2020年4月20-24日,國際頂級學術會議WWW2020(The Web Conference 2020)在中國臺灣舉辦。創辦於1994年的WWW會議,是CCF-A類會議,每年有大批的學者、研究人員、技術專家、政策制定者等參與。
據悉,受COVID-19疫情影響,WWW2020將在線上舉行。此次會議共收到了1129篇論文投稿,錄用217篇,錄取率僅為19.2%。其中螞蟻金服有多篇論文入選,圍繞智能服務、認知計算等課題,向行業分享自身沉澱的金融智能應用成果。
事實上,螞蟻金服一直是國際頂級學術會議的“常客”。除了WWW,螞蟻金服也多次亮相NeurIPS、ICML、ICLR、AAAI、IJCAI、SIGIR、NAACL、VLDB、ACM T-IST、KDD、CVPR 等國際頂級學術會議,為學界帶來了諸多結合實際業務場景的創新研究和應用。對螞蟻金服而言,在頂級學術會議上發佈論文,一方面可推進人工智能最前沿研究的發展,將學術研究與應用相結合,另一方面可推進前沿技術從研究到實際應用中落地,為用戶帶來價值,為我們的生活服務帶來改變。
接下來,小螞蟻將為大家重點介紹本次螞蟻金服入選的論文成果。
Enhanced-RCNN: 一種高效的比較句子相似性的方法
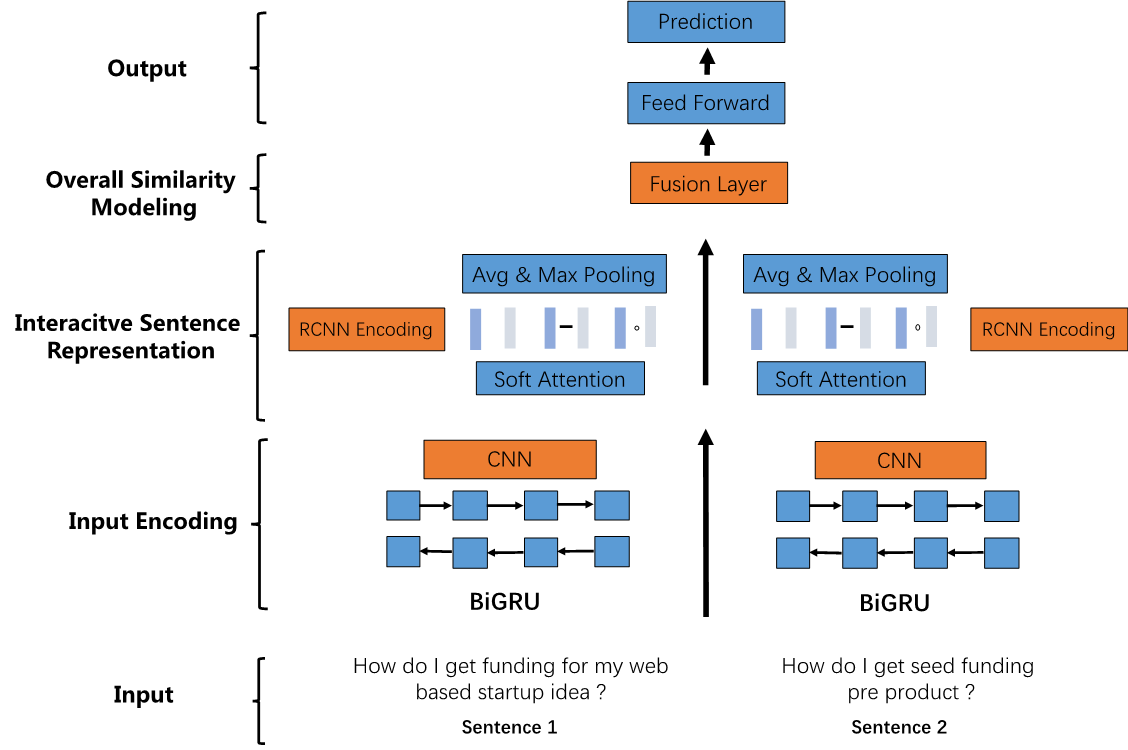
句子相似度計算,是貫穿智能客服離線、在線和運營等幾乎所有環節最核心的技術,同時也是自然語言理解中最核心的問題之一,廣泛應用於搜索、推薦、對話等領域。當前比較句子相似性的方法主要分為3種:表示型(Siamese Network Framework)、交互型(Matching-Aggregation Framework)和預訓練語言模型(Pre-trainedLanguage Model)。
在本篇論文中,我們提出了一種新型高效的比較句子相似性的方法 Enhanced-RCNN,來更好的捕捉待比較的兩個文本自身以及相互之間的信息。這是我們在經典文本匹配模型 ESIM的基礎上改進的模型,該模型在 Quora Question Pair 和 Ant Financial 兩個公開的文本匹配數據集上均取得了非常有競爭力的結果,並且和時下火熱的預訓練語言模型 BERT 相比,Enhanced-RCNN 也取得了相當的效果,其中參數量相比BERT-Base 也大幅減少,較為適合用於線上部署使用。同時,通過一些知識蒸餾的方法(KnowledgeDistillation),也可以將Enhanced-RCNN作為學生模型(Student Model)去學習BERT-Base,即老師模型,來進一步提升原有Enhanced-RCNN模型的預測準確率。
IntentDial: An Intent Graph based Multi-Turn Dialogue System with Reasoning Path Visualization(基於意圖圖譜的路徑推斷可視化多輪對話系統)
在一般智能問答系統中,常見的形式是:用戶提出問題,系統識別用戶意圖並給出回答或者引導解決。其中正確理解識別用戶問題的意圖十分重要,正常情況下我們可將這一識別過程當作是一個分類任務處理,用深度神經網絡對數據進行訓練預測。其中在我們構建意圖庫的時候,我們將收集用戶最真實的意圖並對應提供解決方案,對於用戶描述清晰完備的情況下,我們可在意圖庫中找到一個對應的意圖,而事實上在一些較複雜的問題上,部分用戶在表達意圖時,能一次性將所有信息表訴完備是較困難的,此時則需要和用戶進一步進行多輪QA從而定位用戶意圖。
本論文中,螞蟻金服工程師創新性在智能問答中結合圖譜結構和強化學習進行建模,(1)通過引入圖譜結構,可將問答相關的領域先驗知識引入模型訓練,加速強化學習模型收斂,同時模型結果為當前上下文獲得的圖譜路徑推斷,可解釋性高,一方面可用於指導分析模型訓練過程中出現的問題,另一方面路徑推斷中的要素節點可作為實體識別結果用於對話其他模塊。(2)通過採取該多輪對話方式,可以有效同時解決對話過程中用戶描述清晰和模糊的情況,擴展性高。
A Generic Solver Combining Unsupervised Learning and Representation Learning for Breaking Text-Based Captchas(基於自監督表徵學習的驗證碼識別方法)
隨著互聯網的高速發展,越來越多的自動化破解程序給網絡安全帶來不小的挑戰。驗證碼以其簡單高效的特徵,目前已經成為了互聯網安全的基本保障程序。雖然當前已經有許多可供選擇的驗證碼方案,但由於用戶偏好和易於設計的特性,基於文本的驗證碼類型仍然是維護互聯網安全和防止惡意攻擊的最流行的安全機制之一。而文本驗證碼的安全特徵對驗證碼安全性方面起著十分重要的作用,因此作為學術研究去自動識別破解文本驗證碼,可以發現現有驗證碼所存在的漏洞,有利於網站開發人員設計出更加安全的驗證碼體系,保障網絡安全。
在過去的十多年裡,人們已經提出了多種驗證碼破解方法,其中許多方法需要針對不同的驗證碼類型使用獨特的濾波和分割方法來實現字符識別,這類方法的泛化性較差,且需要過多的人工參與。隨著更復雜的安全特性被引入到文本驗證碼中,這些方法也不再適用。而一些基於深度學習的驗證碼識別算法在準確性上取得了顯著的提高,但這些方法的主要問題是需要大規模的帶有標籤的訓練樣本參與訓練,而這通常需要耗費大量的人工成本。
大規模帶有標籤驗證碼圖像難以收集,但是無標籤的圖像樣本卻是很容易大量採集得到。在深度學習領域中,無監督學習和表徵學習都可以減少對於標籤樣本的依賴,充分利用無標籤數據樣本去學習數據表徵,提升深度學習方法的性能。我們通過設計了一個結合無監督學習和表徵學習的驗證碼識別方案,在不依賴人工參與和大規模帶標籤訓練樣本的前提下,實現文本驗證碼的自動識別。經過實驗測試發現,我們的方法僅僅使用500張帶有標籤的訓練樣本就可以破解大多數主流網站的驗證碼,這也說明了目前文本驗證碼的部分安全特徵很容易破解。通過我們所提出的方法可以發現現有驗證碼的漏洞,並且分析不同安全特徵的有效性,從而開發出更安全可靠的驗證碼。
Solving Billion-Scale Knapsack Problems(求解億級變量揹包問題)
揹包問題 (knapsack problem) 是經典的整數規劃問題,求解如何從多個物品中選取一個子集放入揹包,在容量限制下最大化子集的效用。互聯網場景下很多問題可以看成超大規模的揹包問題或者它的變種問題,比如紅包營銷,用戶流量分配等,都有某種總資源的限制,需要在大量的用戶粒度的決策中選取一個子集來最大化業務收益。由於揹包問題是 NP-hard,求解複雜度高,所以精確算法無法做較大規模的求解。而近似類算法對問題的形式化有具體要求,實際業務的需求一般不會嚴格符合揹包問題的定義,所以需要求解算法有更強的泛化性和通用性。因此,如何在高精度下求解超大規模揹包問題及其變種問題仍然是一個挑戰。
螞蟻金服的工作是最早做到對億級變量的揹包問題求解工作之一。我們的問題形式化涵蓋了互聯網海量數據場景下的泛化揹包問題。它的“物品”有兩個維度:用戶和選項,即“為每位用戶選擇哪些選項”。它的“揹包容量”擴展到了多個維度,即每個用戶的每個選項可以消耗多個不同的資源。同時我們還支持對每個用戶的選項做任意整數規劃的約束。
用於圖像檢索的等距離等分佈三元組損失函數
圖像檢索由於類內差異大、類間相似性高,非常具有挑戰性。深度度量學習在該任務上取得了一定的效果。然而,最為經典的深度度量學習損失函數——三元組損失,存在一定的問題。首先,三元組損失約束了匹配對和不匹配對間的距離差異至少為一個固定間隔值,由於沒有直接約束匹配對或者不匹配對的距離,使得局部範圍內三元組滿足間隔約束時不能保證全局範圍內也滿足。其次,改進的三元組損失進一步約束所有匹配對距離小於某個固定值以及所有不匹配對的距離大於某個固定值,這種固定值約束沒有考慮到圖像不同類別的獨特性,容易造成特徵空間扭曲。因此,為了在全局範圍內進一步拉近匹配對的距離和推遠不匹配對的距離,在三元組損失的間隔約束基礎上,我們針對匹配對和不匹配對分別進行了相對距離約束。
在本篇論文中,螞蟻金服工程師提出了EET方法,通過等距離約束進一步拉近匹配對的距離,等分佈約束進一步推遠不匹配對的距離,最終實驗結果亦表明該方法可以用在多個檢索任務上。