Optane Memory結構
結構總覽
英特爾的Cascade Lake處理器是第一個(也是目前唯一一個)支持Optane DIMM的CPU。Optane DIMM與普通的DRAM一樣位於內存總線上,並連接到處理器的iMC (integrated memory controller),如圖1(a)所示。圖中所示的CPU包含兩個iMC,每個iMC包含3個channel。
iMC位於ADR(asynchronous DRAM refresh )域中,其保證了數據從cache flush完成後,便可保證數據的持久性。或說ADR特性保證了在發生了掉電故障時,iMC可以將數據刷入3D-XPoint介質(保證100us內,將數據寫入NVDIMM)。如圖1(b)所示,每個Optane DIMM的ADR區域都包含RPQ和WPQ( read and write pending queues ),當數據到達WPQ,便保證了數據不丟。因為,處理器的cache不屬於ADR域,所以只有當屬於cache的數據寫入WPQ,才能保證持久性。
iMC與Optane DIMM 通過DDR-T接口以cache line粒度(64B)通信。DDR-T的接口允許異步命令和數據定時(asynchronous command and data timing)。

如圖1(b)所示, 對NVDIMM的訪問首先到達DIMM上的控制器(本文中稱為XPController),該控制器協調對Optane介質的訪問。與SSD相似,Optane DIMM執行內部地址轉換以實現損耗均衡和壞塊管理,併為該轉換維護AIT (address indirection table)。
地址轉換後,將實際訪問存儲介質。由於3D-XPoint物理介質的訪問粒度為256B(文中稱為XPLine),所以,XPController會將較小的請求轉換為較大的256字節的訪問以提升性能。然而,因為同樣的原因,小數據量的存儲會變為RMW(read-modify-write)操作而導致寫放大。 XPController有一個小的寫合併緩衝區(在本文中稱為XPBuffer),用於合併地址相鄰的寫操作。 由於XPBuffer屬於ADR域,因此到達XPBuffer的所有更新都是持久的。
Operation Modes
Optane DIMM支持兩種模式,Memory 模式和APP Direct模式。在Memory模式中,DRAM作為Optane DIMM的cache,而Optane DIMM作為易失的主存。在APP Direct模式中,Optane DIMM作為一個分開的PM,直接供其他應用如文件系統使用。
如圖1(c)所示,Optane memory可以被配置為交錯模式(interleaved across channels and DIMMs)。在現有的平臺中,支持的交錯大小為4 kB,這可以確保對單個page的訪問將只訪問單個DIMM,而如果有六個DIMM,則大於24 kB的訪問將訪問所有DIMM。
ISA (Instruction Set Architecture) Support
在App Direct模式下,應用程序和文件系統可以使用CPU指令訪問Optane DIMM。 ISA為程序員提供了許多選擇來控制數據寫入的順序。
應用程序使用store命令來將數據寫入Optane DIMM,寫入的數據最終被持久化。 但是,store命令的順序可能被重排,而無法進行正確的故障恢復。 當前的Intel ISA提供了clflush和clflushopt指令可將cache line刷回內存,而clwb可以對高速緩存行進行write back(不會evict)。也可以使用非臨時性存儲(例如ntstore)繞過高速緩存,直接寫入內存。 所有這些指令都是非阻塞的,使用sfence命令可確保之前的高速緩存的刷新,寫回或非臨時存儲操作是完整且持久的。
實驗系統和配置
系統描述
測試系統有兩個CPU槽(socket)。每個CPU為英特爾的Cascade Lake處理器。每個CPU有兩個iMC,每個iMC有3個內存通道(一個CPU共6個通道)。每個iMC內存通道綁定32GB DRR4 DIMM (2 socket × 6 channel × 32 GB/DIMM) 或 256GB Intel Optane DIMM (2 socket × 6 channel × 256 GB/DIMM) 。系統配置了384GB的DRAM和3TB的NVM。
實驗配置
本文主要測試,Optane DIMM作為一個持久性設備(即APP Direct模式)的性能,同時總結其使用指南。
Linux通過在物理內存的連續範圍內創建pmem namespace 來管理持久內存。後背實際的介質,可以由交錯(interleaved)或不交錯(non-interleaved)Optane memory支持,也可以通過DRAM仿真支持。 本文將測試這三種介質的性能差異。
介質性能特徵
本章通過實驗數據從多維度的描述Optane DIMM的性能特徵,其並不是簡單的比DRAM慢一些而已。這些特徵的描述能夠使用戶更加高效的使用該介質。
典型延遲(最好情況)
測試方法
讀延遲, 從順序和隨機存儲器地址中讀取8B的數據的平均延遲。 為了消除cache和queue的影響,我們清空了CPU流水線,並在兩次讀操作之間使用memory fence(mfence)操作。
寫延遲,先將cache line 加載到cache中,然後測量下面兩個指令序列中的任意一個的延遲:
64-bit store +clwb + mfence;
ntstore + mfence。測試結果及說明
測量的結構反映的是軟件看到的介質延遲,而不是底層介質本身的延遲。
對於讀,包含以下部件產生的延遲:on-chip interconnect,iMC, XPController, 和實際的3D-Xpoint 介質。
實驗結果(圖2)顯示,Optane的讀延遲比DRAM高2到3倍。 大部分差異是由於Optane的介質延遲更大導致的。 Optane也比DRAM更依賴於訪問模式。 DRAM的隨機訪問和順序訪問相比,性能差異為20%,而因為XPBuffer存在的原因,Optane的性能差異達80%。
對於寫,一旦數據到達iMC的ADR域,內存的store和fence指令就成功完成,因此DRAM和Optane的延遲相近。 非臨時存儲的開銷比使用高速緩存刷新(clwb)的開銷更大。

一般來說,同一種測試下,Optane的延遲差異非常小,表現為測試數據的方差很小。 例外的是,Optane DIMM的順序讀操作的延遲方差更大,這是因為第一個高速緩存行(64B)訪問將整個XPLine加載到XPBuffer中,隨後的三個訪問(因為測試讀時會清空高速緩存,這裡從存儲介質的視角出發,故 256/64 - 1 = 3)可直接讀取緩衝區中的數據。
Tail Latency
測試中,load和store的延遲非常的穩定。然而,當訪問集中在熱點(hot spot)時,延遲異常的store操作數會增加。圖3描述了尾部延遲和訪問局部性之間的關係。 該圖描述了 99.9th、99.99th以及最大延遲與熱點大小的關係。
測試方法
單個線程對一個熱點(為某個大小的循環緩衝區)進行2000萬個64字節的寫操作。
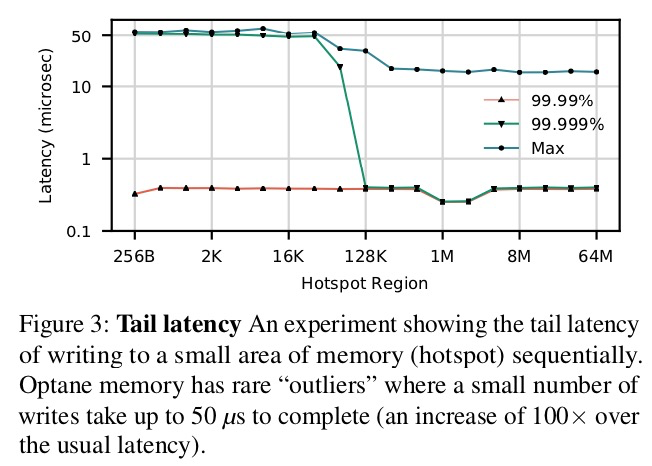
測試結果及說明
異常點的數量(尤其是超過50μs的異常值)隨著熱點大小的增加而減少,而DRAM不存在此種現象。這些峰值雖然出現頻率很低(佔訪問的0.006%),但是其延遲比普通的Optane訪問高2個數量級。 懷疑這是由於磨損均衡(wear-leveling)或溫度過高(thermal concerns)造成的,但不確定。
帶寬
帶寬一般影響整個系統的吞吐。本文測試了不同併發下的隨機/順序的讀/寫帶寬。
測試方法
圖4展示了不同線程數目以256B的粒度訪問相應介質的順序讀寫的帶寬。對於寫操作使用了ntstore和clwb兩種方式。圖從左到右記錄的依次是interleaved DRAM、non-interleaved Optane、interleaved Optane的帶寬。對於non-interleaved Optane,所有的訪問只訪問單個DIMM。
圖5展示的是訪問的粒度變化的情況下的隨機讀寫的帶寬。對於不同的測試,使用不同的線程數(圖中表示為 “讀線程數/ntstore線程數/store+clwb線程數”)以使得介質獲得最佳性能。
實驗結果說明
DRAM帶寬不僅比Optane高,而且性能可以根據線程數進行可預測的擴展,直至DRAM帶寬飽和(圖4左),並且與訪問大小無關(圖5左)。


Optane的結果截然不同。 首先,對於單個DIMM,最大讀帶寬是最大寫帶寬的2.9倍(圖5中,6.6 GB/s 和 2.3 GB/s),對於DRAM,讀寫性能差距較小(只有1.3倍)。其次,除了交錯DIMM的讀操作之外,Optane的其他操作的性能與線程數的關係都是非單調的(圖4,具體原因見後):對於非交錯(即單個DIMM,圖4中)的情況,性能會在一到四個線程之間達到峰值,然後逐漸下降;對於交錯的情況,store + clwb操作的峰值可以保持到十二個線程,然後開始下降。 第三,Optane 256 B以下的隨機讀寫的帶寬很低, 該拐點對應於XPLine的大小。
交錯(將訪問分佈在所有六個DIMM上)進一步增加了複雜性:圖4(右)和圖5(右)測試了六個交錯的NVDIMM的帶寬。 交錯將讀寫帶寬的峰值分別提高了5.8倍和5.6倍。 提升的倍數與DIMM的數量匹配。 該圖的最顯著特徵是當訪問的粒度是4 kB時,有性能下降。這種下降是由iMC中的競爭引起的,當每個線程隨機訪問的大小接近交錯大小時,下降將會達到最大值(具體原因見後)。
Optane DIMM的最佳實踐
為了構建基於Optane DIMM的系統並對其調優,基於實驗數據,本文將介質的規律提煉為以下四個原則:
1.避免小於256 B的隨機讀寫;
2.儘可能使用ntstore(non-temporal stores)進行大數據量的寫,以及控制CPU高速緩存的換出;
3.限制訪問Optane DIMM的併發線程數;
4.避免NUMA訪問(尤其對於是read-modify-write操作序列)。
下面詳細解釋這四個原則。
避免小數據量(小於256B)的隨機讀寫
對於隨機讀寫,圖5已說明了介質帶寬與訪問對象的大小關係。本節繼續探索小數據的隨機寫。
Optane的數據更新,在內部介質會進行read-modify-write操作。若更新的數據量小於內部操作的數據粒度(256B),會帶來寫放大,而使得更新效率低。
為了更好的描述下面的實驗現象,引入了EWR(Effective Write Ratio,由DIMM的硬件測量)的概念:其為iMC發出的字節數除以實際寫入3D-XPoint介質的字節數,即為寫放大的倒數。EWR小於1表示,Optane介質寫效率低。EWR也可以大於1,此時表示XP-Buffer做了寫合併(在內存模式中,因為DRAM的緩存作用,EWR也可以大於1)。
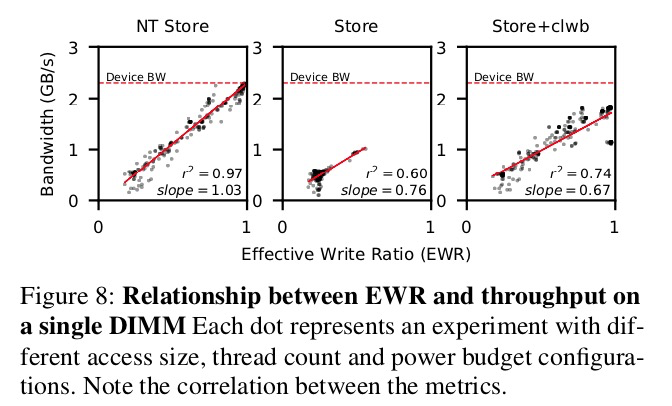
圖8展示了Optane DIMM的帶寬(三種store命令)與EWR的正相關的關係。一般而言,小數據量的存儲使得EWR小於1。 例如,當使用單個線程執行隨機的ntstore時,對於64字節的寫,EWR為0.25,對於256字節訪問,其EWR為0.98。
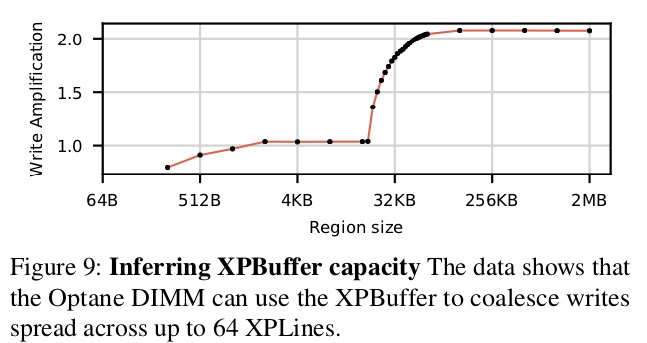
值得注意的是,雖然iMC僅以64B為單位訪問DIMM,但是XPBuffer可以將多個64B的寫進行緩存,並合併為256B的Optane內部寫,所以256字節更新是高效的。由上可知,如果Optane DIMM的訪問具有足夠好的局部性,同樣可以高效地進行小數據量的存儲。 為了得到“怎樣的局部性才足夠”的命題結論,我們設計了一個實驗來測量XPBuffer的大小。 首先,我們分配N個XPLine大小(256B)的連續區域。 在實驗中,進行循環的寫數據。首先,依次更新每個XPLine的前半部分(128 B), 然後再更新每個XPLine的後半部分。 我們測量每一輪後EWR的值。 圖9顯示: N 小於64(即16 kB的區域大小)時,EWR接近於1,其表明,後半部分的訪問命中了XPBuffer。 N 大於64時,寫放大進行了突變,其由XPBuffer miss急劇上升導致。這表明,XPBuffer的大小為16KB。進一步的實驗表明,讀操作也會佔用XPBuffer中的空間從而造成競爭關係。
總結:避免小數據量隨機寫,如果不可能避免,則將操作的數據集大小限制為每個Optane DIMM 16 KB。
使用ntstore進行大數據(大於256B)寫
一般通過下面操作進行數據寫入:store操作後,程序員可以通過clflush/clflushopt操作進行高速緩存evict或通過clwb操作進行寫回(write back),以將數據寫入至ADR域並最終寫至Optane DIMM;或者,通過ntstore指令繞過高速緩存直接寫入Optane DIMM。在進行完上述某種操作後,再進行sfence操作可確保先前的evict,write back和ntstore操作的數據變成持久的。寫數據時,採用上述何種操作對性能影響很大。
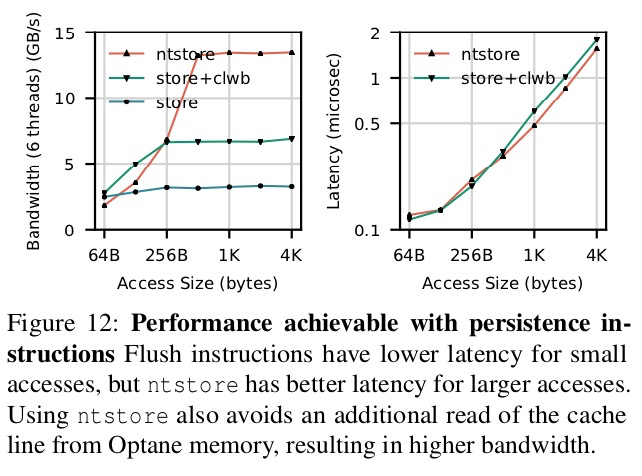
圖12 展示了順序寫操作的性能數據(圖左為帶寬,圖右為延遲)。測試中,使用三種寫方式:ntstore, store + clwb, 以及 store, 每次操作完後再進行一次 sfence操作。測試使用6個線程,因為該配置下所有的測試都能達到最好的性能。
對於寫超過64B的數據,每store 64B進行cache的flush操作(相比於不進行flush操作)獲得的帶寬會更大(圖12中的store+ clwb V.S. store)。我們認為,發生這種情況是因為,讓高速緩存自然地換出緩存行,會給到達Optane DIMM的數據流增加不確定性。 主動換出緩存可確保訪問保持順序性。 EWR的值驗證了該猜想:增加cache換出邏輯可以將EWR從0.26增加到0.98。
對於超過512 B的訪問,ntstore的延遲比store + clwb更低(圖12右)。對於超過256 B的訪問,ntstore操作的帶寬也最高(圖12左)。這是因為: clwb必須在執行實際存儲操作之前,其需將數據加載到CPU的本地高速緩存中,從而佔用了Optane DIMM的部分帶寬。 而ntstore通過繞過高速緩存,避免了這種不必要的讀取,從而獲得了更高的帶寬。
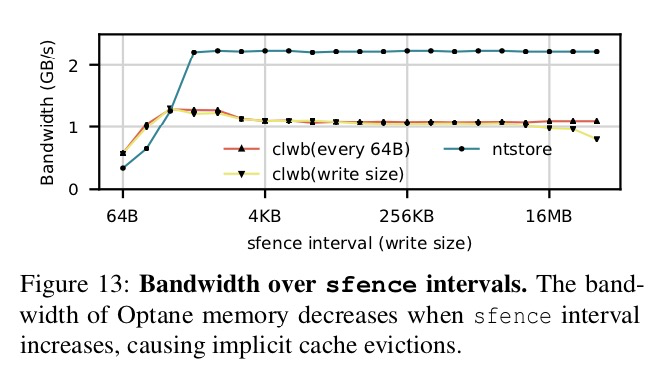
圖13顯示了sfence如何影響性能。 測試時,使一個線程在Optane-NI上進行大小不同的順序寫操作。 在每個高速緩存行store操作後(每64B)或在整個寫入store後(寫入大小),進行clwb操作。 每個寫操作後,再進行sfence操作,以確保整個寫操作是持久的(上述整個過程稱為一個“sfence間隔”)。 結果顯示當寫入大小為256 B時,帶寬達到峰值(clflushopt對中等大小的寫入進行了優化)。 在寫入中等大小的數據後,再進行刷新操作不會影響帶寬,但是當寫入的大小超過8 MB時,寫入後再進行刷新操作會導致性能下降,因為其導致了高速緩存容量的失效,從而使得EWR升高。
限制訪問Optane DIMM的併發線程數
系統應儘量減少同時訪問單個DIMM的併發線程數。Optane DIMM有限的存儲性能,以及iMC和Optane DIMM上有限的緩衝區共同限制了其同時處理多個線程請求的能力。 下面的兩種競爭說明了,應限制訪問Optane DIMM的併發線程數。
XPBuffer的競爭。對XPBuffer中緩存空間的爭用將導致逐出次數增加,觸發寫3D-XPoint介質,這將使EWR降低。 圖4(中)顯示了這種效果:線程數增加時,性能無法擴展。 例如,與具有0.98的EWR的單線程相比,8線程進行順序的ntstore操作,其EWR僅為0.62和帶寬也只有69%。
iMC中的競爭。圖15說明了,當多個核對單個DIMM操作時,iMC中有限的隊列容量如何影響性能。該實驗使用固定數量的線程(24個線程進行讀,6個線程進行ntstore)對6個交錯的Optane DIMM進行讀/寫操作。每個線程隨機訪問N個DIMM(線程間分佈均勻)。隨著N的增加,針對每個DIMM的寫入次數會增加,但是每個DIMM的帶寬會下降。可能的原因是XPBuffer的容量有限,但是EWR仍然非常接近1,因此性能問題肯定出在iMC中。
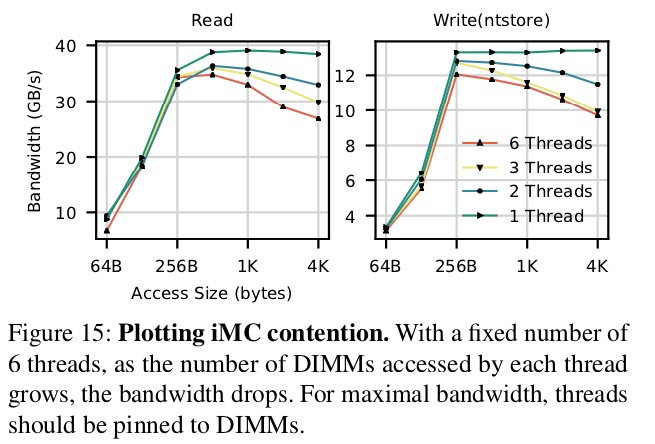
在我們測試平臺中,單個線程多達256B的數據可在WPQ緩衝區中排隊。我們的假設是,由於Optane DIMM的速度相比於讀/寫鏈路的其他部件很慢,因此WPQ中的數據消耗的很慢,而導致隊頭阻塞效應。N的增加會增加DIMM的爭用,所以會增加“某個處理器因等待其之前的store操作完成而被阻塞”的可能性。
圖5(右)展示了此現象的另一個示例:當對交錯的Optane DIMM進行隨機4 KB訪問時,Optane帶寬急劇下降。 Optane內存交錯類似於磁盤陣列中的RAID-0:塊大小為4 KB,條帶大小為24 KB(一個內存插槽上的6個DIMM的每個都佔用4 KB的連續塊)。圖5(右)中的工作負載的訪問分佈在這些交錯的DIMM上,導致特定DIMM的競爭激增。
隨著訪問大小的增加,線程飢餓發生的更加頻繁:在訪問的大小等於交錯的大小(4 kB)時,下降最為嚴重。對於大於交錯大小的訪問,每個核都開始將其訪問分佈在多個DIMM中,從而使得負載更加均勻。當寫入的數據大小為24 kB和48 kB,出現了性能的小峰值,其訪問在6個DIMM上完美分佈。
只要在DIMM上不均勻地分佈4 kB訪問,就會出現這種性能下現象。同時,這可能是實踐中的常見情況。例如,具有4 kB頁的頁緩存系統可能會表現不佳。
避免對遠程NUMA節點的混合或多線程訪問
Optane的NUMA效應遠大於DRAM,因此應更加努力地避免跨插槽的存儲器通信。對於讀寫混合且包含多線程訪問的情況,其成本特別高。在本地和遠程Optane內存之間,典型的讀延遲差異分別為1.79倍(順序)和1.20倍(隨機)。對於寫操作,遠程Optane的延遲是本地的2.53倍(ntstore)和1.68倍。而對於帶寬,遠程Optane可以在最佳線程數下實現本地讀/寫帶寬的59.2%和61.7%(本地讀取為16,遠程讀取為10,本地和遠程寫入為4)。
上面的性能下降的比例類似於遠程DRAM相較於本地DRAM。但是,當線程數增加或為讀寫混合負載時,Optane的帶寬將急劇下降。根據我們掃描測試的結果,在相同工作負載下,遠程Optane相比於本地的帶寬差距可能超過30倍,而DRAM的只有3.3倍(未通過圖展示具體數據)。
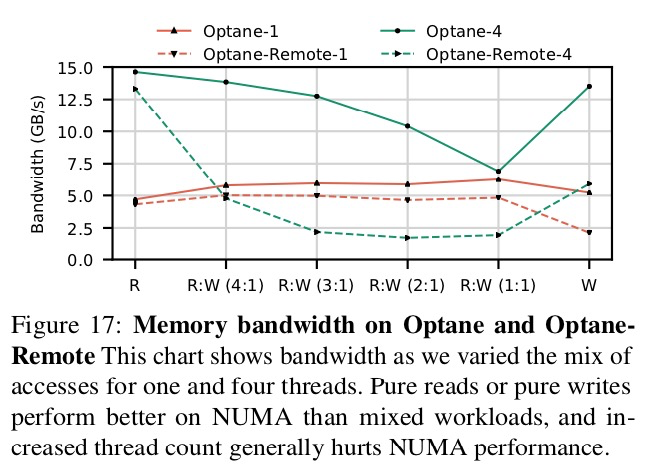
在圖17中,我們展示了調整讀寫比例會改變本地和遠程訪問Optane的帶寬。圖中展示了一個線程和四個線程的性能。針對所有測試的訪問模式,本地Optane內存帶寬隨著線程數增加(增加到4)而增加。對於本地和遠程訪問,單線程帶寬差距不大。而對於多線程訪問,隨著訪問壓力的提高,遠程訪問性能會更快下降,從而導致相對於本地訪問而言性能較低。