概述
目前RDS(X-Engine)主打的優勢是低成本,高性價比,在MySQL生態下幫助解決用戶的成本問題。使用X-Engine的用戶一般數據量都較大,比如已經在集團大規模部署的交易歷史庫,釘釘歷史庫以及圖片空間庫等。數據既然存儲到了X-Engine,當然也少不了計算需求,因此如何高效執行查詢是未來X-Engine一定要解決的問題。目前,在MySQL體系下,每個SQL都至多隻能使用一個CPU,由一個線程完成串行掃描行並進行計算。X-Engine引擎需要提供並行掃描能力,這樣讓一個SQL具備利用多核掃描數據能力,整體縮短SQL執行的響應時間。
串行掃描
在具體介紹X-Engine並行掃描之前,先簡單介紹下目前X-Engine串行掃描的邏輯。大家知道數據庫引擎的核心區別在於數據結構,比如InnoDB引擎採用B+Tree結構,而X-Engine則採用LSM-Tree結構,兩者各有特點,B+Tree結構對讀更友好,而LSM-Tree則對寫則更友好。
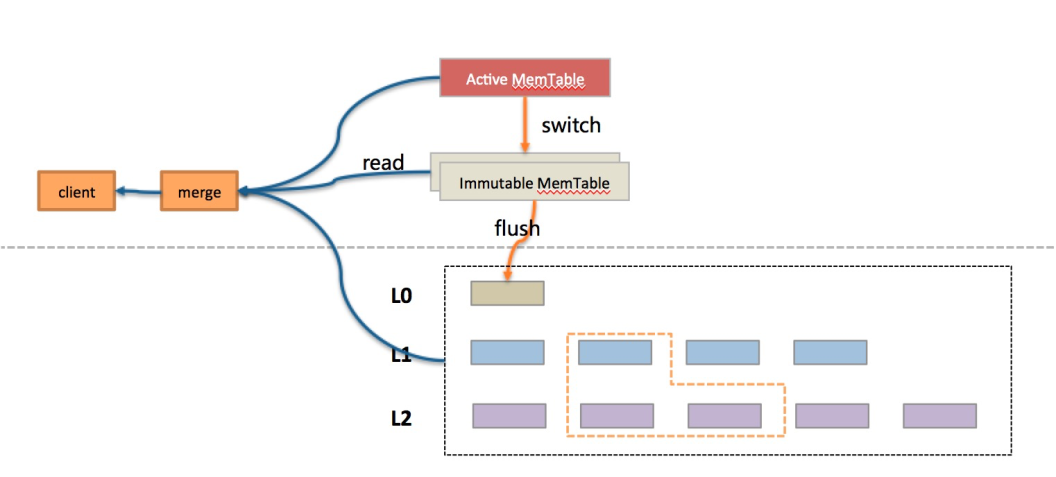
對於一條SQL,在優化器選擇好了執行計劃以後,掃描數據的方式就確定了,或是走索引覆蓋掃描,或是走全表掃描,或者走range掃描等,這點通過執行計劃就可以直觀的看到。無論哪種方式,本質來說就是兩種,一種是點查詢,一種是範圍查詢,查詢的數據要麼來自索引,要麼來自主表。X-Engine的存儲架構是一個類LSM-tree的4層結構,包括memtable,L0,L1和L2,每一個層數據都可能有重疊,因此查詢時(這裡主要討論範圍查詢),需要將多層數據進行歸併,並根據快照來確定用戶可見的記錄。
如下圖所示,從存儲的層次上來看,X-Engine存儲架構採用分層思想,包括memtable,L0,L1和L2總共4層,結合分層存儲和冷熱分離等技術,在存儲成本和性能達到一個平衡。數據天然在LSM結構上存在多版本,這種結構對寫非常友好,直接追加寫到內存即可;而對讀來說,則需要合併所有層的數據。
並行掃描
X-Engine並行掃描要做的就是,將本來一個大查詢掃描,拆分成若干小查詢掃描,各個查詢掃描的數據不存在重疊,所有小查詢掃描的並集就是單個大查詢需要掃描的記錄。並行掃描的依據是,上層計算對於掃描記錄的先後順序沒有要求,那麼就可以並行對掃描的記錄做處理,比如count(*)操作,每掃描一條記錄,就對計數累加,多個併發線程可以同時進行。其它類型的聚集操作比如sum,avg等,實際上都符合這個特徵,對掃描記錄的先後順序沒有要求,最終歸結到一點都是需要引擎層支持並行掃描。
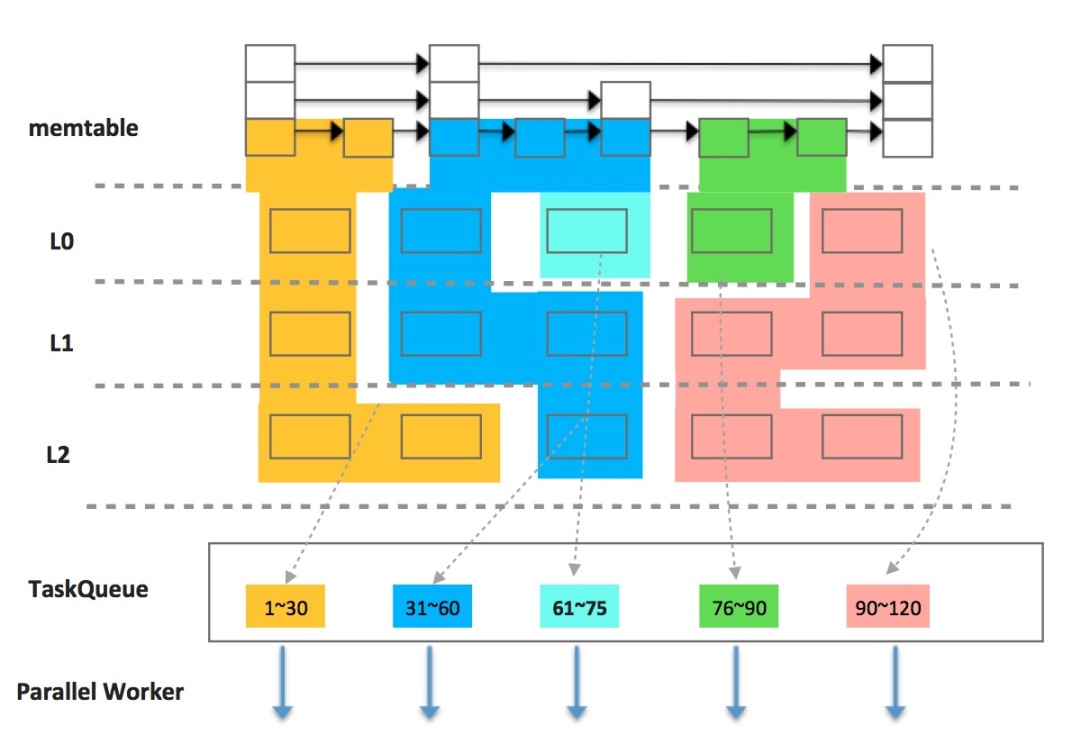
如下圖所示,X-Engine整個包括4層,其中內存數據用memtable表示,磁盤數據用L0,L1和L2表示,memtable這一層是一個簡單的skiplist,每個方框表示一條記錄;L0,L1和L2上的每個方框表示一個extent,extent是X-Engine的概念,表示一個大的有序數據塊,extent內部由若干個小的block組成,block裡面的記錄按key有序排列。
根據分區算法得到若干分區後,可以劃分分區,不同顏色代表不同的分區,每個分區作為一個並行task投入到隊列,worker線程從TaskQueue中獲取task掃描,各個worker不需要協同,只需要互斥的訪問TaskQueue即可。每個掃描任務與串行執行時並無二樣,也是需要合併多路數據,區別在於查詢的範圍變小了。
分區算法
將查詢按照邏輯key大小劃分成若干個分區,各個分區不存在交疊,用戶輸入一個range[start, end),轉換後輸出若干[start1,end1),[start2, end2)...[startn,endn),分區數目與線程數相關,將分區數設定在線程數的倍數(比如2倍,具體倍數可調),目的是分區數相對於線程數多一點,以均衡各個線程並行執行速度,提升整體響應時間。
數據按冷熱分散存儲在memtable,L0,L1和L2這4層,如果數據量很少,可能沒有L1或者L2,甚至數據在全內存中。我們討論大部分情況下,磁盤都是有數據的,並且memtable中的數據相對於磁盤數據較小,主要以磁盤上數據為分區依據。分區邏輯如下:
1).預估查詢範圍的extent數目
2).根據extent數目與併發線程數比例,預估每個task需要掃描的extent數目
3).對於第一個task,以查詢起始key為start_key,根據每個task要處理的extent數目,以task中最後一個extent的largest_key信息作為end_key
4).對於其它task,以區間內第一個extent的smallest_key作為start_key,最後一個extent的largest_key作為end_key
5).對於最後一個task,以區間內第一個extent的smallest_key作為start_key,以用戶輸入的end_key作為end_key
至此,我們根據配置併發數,將掃描的數據範圍劃分成了若干分區。在某些情況下,數據可能在各個層次可能分佈不均勻,比如寫入遞增的場景,各層的數據完全沒有交集,導致分區不均,因此需要二次拆分,將每個task的粒度拆地更小更均勻。同時,對於重IO的場景(掃描的大部分數據都無法cache命中),X-Engine內部會通過異步IO機制來預讀,將計算和IO並行起來,充分發揮機器IO能力和多核計算能力。
對比InnoDB並行掃描
InnoDB引擎也提供了並行掃描的能力,目前主要支持主索引的count(*)和check table操作,而實際上X-Engine通用性更好,無論是主表,還是二級索引都能支持並行掃描。InnoDB與X-Engine一樣是索引組織表,InnoDB的每個索引是一個B+tree,每個節點是一個固定大小的page(一般為16k),通過LRU緩存機制實現內外存交換,磁盤上空間通過段/簇/頁三級機制管理。InnoDB的更新是原地更新,因此訪問具體某個page時,需要latch保護。X-Engine的每個索引是一個LSM-tree,內存中以skiplist存在;外存中數據包括3層L0,L1和L2,按extent劃分,通過copy-on-write多版本元數據機制索引extent,每次查詢對應的一組extent都是靜態的,因此訪問時,沒有併發衝突,不需要latch保護extent。
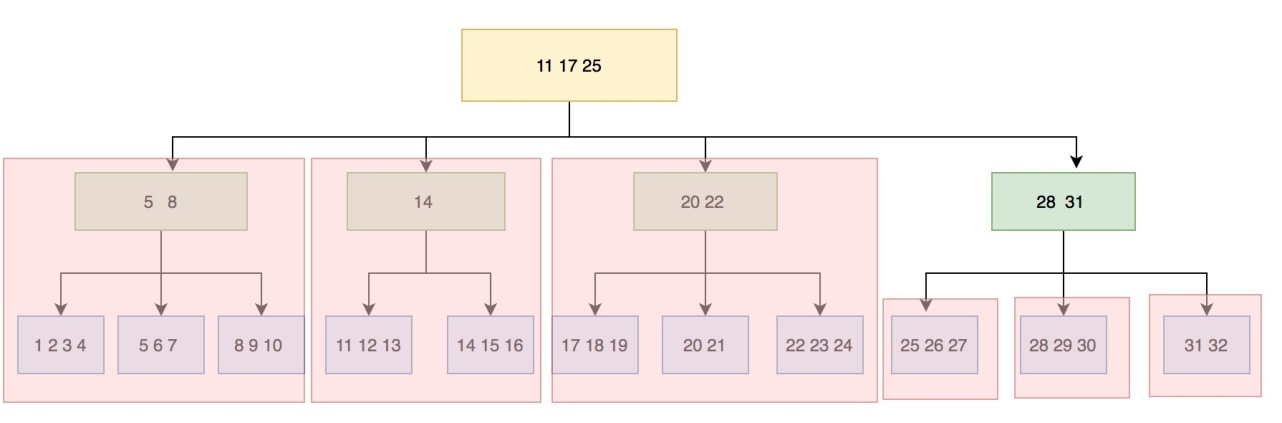
存儲結構差異導致分區和掃描的邏輯也不一樣,InnoDB的分區是基於B+tree物理結構拆分,根據線程數和B+tree的層數來劃分,最小粒度能到block級別。X-Engine的分區分為兩部分,內存中memtable粒度是記錄級;外存中數據是extent級,當然也可以做到block級別。兩者最終的目的都是希望充分利用多核CPU資源來進行掃描。下圖是InnoDB的分區圖。
InnoDB和X-Engine都是通過MVCC機制解決讀不上鎖的問題,進行掃描時需要過濾不可見記錄和已刪除的記錄。InnoDB的delete記錄有delete-mark,多版本記錄存儲在特殊的undo段中,並通過指針與原始記錄建立關聯,事務的可見性通過活躍事務鏈表判斷。X-Engine是追加寫方式更新,沒有undo機制,多版本數據分佈在LSM-tree結構中,delete記錄通過delete-type過濾,事務的可見性通過全局提交版本號判斷。
InnoDB掃描時,根據key搜索B+tree,定位到葉子節點起始點,通過遊標向前遍歷;因此分區後,第一次根據start_key搜索到葉子節點的指定記錄位置,然後繼續往後遍歷直到end_key為止。X-Engine掃描時,會先拿一個事務snapshot,然後再拿一個meta-snapshot(訪問extent的索引),前者用於記錄的可見性判斷,後者用於“鎖定”一組extent,這樣我們有了一個“靜態”的LSM-tree。基於分區的範圍[start_key,end_key],構建堆進行多路歸併,從start_key開始輸出記錄,到end_key截止。
性能測試
通過配置參數xengine_parallel_read_threads來設置併發線程數,就能開始並行掃描功能,默認這個值為4。我這裡做一個簡單的實驗,通過sysbench導入2億條數據,分別配置xengine_parallel_read_threads為1,2,4,8,16,32,64,測試下並行執行的效果。測試語句為select count(*) from sbtest1;
- 測試環境
硬件:96core,768G內存
操作系統:linux centos7
數據庫:MySQL8.0.17
配置:xengine_block_cache_size=200G, innodb_buffer_pool_size=200G
採用純內存測試,所有數據都裝載進內存,主要測試併發效果。
- 測試結果
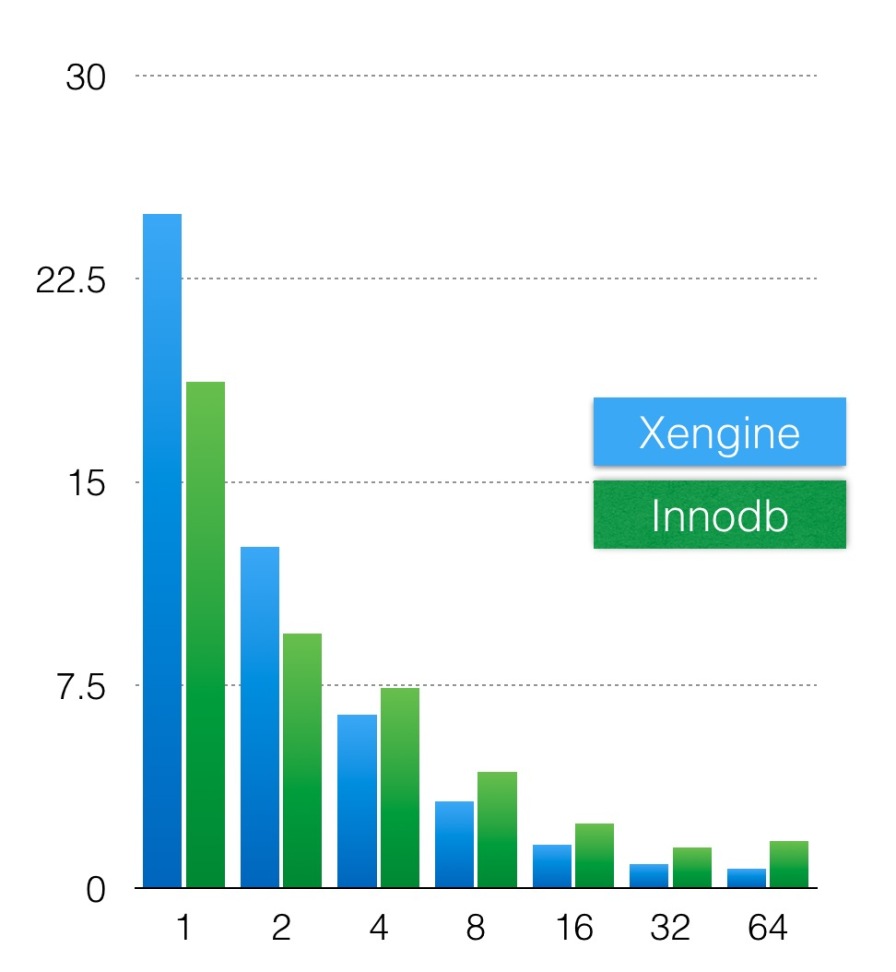
橫軸是配置併發線程數,縱軸是語句執行時間,藍色軸是xengine的執行時間,綠色軸是innodb執行的時間,當配置32個併發時,掃描2億條數據只需要1s左右。
- 結果分析
可以看到X-Engine和Innodb都具有較好的併發掃描能力,X-Engine表現地更好,尤其是在16線程以後,InnoDB隨著線程數上升,執行時間並沒有顯著下降。這個主要原因是InnoDB的並行是基於物理Btree的拆分,而X-Engine的並行是基於邏輯key的拆分,因此拆分更均勻,基本能隨著線程數增加,響應時間成倍地減少。
總結與展望
目前X-Engine的並行掃描還只支持簡單count(*)操作,但已經顯示出了充分利用CPU多核的能力。我們將繼續向上改造執行器接口,以支持更多的並行操作。無論是RDS(X-Engine)還是我們的分佈式產品PolarDB-X都將在X-Engine的基礎上,讓單條SQL跑地更快。