若需文中圖片,請關注公眾號:404P 獲取。
前言
在微服務架構體系下,服務註冊中心致力於解決微服務之間服務發現的問題。在服務數量不多的情況下,服務註冊中心集群中每臺機器都保存著全量的服務數據,但隨著螞蟻金服海量服務的出現,單機已無法存儲所有的服務數據,數據分片成為了必然的選擇。數據分片之後,每臺機器只保存一部分服務數據,節點上下線就容易造成數據波動,很容易影響應用的正常運行。本文通過介紹 SOFARegistry 的分片算法和相關的核心源碼來展示螞蟻金服是如何解決上述問題的。
服務註冊中心簡介
在微服務架構下,一個互聯網應用的服務端背後往往存在大量服務間的相互調用。例如服務 A 在鏈路上依賴於服務 B,那麼在業務發生時,服務 A 需要知道服務 B 的地址,才能完成服務調用。而分佈式架構下,每個服務往往都是集群部署的,集群中的機器也是經常變化的,所以服務 B 的地址不是固定不變的。如果要保證業務的可靠性,服務調用者則需要感知被調用服務的地址變化。
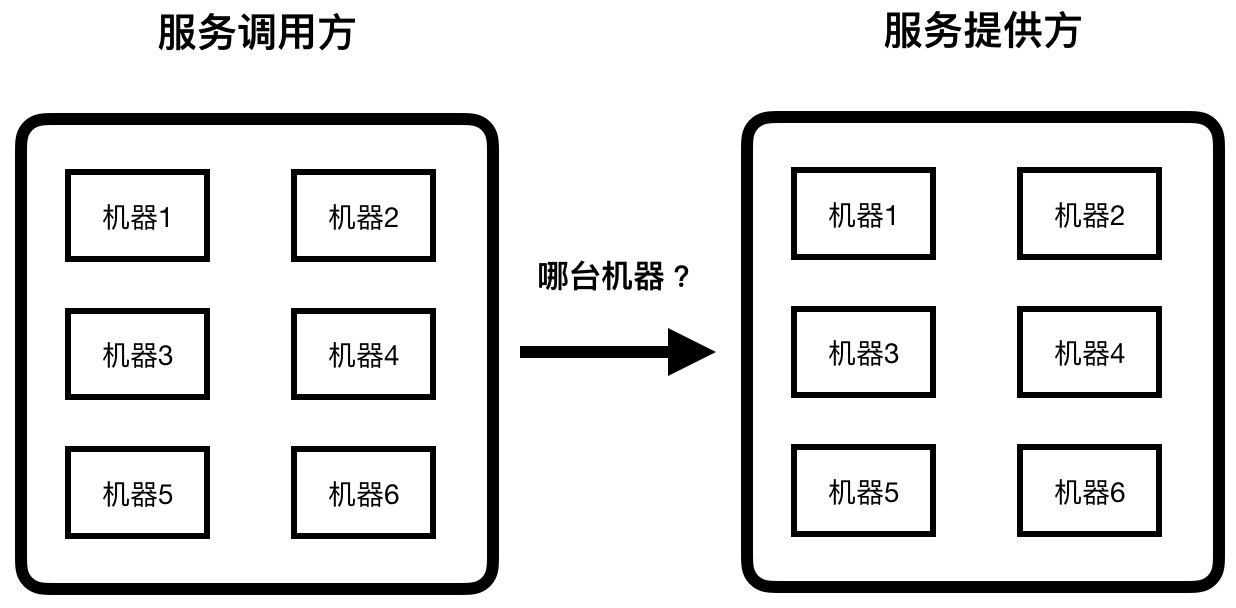
圖1 微服務架構下的服務尋址
既然成千上萬的服務調用者都要感知這樣的變化,那這種感知能力便下沉成為微服務中一種固定的架構模式:服務註冊中心。
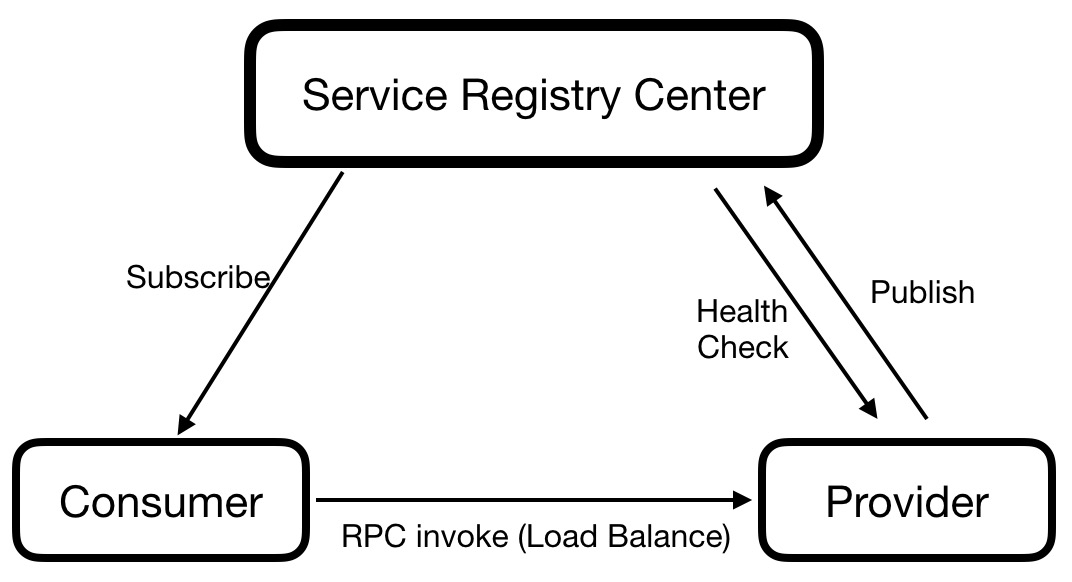
圖2 服務註冊中心
服務註冊中心裡,有服務提供者和服務消費者兩種重要的角色,服務調用方是消費者,服務被調方是提供者。對於同一臺機器,往往兼具兩者角色,既被其它服務調用,也調用其它服務。服務提供者將自身提供的服務信息發佈到服務註冊中心,服務消費者通過訂閱的方式感知所依賴服務的信息是否發生變化。
SOFARegistry 總體架構
SOFARegistry 的架構中包括4種角色:Client、Session、Data、Meta,如圖3所示:
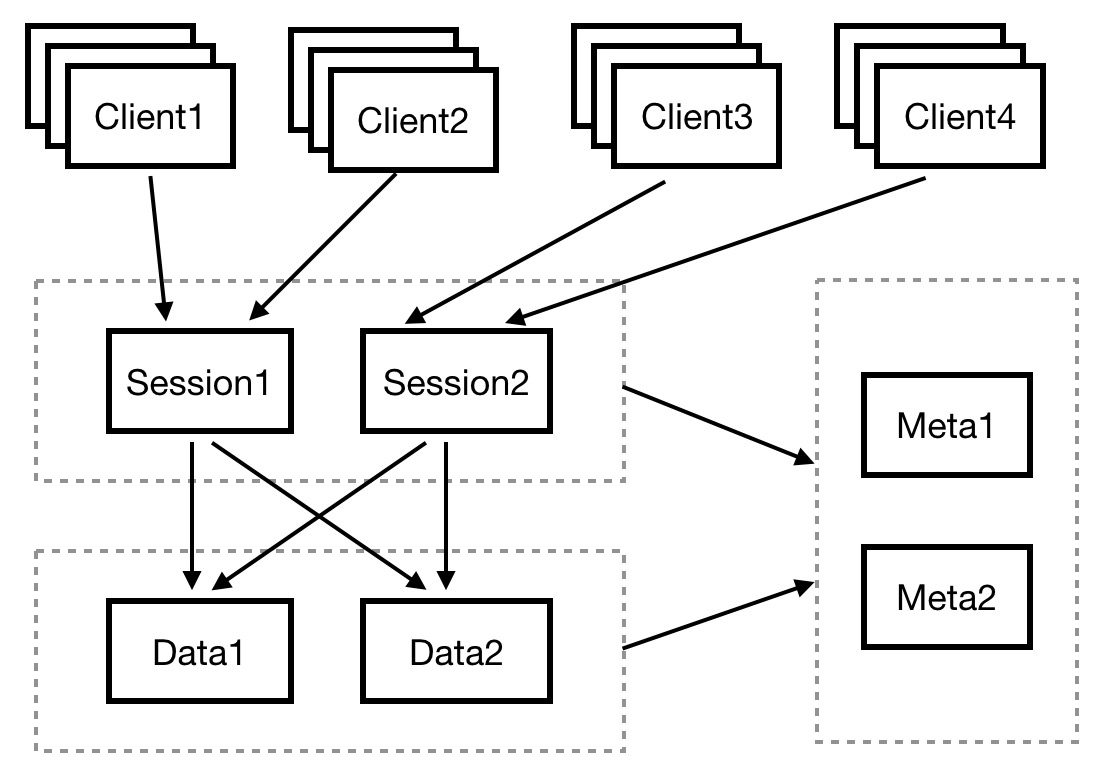
圖3 SOFARegistry 總體架構
- Client 層
應用服務器集群。Client 層是應用層,每個應用系統通過依賴註冊中心相關的客戶端 jar 包,通過編程方式來使用服務註冊中心的服務發佈和服務訂閱能力。
- Session 層
Session 服務器集群。顧名思義,Session 層是會話層,通過長連接和 Client 層的應用服務器保持通訊,負責接收 Client 的服務發佈和服務訂閱請求。該層只在內存中保存各個服務的發佈訂閱關係,對於具體的服務信息,只在 Client 層和 Data 層之間透傳轉發。Session 層是無狀態的,可以隨著 Client 層應用規模的增長而擴容。
- Data 層
數據服務器集群。Data 層通過分片存儲的方式保存著所用應用的服務註冊數據。數據按照 dataInfoId(每一份服務數據的唯一標識)進行一致性 Hash 分片,多副本備份,保證數據的高可用。下文的重點也在於隨著數據規模的增長,Data 層如何在不影響業務的前提下實現平滑的擴縮容。
- Meta 層
元數據服務器集群。這個集群管轄的範圍是 Session 服務器集群和 Data 服務器集群的服務器信息,其角色就相當於 SOFARegistry 架構內部的服務註冊中心,只不過 SOFARegistry 作為服務註冊中心是服務於廣大應用服務層,而 Meta 集群是服務於 SOFARegistry 內部的 Session 集群和 Data 集群,Meta 層能夠感知到 Session 節點和 Data 節點的變化,並通知集群的其它節點。
SOFARegistry 如何突破單機存儲瓶頸
在螞蟻金服的業務規模下,單臺服務器已經無法存儲所有的服務註冊數據,SOFARegistry 採用了數據分片的方案,每臺機器只保存一部分數據,同時每臺機器有多副本備份,這樣理論上可以無限擴容。根據不同的數據路由方式,常見的數據分片主要分為兩大類:範圍分片和 Hash(哈希)分片。
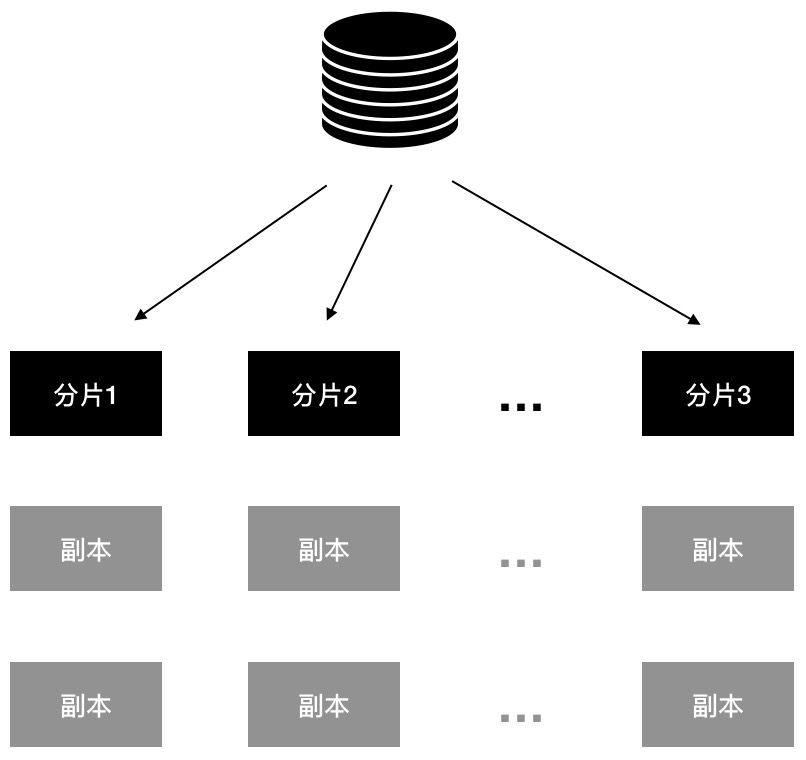
圖4 數據分片
範圍分片
每一個數據分片負責存儲某一鍵值區間範圍的值。例如按照時間段進行分區,每個小時的 Key 放在對應的節點上。區間範圍分片的優勢在於數據分片具有連續性,可以實現區間範圍查詢,但是缺點在於沒有對數據進行隨機打散,容易存在熱點數據問題。
Hash (哈希)分片
Hash 分片則是通過特定的 Hash 函數將數據隨機均勻地分散在各個節點中,不支持範圍查詢,只支持點查詢,即根據某個數據的 Key 獲取數據的內容。業界大多 KV(Key-Value)存儲系統都支持這種方式,包括 cassandra、dynamo、membase 等。業界常見的 Hash 分片算法有哈希取模法、一致性哈希法和虛擬桶法。
哈希取模
哈希取模的 Hash 函數如下:
H(Key) = hash(key) mod K;
這是一個 key-machine 的函數。key 是數據主鍵,K 是物理機數量,通過數據的 key 能夠直接路由到物理機器。當 K 發生變化時,會影響全體數據分佈。所有節點上的數據會被重新分佈,這個過程是難以在系統無感知的情況下平滑完成的。
圖5 哈希取模
一致性哈希
分佈式哈希表(DHT)是 P2P 網絡和分佈式存儲中一項常見的技術,是哈希表的分佈式擴展,即在每臺機器存儲部分數據的前提下,如何通過哈希的方式來對數據進行讀寫路由。其核心在於每個節點不僅只保存一部分數據,而且也只維護一部分路由,從而實現 P2P 網絡節點去中心化的分佈式尋址和分佈式存儲。DHT 是一個技術概念,其中業界最常見的一種實現方式就是一致性哈希的 Chord 算法實現。
- 哈希空間
一致性哈希中的哈希空間是一個數據和節點共用的一個邏輯環形空間,數據和機器通過各自的 Hash 算法得出各自在哈希空間的位置。
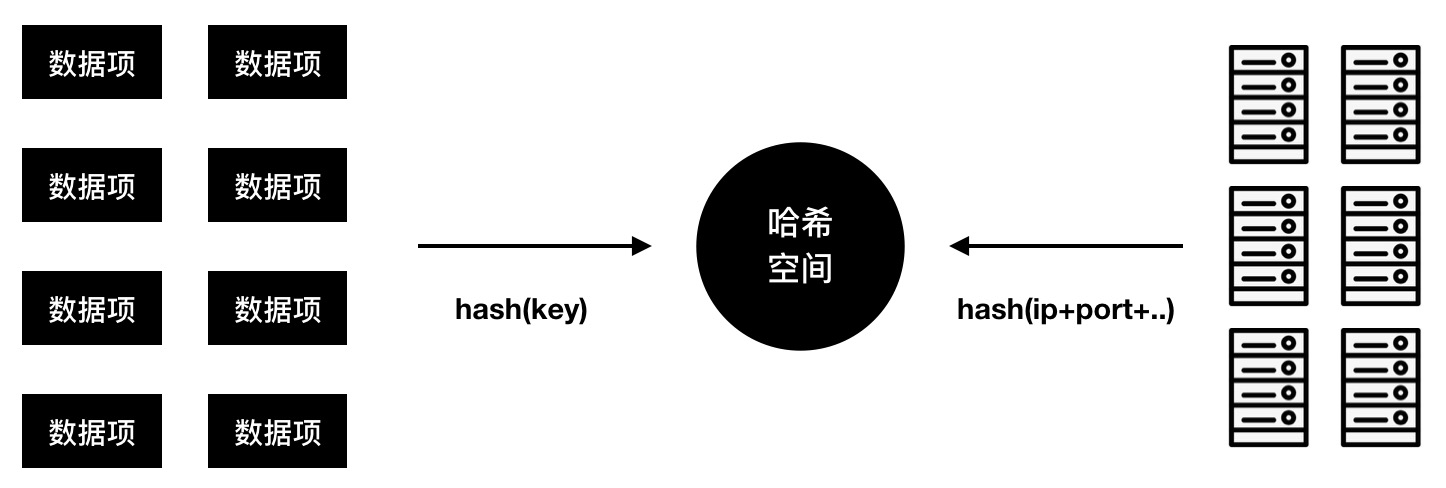
圖6 數據項和數據節點共用哈希空間
圖7是一個二進制長度為5的哈希空間,該空間可以表達的數值範圍是0~31(2^5),是一個首尾相接的環狀序列。環上的大圈表示不同的機器節點(一般是虛擬節點),用 Ni 來表示,i 代表著節點在哈希空間的位置。例如,某個節點根據 IP 地址和端口號進行哈希計算後得出的值是7,那麼 N7 則代表則該節點在哈希空間中的位置。由於每個物理機的配置不一樣,通常配置高的物理節點會虛擬成環上的多個節點。
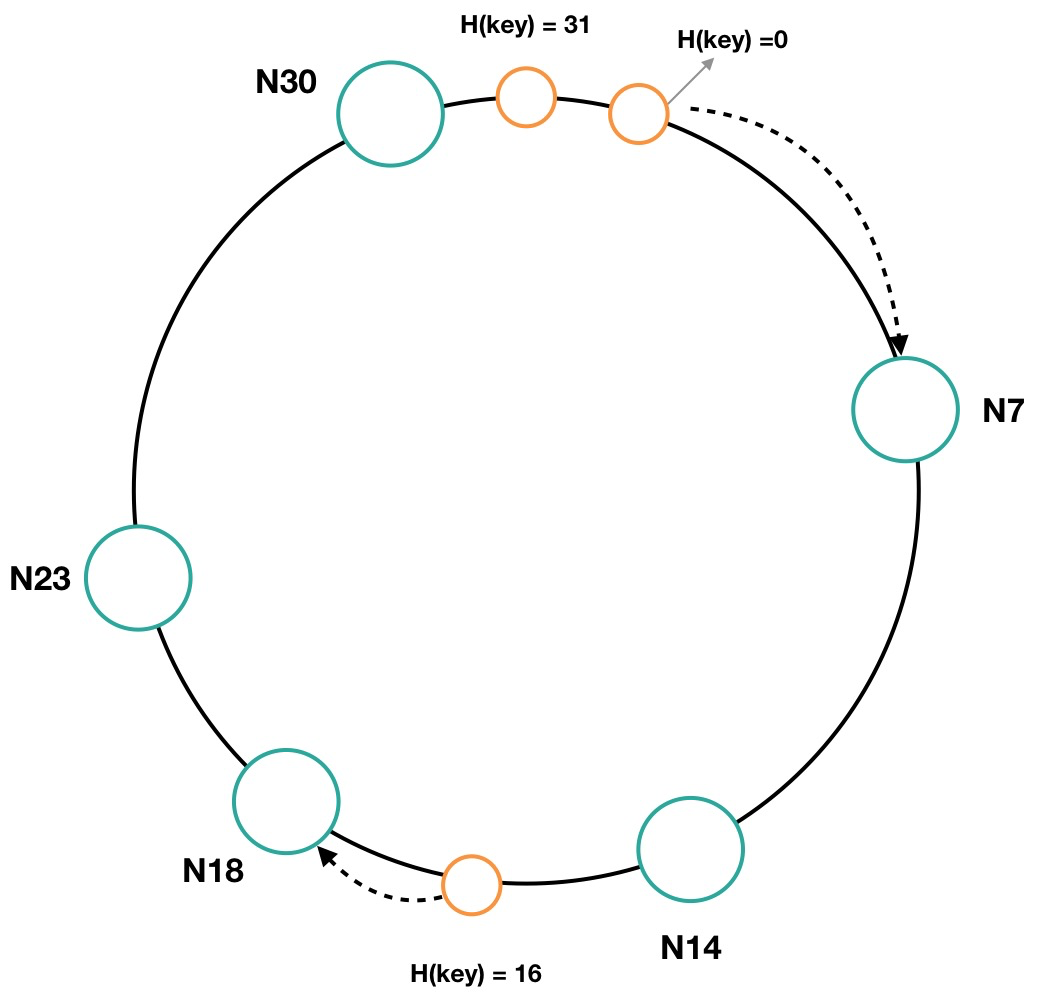
圖7 長度為5的哈希空間
環上的節點把哈希空間分成多個區間,每個節點負責存儲其中一個區間的數據。例如 N14 節點負責存儲 Hash 值為8~14範圍內的數據,N7 節點負責存儲 Hash 值為31、0~7區間的數據。環上的小圈表示實際要存儲的一項數據,當一項數據通過 Hash 計算出其在哈希環中的位置後,會在環中順時針找到離其最近的節點,該項數據將會保存在該節點上。例如,一項數據通過 Hash 計算出值為16,那麼應該存在 N18 節點上。通過上述方式,就可以將數據分佈式存儲在集群的不同節點,實現數據分片的功能。
- 節點下線
如圖8所示,節點 N18 出現故障被移除了,那麼之前 N18 節點負責的 Hash 環區間,則被順時針移到 N23 節點,N23 節點存儲的區間由19~23擴展為15~23。N18 節點下線後,Hash 值為16的數據項將會保存在 N23 節點上。
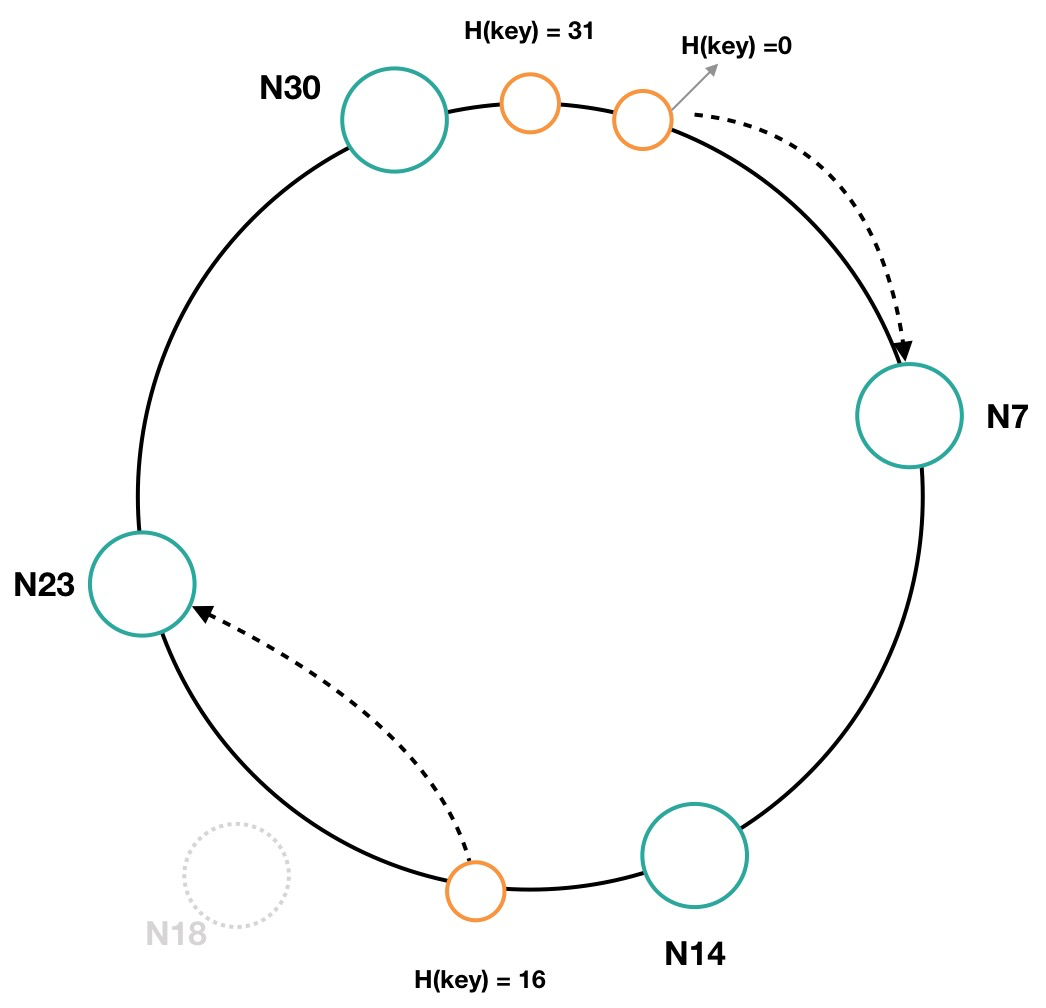
圖8 一致性哈希環中節點下線
- 節點上線
如圖9所示,如果集群中上線一個新節點,其 IP 和端口進行 Hash 後的值為17,那麼其節點名為 N17。那麼 N17 節點所負責的哈希環區間為15~17,N23 節點負責的哈希區間縮小為18~23。N17 節點上線後,Hash 值為16的數據項將會保存在 N17 節點上。
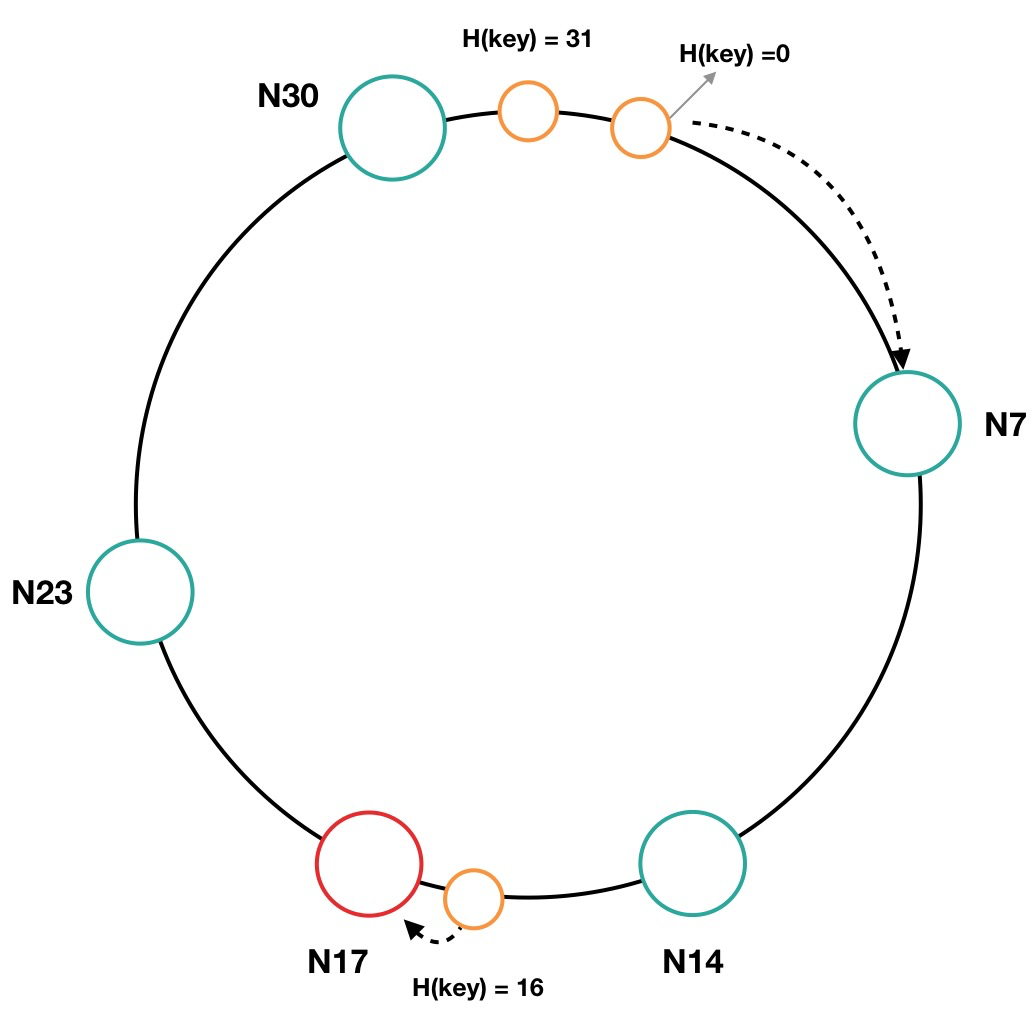
圖9 一致性哈希環中節點上線
當節點動態變化時,一致性哈希仍能夠保持數據的均衡性,同時也避免了全局數據的重新哈希和數據同步。但是,發生變化的兩個相鄰節點所負責的數據分佈範圍依舊是會發生變化的,這對數據同步帶來了不便。數據同步一般是通過操作日誌來實現的,而一致性哈希算法的操作日誌往往和數據分佈相關聯,在數據分佈範圍不穩定的情況下,操作日誌的位置也會隨著機器動態上下線而發生變化,在這種場景下難以實現數據的精準同步。例如,上圖中 Hash 環有0~31個取值,假如日誌文件按照這種哈希值來命名的話,那麼 data-16.log 這個文件日誌最初是在 N18 節點,N18 節點下線後,N23 節點也有 data-16.log 了,N17 節點上線後,N17 節點也有 data-16.log 了。所以,需要有一種機制能夠保證操作日誌的位置不會因為節點動態變化而受到影響。
虛擬桶預分片
虛擬桶則是將 key-node 映射進行了分解,在數據項和節點之間引入了虛擬桶這一層。如圖所示,數據路由分為兩步,先通過 key 做 Hash 運算計算出數據項應所對應的 slot,然後再通過 slot 和節點之間的映射關係得出該數據項應該存在哪個節點上。其中 slot 數量是固定的,key - slot 之間的哈希映射關係不會因為節點的動態變化而發生改變,數據的操作日誌也和slot相對應,從而保證了數據同步的可行性。

圖10 虛擬桶預分片機制
路由表中存儲著所有節點和所有 slot 之間的映射關係,並儘量確保 slot 和節點之間的映射是均衡的。這樣,在節點動態變化的時候,只需要修改路由表中 slot 和動態節點之間的關係即可,既保證了彈性擴縮容,也降低了數據同步的難度。
SOFARegistry 的分片選擇
通過上述一致性哈希分片和虛擬桶分片的對比,我們可以總結一下它們之間的差異性:一致性哈希比較適合分佈式緩存類的場景,這種場景重在解決數據均衡分佈、避免數據熱點和緩存加速的問題,不保證數據的高可靠,例如 Memcached;而虛擬桶則比較適合通過數據多副本來保證數據高可靠的場景,例如 Tair、Cassandra。
顯然,SOFARegistry 比較適合採用虛擬桶的方式,因為服務註冊中心對於數據具有高可靠性要求。但由於歷史原因,SOFARegistry 最早選擇了一致性哈希分片,所以同樣遇到了數據分佈不固定帶來的數據同步難題。我們如何解決的呢?我們通過在 DataServer 內存中以 dataInfoId 的粒度記錄操作日誌,並且在 DataServer 之間也是以 dataInfoId 的粒度去做數據同步(一個服務就由一個 dataInfoId 唯標識)。其實這種日誌記錄的思想和虛擬桶是一致的,只是每個 datainfoId 就相當於一個 slot 了,這是一種因歷史原因而採取的妥協方案。在服務註冊中心的場景下,datainfoId 往往對應著一個發佈的服務,所以總量還是比較有限的,以螞蟻金服目前的規模,每臺 DataServer 中承載的 dataInfoId 數量也僅在數萬的級別,勉強實現了 dataInfoId 作為 slot 的數據多副本同步方案。
DataServer 擴縮容相關源碼
注:本次源碼解讀基於 registry-server-data 的5.3.0版本。
DataServer 的核心啟動類是 DataServerBootstrap,該類主要包含了三類組件:節點間的 bolt 通信組件、JVM 內部的事件通信組件、定時器組件。
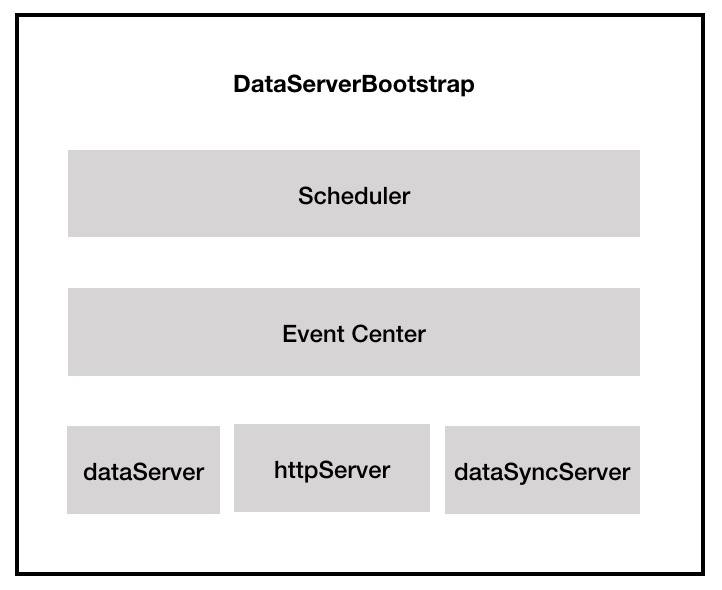
圖11 DataServerBootstrap 的核心組件
- 外部節點通信組件:在該類中有3個 Server 通信對象,用於和其它外部節點進行通信。其中 httpServer 主要提供一系列 http 接口,用於 dashboard 管理、數據查詢等;dataSyncServer 主要是處理一些數據同步相關的服務;dataServer 則負責數據相關服務;從其註冊的 handler 來看,dataSyncServer 和 dataSever 的職責有部分重疊;
- JVM 內部通信組件:DataServer 內部邏輯主要是通過事件驅動機制來實現的,圖12列舉了部分事件在事件中心的交互流程,從圖中可以看到,一個事件往往會有多個投遞源,非常適合用 EventCenter 來解耦事件投遞和事件處理之間的邏輯;
- 定時器組件:例如定時檢測節點信息、定時檢測數據版本信息;
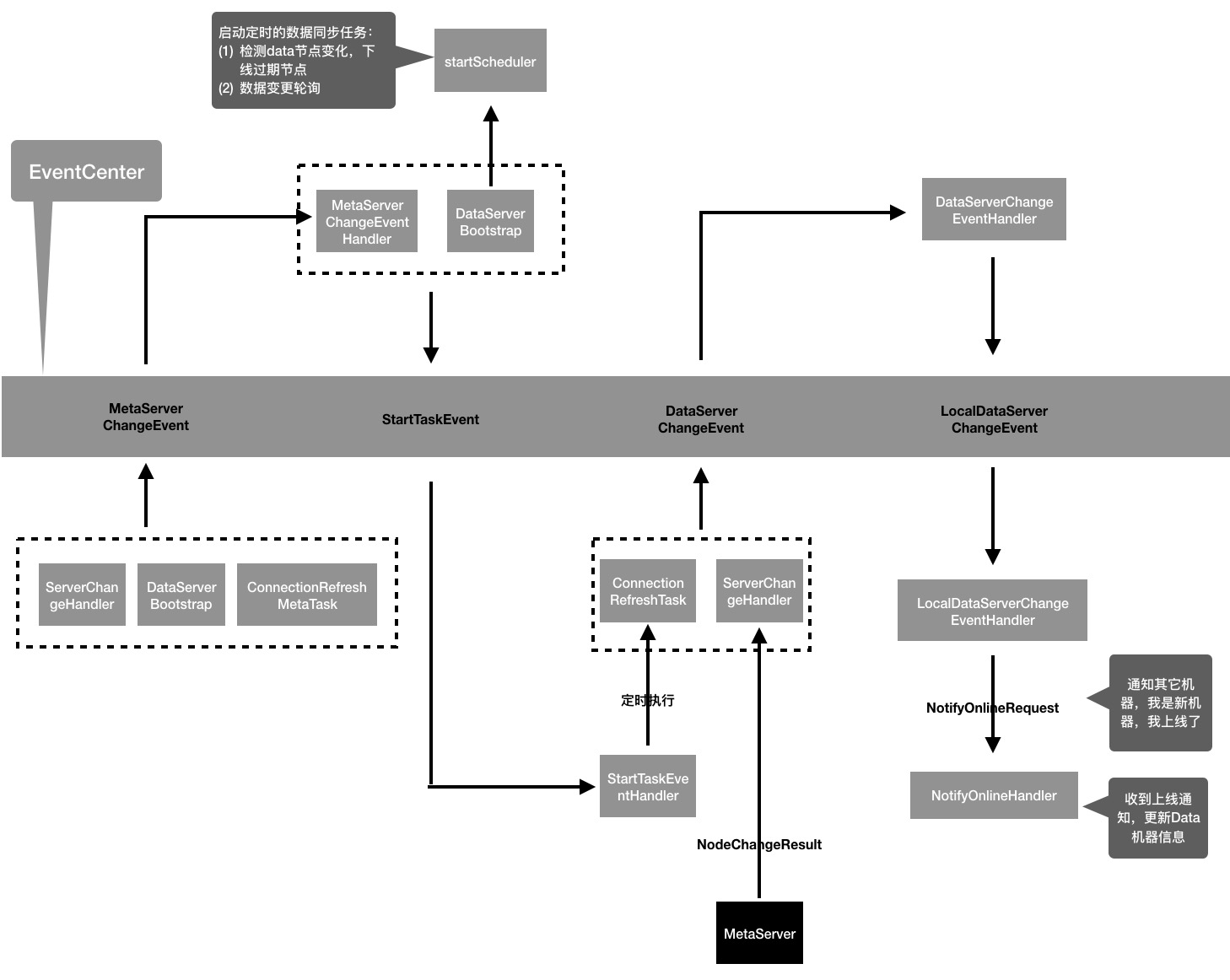
圖12 DataServer 中的核心事件流轉
DataServer 節點擴容
假設隨著業務規模的增長,Data 集群需要擴容新的 Data 節點。如圖13,Data4 是新增的 Data 節點,當新節點 Data4 啟動時,Data4 處於初始化狀態,在該狀態下,對於 Data4 的數據寫操作被禁止,數據讀操作會轉發到其它節點,同時,存量節點中屬於新節點的數據將會被新節點和其副本節點拉取過來。
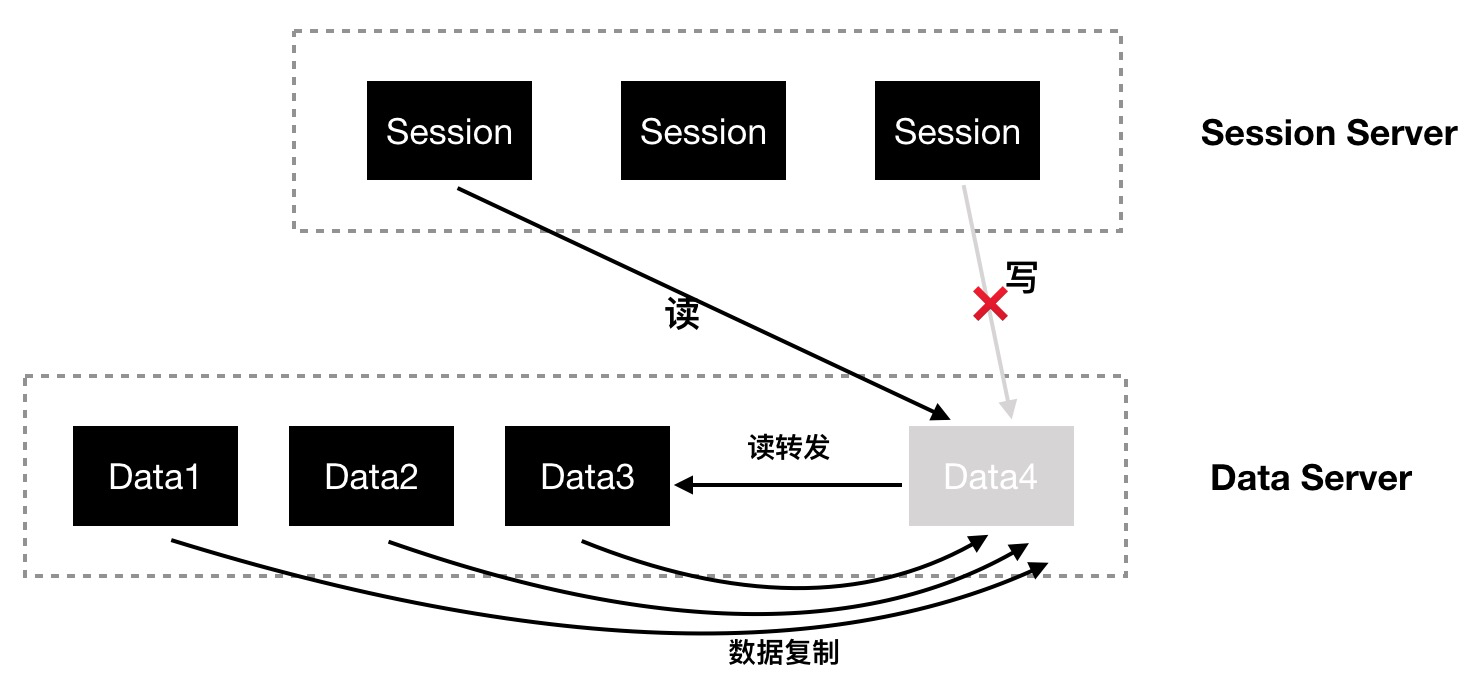
圖13 DataServer 節點擴容場景
- 轉發讀操作
在數據未同步完成之前,所有對新節點的讀數據操作,將轉發到擁有該數據分片的數據節點。
查詢服務數據處理器 GetDataHandler:
public Object doHandle(Channel channel, GetDataRequest request) { String dataInfoId = request.getDataInfoId(); if (forwardService.needForward()) { // ... 如果不是WORKING狀態,則需要轉發讀操作 return forwardService.forwardRequest(dataInfoId, request); } }
轉發服務 ForwardServiceImpl:
public Object forwardRequest(String dataInfoId, Object request) throws RemotingException { // 1. get store nodes List<DataServerNode> dataServerNodes = DataServerNodeFactory .computeDataServerNodes(dataServerConfig.getLocalDataCenter(), dataInfoId, dataServerConfig.getStoreNodes());