系統需要數據訂正時,重放消息,修正實時處理代碼,擴展實時處理系統的併發度,快速回溯過去歷史數據。
這樣的架構簡單,避免了維護兩套系統還需要保持結果一致的問題,也很好解決了數據訂正問題。
但它也有它的問題:
1、消息中間件緩存的數據量和回溯數據有性能瓶頸。通常算法需要過去180天的數據,如果都存在消息中間件,無疑有非常大的壓力。同時,一次性回溯訂正180天級別的數據,對實時計算的資源消耗也非常大。
2、在實時數據處理時,遇到大量不同的實時流進行關聯時,非常依賴實時計算系統的能力,很可能因為數據流先後順序問題,導致數據丟失。
例如:一個消費者在淘寶網上搜索商品。正常來說,搜索結果裡,商品曝光數據應該早於用戶點擊數據產出。然而因為可能會因為系統延遲,導致相同商品的曝光數據晚於點擊數據進入實時處理系統。如果開發人員沒意識到這樣的問題,很可能會代碼設計成曝光數據等待點擊數據進行關聯。關聯不上曝光數據的點擊數據就很容易被一些簡單的條件判斷語句拋棄。
對於離線處理來說,消息都是批處理,不存在關聯不上的情況。在Lambda架構下,即使實時部分數據處理存在一定丟失,但因為離線數據佔絕對優勢,所以對整體結果影響很小。即使當天的實時處理結果存在問題,也會在第二天被離線處理的正確結果進行覆蓋。保證了最終結果正確。
Flink(Blink)的解法
先整理一下Lambda架構和Kappa架構的優缺點:
|
優點 |
缺點 |
|
|
Lambda |
1、架構簡單 2、很好的結合了離線批處理和實時流處理的優點 4、穩定且實時計算成本可控 5、離線數據易於訂正 |
1、實時、離線數據很難保持一致結果 2、需要維護兩套系統 |
|
Kappa |
1、只需要維護實時處理模塊 2、可以通過消息重放 3、無需離線實時數據合併 |
1、強依賴消息中間件緩存能力 2、實時數據處理時存在丟失數據可能。 |
Kappa在拋棄了離線數據處理模塊的時候,同時拋棄了離線計算更加穩定可靠的特點。Lambda雖然保證了離線計算的穩定性,但雙系統的維護成本高且兩套代碼帶來後期運維困難。
為了實現流批處理一體化,Blink採用的將流處理視為批處理的一種特殊形式。因此在內部維持了若干張張流表。通過緩存時間進行約束,限定在一個時間段內的數據組成的表,從而將實時流轉為微批處理。
理論上只要把時間窗口開的足夠大,Flink的流表可以存下上百日的數據,從而保證微批處理的“微”足夠大可以替換掉離線處理數據。
但這樣做存在幾個問題:
1.Flink的流表是放在內存中,不做持久化處理的。一旦任務發生異常,內存數據丟失,Flink是需要回溯上游消息流,從而轉為Kappa的結構。
2.數據窗口開的越大,內存成本越高。受限於成本,對大量數據處理仍然有可支持的物理空間上限。
3.下游接收的通常都是處理結果,對於內存中的流表數據是無法直接訪問的。這樣無形中增加了開發成本。
結合以上幾個問題,我們提出了混合數倉架構。試圖在綜合實時數倉和離線數倉的優點,儘量規避各自的缺點。
混合數倉(Omega架構)的解法
什麼是ECS設計模式
在談我們的解法的時候,必須要先提ECS的設計模式。(詳細請參考:https://www.atatech.org/articles/151514?spm=ata.13269325.0.0.4e0c49fabVdLmJ)
簡單的說,Entity、Component、System分別代表了三類模型。
實體(Entity):實體是一個普通的對象。通常,它只包含了一個獨一無二的ID值,用來標記它是一個獨立的對象。
組件(Component):對象一個方面的數據,以及對象如何和世界進行交互。用來標記實體是否需要進行這一方面的處理,通常使用結構體,類或關聯數組實現。
系統(System):每個系統不間斷地運行(就像每個系統運行在自己的私有線程上),處理標記使用了該系統處理的組件的每個實體。
Entity對應於數倉中的Table,Component對應Schema,System對應數倉中SQL邏輯。
對於數倉來說,每張表的意義是由一群schema決定的。而每一個schema只代表一個含義。SQL代碼的作用是組裝schema到對應的table中,實現它的業務意義。對於一個OLAP系統,我們喜歡大寬表的意義就是因為OLAP分析的是schema之間的關係,用大寬表可以很輕易的提取所需要的schema,組裝一個業務所需的表。
ECS設計模式的核心思想就是,所有shcema都獨立出來,整個數倉就是一個大寬表。當需要使用的時候,把對應的schema組裝成具有業務含義的table。這就像一個個Component組裝成一個Entity一樣。而SQL在其中起到的作用是就是產出對應的schema和組裝schema。
將ECS設計模式引入數倉設計,希望開發者可以更加關注於邏輯,關注數據如何處理,也就是S的部分。業務則由從列構建表的時候產生。將表結構和數據處理邏輯進行拆分,從而希望能提升SQL代碼的可讀性和結構性。
傳統數倉的數據處理流程
數倉通常是分為三層:ODS(原始數據),DW(數據倉庫層),ADS(應用數據層)。ODS是從消息中間件中拿到的最原始的數據。DW層則是對數據進行加工後的數據,通常還是分為:DWS和DWD。DWD層中是對ODS層的數據進行清洗後提取的出來的。而DWS層是經過了一些輕度彙總後的數據。用戶可以基於此層直接加工出ADS層所需的數據。ADS層則是產出應用最終所需的數據。
所以我們一般的數倉數據處理流程是:
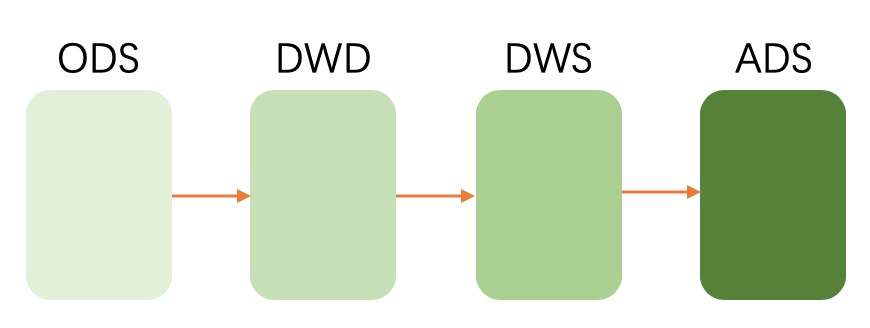
基於ECS設計模式設計的混合數倉
在ECS的設計模式下,核心考慮的是Component是產出。產出具有業務含義的component,組裝出具體的業務表(Entity)。
Schema的註冊和Table註冊
對應在數倉模型中,可以這麼理解:數倉裡的表,任何一個schema都是獨立的。它們不具有業務含義,只是業務的一個屬性。組合起來構成一個具有業務含義的表。
因此,我們需要一個專門管理schema的系統。這裡包含了schema註冊和shcema使用。schema註冊系統主要負責對schema唯一性作保證,避免schema重複從而影響使用。同時規定好Schema從元數據中提取的規則(正則表達式或者拆分字符串),保證不論在什麼系統中都可以得到唯一的提取結果。
schema的使用則依賴table註冊系統。通過table註冊系統,將一些具有相關含義的schema串聯起來,形成table提供給業務使用。
如下圖:
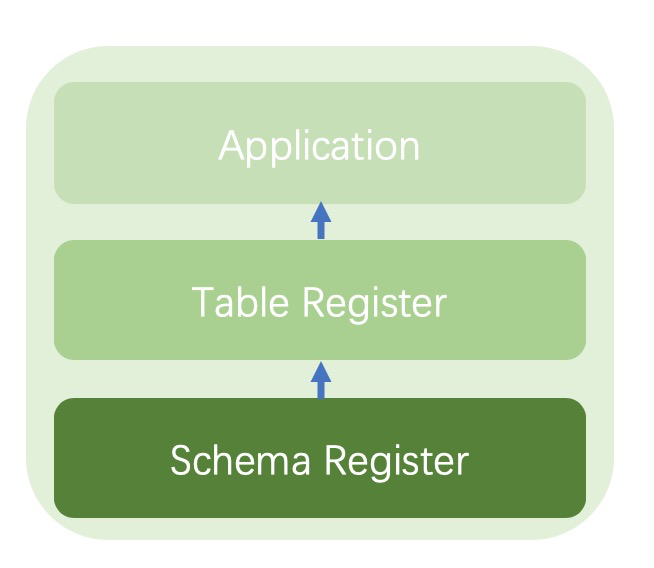
Schema開發與混合數倉架構
有了schema註冊,就要提到schema產出的問題了。在上文提到過,在Lambda架構下,離線實時數倉需要同時維護兩份代碼,其實就是需要維護兩份schema的註冊和產出過程。在Kappa架構中,雖然只需要在實時數倉中做數據處理,但面對大量歷史數據處理時需要消耗非常多的資源,而且中間結果複用能力有限,不適合複雜的業務。
由於我們將schema 註冊抽離出來,在ECS的設計模式下,數據加工過程只有schema之間的交互,所以只需要關心數據加工部分代碼。而對於Flink(Blink)與MaxCompute(ODPS)來說,數據處理部分的sql代碼都遵循相近的SQL規範(這裡沒查到對應的SQL版本,但使用過程中感受是幾乎一致,差別在於一些函數上。這一點可以通過UDF等方式解決。),所以可以保證很好的複用性。如果實時數倉和離線數倉數據處理層面的代碼差異較大的話,可以引入編譯器的形式解決。在任務提交的時候對代碼進行差異化的編譯,適用於對應的數倉。
從而我們可以畫出以下的架構圖:
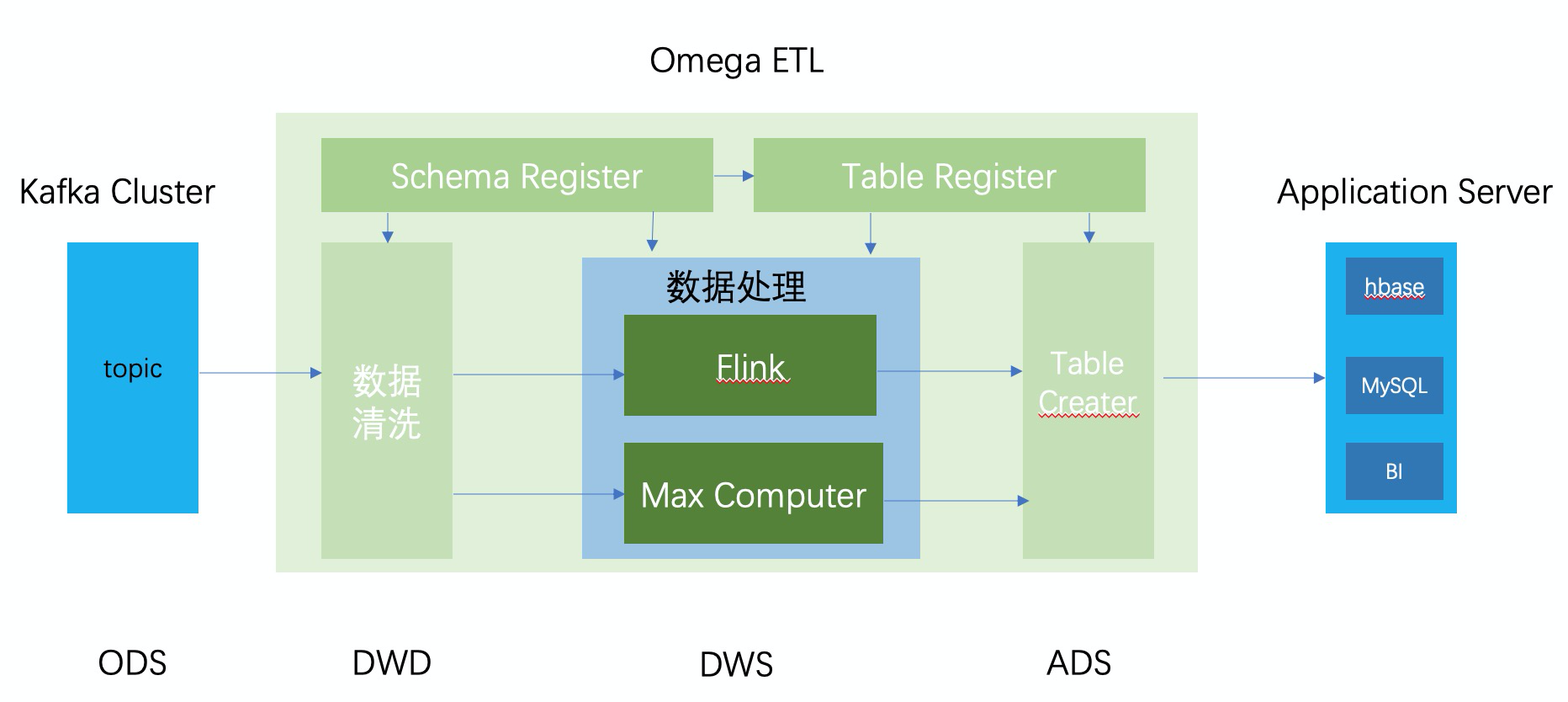
Kafka傳入的消息是這套架構的ODS層,這一點上跟Lambda和Kappa架構是保持一致的。
數據進入數倉後,數據會被Schema Register中註冊的規則提取出來,產出一個個對應的schema。即對應DWD層。
有了schema後,數據進入處理加工邏輯。即System部分。這裡需要針對實時和離線數倉分別產出對應的加工代碼,並執行具體的加工。此處對應的是DWS層。
最後,將加工後產出的schema和table Register系統結合,產出最終的ADS層的數據。
這套架構的好處是通過ECS設計模式的思想,將數據處理過程拆分成:數據聲明(Schema Register,Table Register),數據處理(System)和結果拼接(Table Creater)三個流程。在這三個過程中,將Flink、Max Compute視為計算資源,將整體數據加工處理的邏輯獨立在底層中間件之上,與開發環境解耦。從而實現工程化的管理數據倉庫裡的數據和加工過程。
但這套架構也存在一定的問題。例如,實時數據和離線數據是不互通的。如果統計過去180天UV總數時,需要離線和實時數據合併去重的處理就會遇到麻煩。
總結
我將這個架構命名為Omega架構,對應希臘字母中的Omega,含義是“終結”。我希望這套架構能解決目前實時數倉和離線數倉比較混亂的局面,可以讓大數據開發、管理的能力更上一個臺階,讓更多小夥伴可以更加方便的取數,加工,從而更好的服務於業務。