作者:手辨
實為吾之愚見,望諸君酌之!聞過則喜,與君共勉
第一章 情景模擬
第一節 工具準備
準備一些需要的工具,方便後面的虛擬場景
1.1.1 模擬密碼本A
密碼本A的字符座標規則:假設一個字符的密文由三部分組成,順序分別是"U+5600的56"+"表格最上方的座標"+"表格最左邊的座標",舉例"570B"是"國","56E7"是"囧",如下第一個和第二個密碼錶,這些密文是16進制的格式,下同





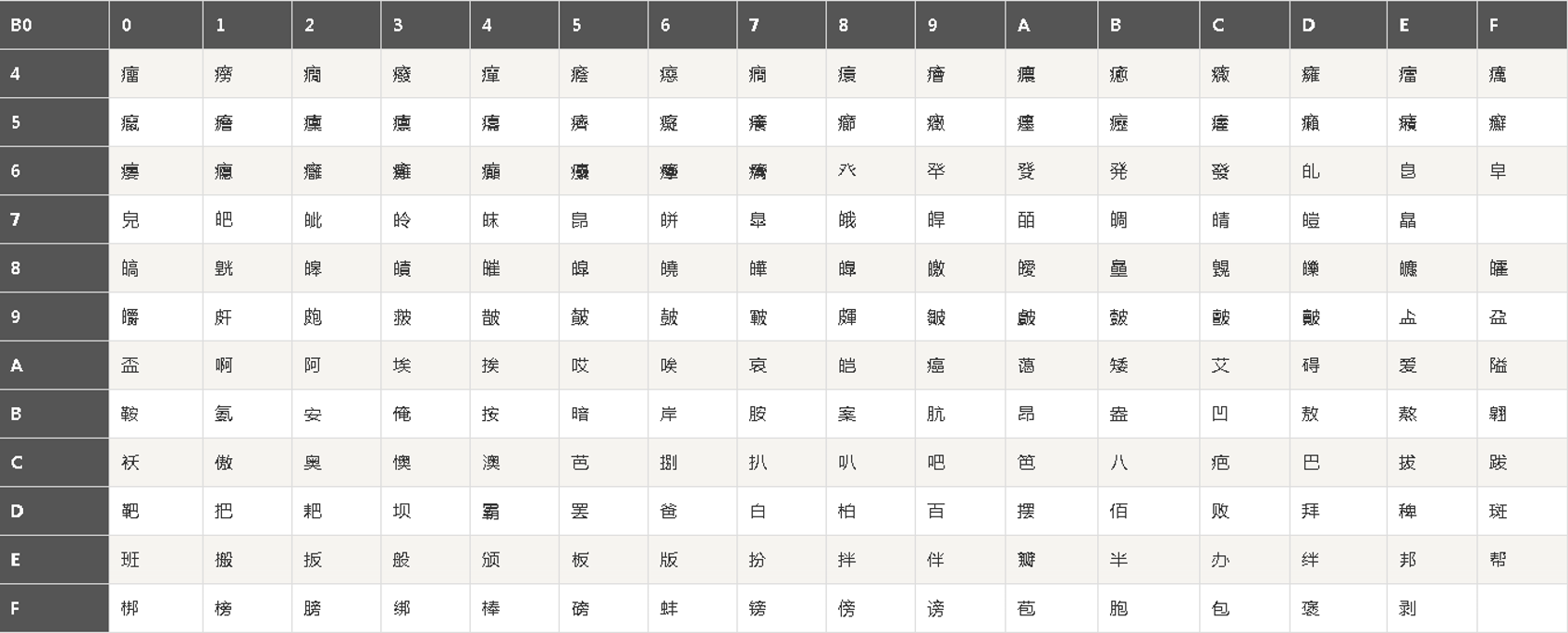
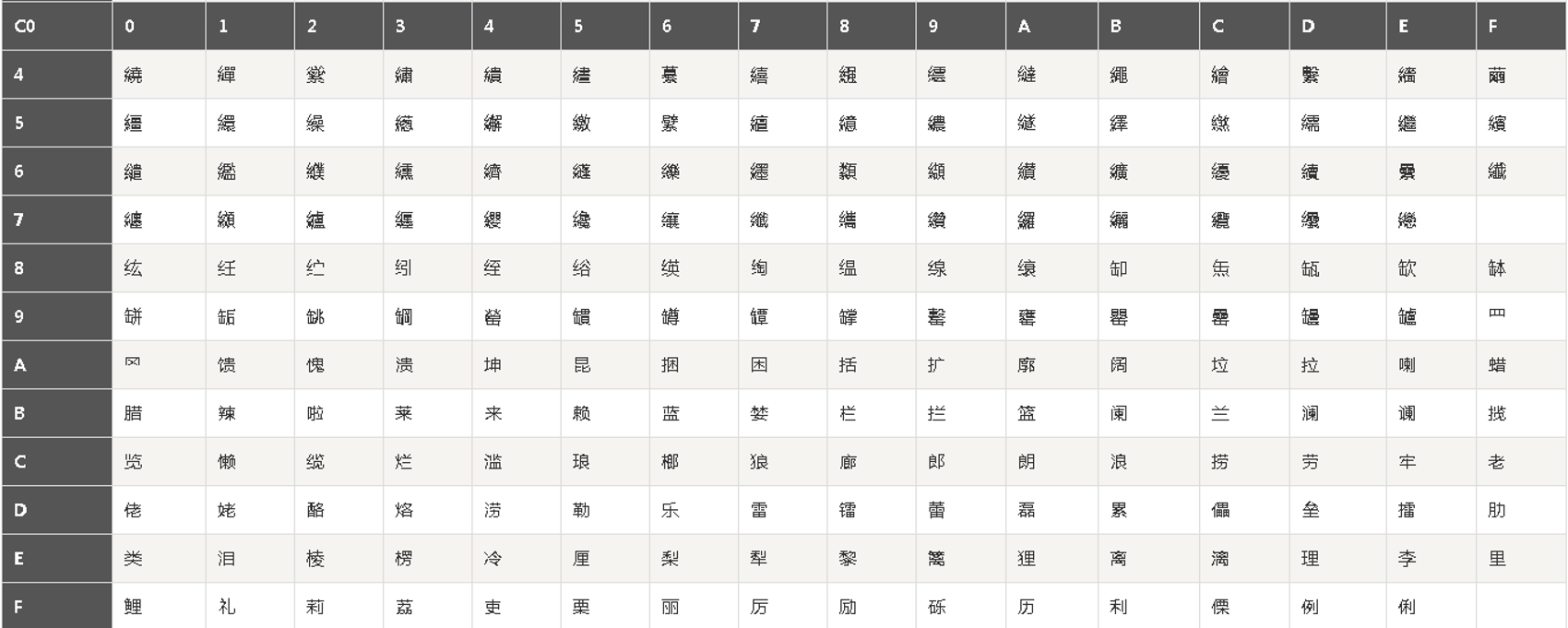
1.1.2 模擬密碼本B
密碼本B的字符座標規則:假設一個字符的密文由三部分組成,順序分別是"表格左上角的字符串"+"表格最左邊的座標"+"表格最上方的座標",舉例"87E5"是"囧","87F8"是"國",如下第一個密碼錶,這些密文也是16進制的格式,下同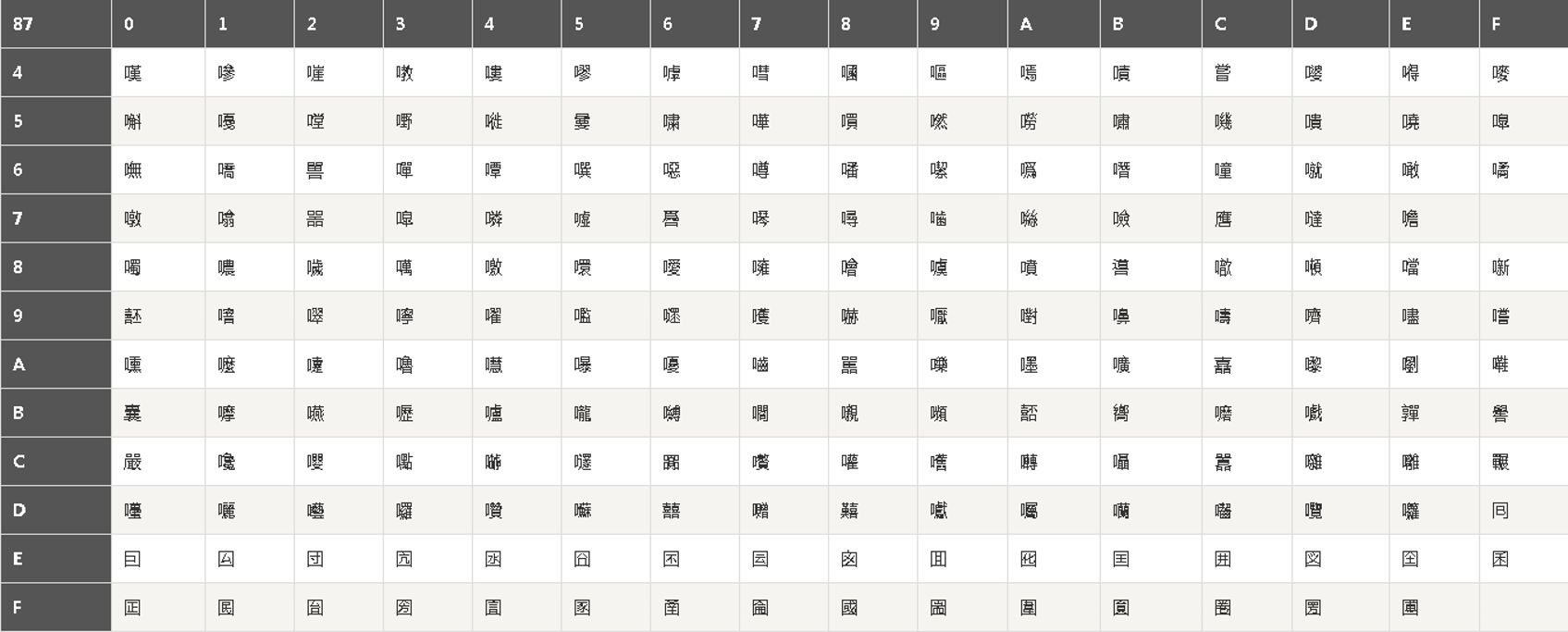

1.1.3 密文的加密規則
即我們可能還需要對我們拿到的密文進行再一次的加密,比如”囧”的密文是” "56E7”按照開頭假設的密文規則,這是16進制的數,那我們還需要把這個16進制的56E7通過一定的規則,再次加密,針對這兩個密碼本的加密規則假設如下:
密碼本A密文再次加密規則:
|
16進制密文轉換為10進制後對應的範圍 |
16進制數轉換為2進制後對應的加密格式 |
|
0至127 |
0xxxxxxx |
|
128至2047 |
110xxxxx 10xxxxxx |
|
2048至65535 |
1110xxxx 10xxxxxx 10xxxxxx |
|
65536至2097151 |
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
比如56E7這個密文再次加密,他轉換成10進制是22247,22247在”2048-65535”的範圍內,那他的加密格式就是1110xxxx10xxxxxx10xxxxxx,暫且稱它為466格式,如何加密呢?如下:
- 先把56E7轉換成二進制為:0101011011100111
- 按照1110xxxx 10xxxxxx 10xxxxxx的格式,對56E7轉換成的二進制0101011011100111進行拆分:
首先,0101011011100111--------按照4 6 6的格式拆分後--------->0101 011011 100111
然後,對0101 011011 100111按照466格式進行轉換------->11100101 10011011 10100111
把轉換後的111001011001101110100111轉換為16進制就是e59ba7,e59ba7就是56E7再次加密的最終密文,這樣就由原來的"56E7"是"囧"變成" E59BA7"是"囧",甚至可以根據這個加密方式,生成一個新的密碼本C
密碼本B的再次加密規則:
密碼本B的16進制密文不再進行二次加密,直接使用獲得的16進制密文,例如56E7不會與密碼本A一樣再次加密,直接使用56E7
第二節 漫畫情景
1.2.1 情景故事
模擬一個虛構的場景,場景裡的元素是:
- 遠在外地的小明
- 與小明同部門的小麗
- 安全部門的同學
- 與小明同部門的小紅
- 一個信息安全非常嚴格的公司
- 加密的檔案管理
今天,小明需要將一個很重要的數據,告訴公司的小麗把這個數據存到小明自己的檔案裡:



、
小明發現,他獲取到的數據是“闃塊噷”,而不是3天前存儲的”阿里”,如果小明意識到自己的錯誤,把小紅寄給他的數據先轉換成密碼本B的密文,再用轉換的密文對照密碼本A查找呢?
第二章 Mysql的亂碼
如果上面的場景,放到數據庫裡,會一樣嗎?拿mysql作為例子,測試一下,數據從客戶端發送到server並存入表中成為數據然後查詢該數據的過程,mysql中控制這個過程的編碼的參數主要是character_set_client,character_set_connection,character_set_results,表字符集以及程序字符集等,可以看下文檔。
第一節 mysql的情景對應
字符集:
unicode gbk
字符編碼規則:
utf8:只針對unicode,相當於第一章情景中的二次加密
gbk:不對gbk再編碼
參數與情景對應:
程序字符集:小明加密數據時使用的密碼本A
character_set_client:小明在寄信時,寫錯了數據加密方式,寫的是密碼本B,而不是A
character_set_connection:安全規則,需要轉換的加密格式
character_set_results:寄信時需要使用的加密格式
表或者庫字符集:小明的檔案的加密格式
Server端處理:小麗/小紅
第二節 mysql測試
2.2.1 第一次測試
參數設置:
程序字符集:utf8
character_set_client:utf8
character_set_connection:utf8
character_set_results:utf8
表或者庫字符集:utf8
Server端處理:mysql program 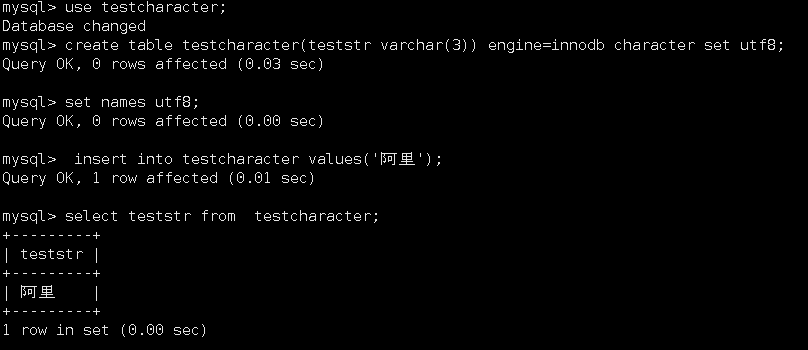
測試結果:無亂碼
2.2.2 第二次測試
參數設置:
程序字符集:utf8
character_set_client:gbk
character_set_connection:utf8
character_set_results:utf8
表或者庫字符集:utf8
Server端處理:mysql program 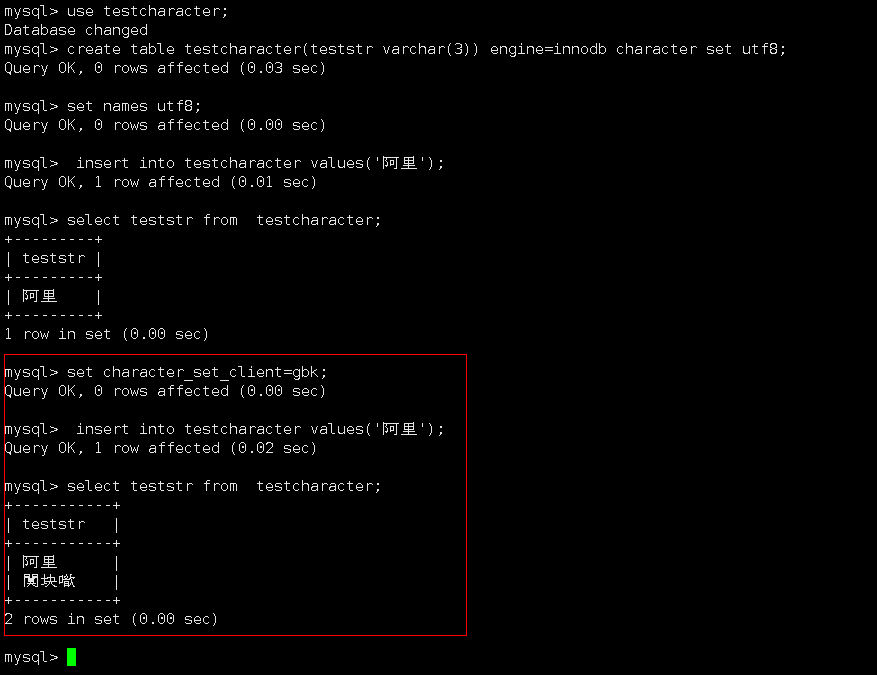
測試結果:只設置set character_set_client=gbk後,查詢亂碼
2.2.3 亂碼猜猜猜
結合第一章的場景,為什麼亂碼呢?
2.2.3.1 第一步處理
程序將"阿里"以utf8編碼進行轉換髮送(unicode轉utf8與情景中的規則一致),但是不小心在session中設置了character_set_client=gbk,character_set_connection =utf8,character_set_results=utf8,類似如下現象:
形狀:阿里
Utf8方式下的16進制編碼值:E998BF E9878C
二進制:11101001 10011000 10111111 11101001 10000111 10001100(utf8將2個漢字轉換後6個字節)
2.2.3.2 第二步處理
到達server端,server通過character_set_client=gbk知道客戶端發過來的數據是gbk編碼的(實際是utf8編碼的,客戶端不小心寫錯了),那server端就按照gbk來解碼了,解碼後如下:
二進制:11101001 10011000 10111111 11101001 10000111 10001100(程序端的兩個漢字經過utf8轉換後的二進制數據,一共6字節,但是server端不知道,因為server通過character_set_client=gbk得知,這不是utf8,這是gbk的,我要按照gbk來解碼)
gbk轉換後的16進制編碼值:E998 BFE9 878C(通過這個編碼,查找gbk的碼錶,獲取他的形狀為:闃塊噷)
2.2.3.3 第三步處理
Servre還需要檢查character_set_connection參數,發現character_set_connection=utf8,而之前是gbk,那就需要將gbk的這三個字節轉換為utf8,怎麼轉換呢?按照第一章的情景,先轉unicode(密碼本A),再將得到的unicode再次編碼為utf8:
“闃塊噷“三個字符的unicode編碼是 95c3 5757 5677
轉換成二進制:10010101 11000011 01010111 01010111 01010110 01110111(這三個漢字是6個字節)
通過unicode,再轉換為utf8的實現方式,實現方式如下:
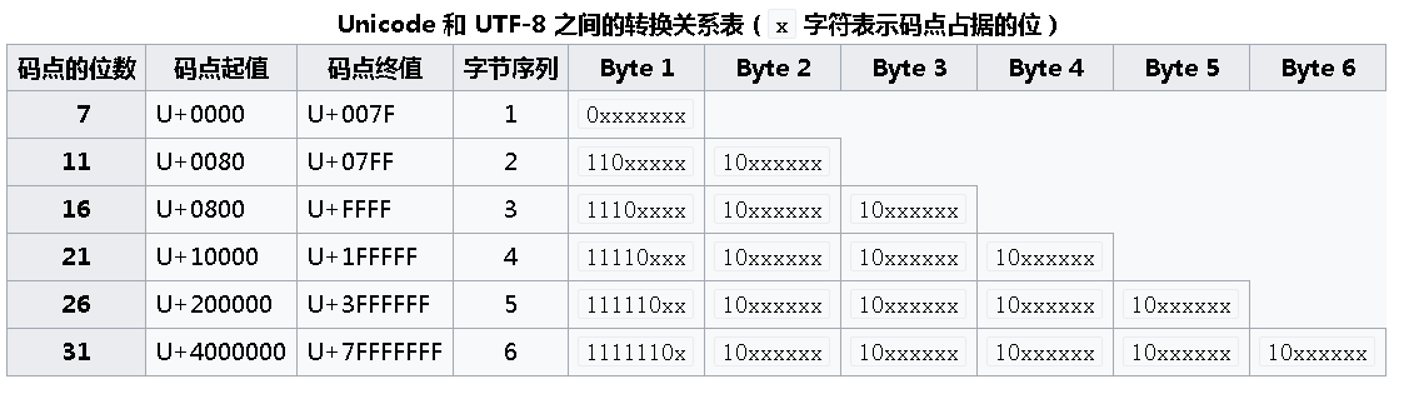
首先轉換95c3( 1001010111000011),他的範圍在第三行(3字節)
1001 010111 000011,根據第三行的格式,從低位往高位的順序,按照格式分成4 6 6 的格式
按照格式填充,填充後:11101001 10010111 10000011,填充後轉換成16進制是e99783,則”闃”在utf8中就是”e99783”,同樣,”塊”在utf8中就是” e59d97”,” 噷”在utf8中就是” e599b7”, 於是轉換後的結果就是:
編碼:E99783 E59D97 E599B7
二進制:111010011001011110000011111001011001110110010111111010000000000000000000
2.2.3.4 第四步處理
server端處理好之後,繼續向下走,準備存儲數據了,檢查了存儲的表是utf8的,不需要轉換了,直接存儲
編碼:E99783 E59D97 E599B7
二進制:111010011001011110000011111001011001110110010111111010000000000000000000
2.2.3.5 查詢返回
程序插入完成後,想查詢下之前插入的數據,於是客戶端在當前session下執行了select操作,server端收到請求後,去表裡找數據,找到了之前寫入的數據
111010011001011110000011111001011001110110010111111010000000000000000000
server檢查character_set_results=utf8,與表的字符編碼是一致的,那就不需要轉換了,直接把111010011001011110000011111001011001110110010111111010000000000000000000給程序了,程序收到後,就解碼111010011001011110000011111001011001110110010111111010000000000000000000,因為程序本身也是utf8的,不需要轉換,於是按照utf8來解碼數據,111010011001011110000011111001011001110110010111111010000000000000000000的16進制是E99783E59D97E599B7(符號是闃塊噷,亂碼了)